 夜雨聆风
夜雨聆风研究AIOps已有数月,目前手里有不少可落地的方案了,接下来会把这些方案全部整理到我的大模型课程里。欢迎大家把你遇到的场景在评论区留言。我会在能力范围内给你提供思路和建议。
最近有个同学问我:阿铭老师我们公司业务量特别小,还不到10台服务器,平时我的运维工作也不多,甚至不饱和,那有没有必要做AIOps?我当时没有直接给出答案,而是做了一些思考,今天我把这些思考整理出来给有类似疑问的同学做个参考。
先给结论:AIOps要做,但不该做“平台型AIOps”,而要做“问题导向的轻量 AIOps(比如运维智能体,那种可以借助LLM明显提效的Agent)”。
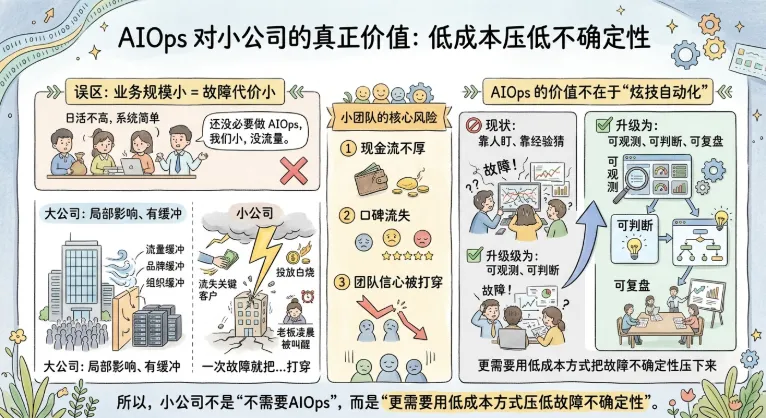
小公司最怕的不是流量不大,而是一次故障就把本就不厚的现金流、口碑和团队信心打穿。AIOps对小公司的价值,不在“炫技自动化”,在于把故障处理从“靠人盯、靠经验猜”,升级为“可观测、可判断、可复盘”。
很多朋友把这个问题想反了。
他们会说:“我们日活不高,系统也不复杂,先不做AIOps,因为根本就没必要。”
这句话听起来理性,实际上混淆了两个概念:业务规模小 ≠ 故障代价小。
对大公司来说,一次抖动是“局部影响”。而对小公司来说,一次抖动可能是“关键客户流失、投放白烧、老板凌晨被叫醒”。你没有流量缓冲、没有品牌缓冲、也没有组织缓冲,这才是小团队真正的风险结构。
所以,小公司不是“不需要AIOps”,而是更需要用低成本方式,把故障不确定性压下来。
为什么“人少系统少”,反而更该做AIOps?
先看小公司的真实运维现场: 一个后端兼SRE,一个前端偶尔查日志,一个产品在群里追问“到底什么时候恢复”。 这不是能力问题,这是组织现实。
在这种现实下,传统运维有三个天然短板:
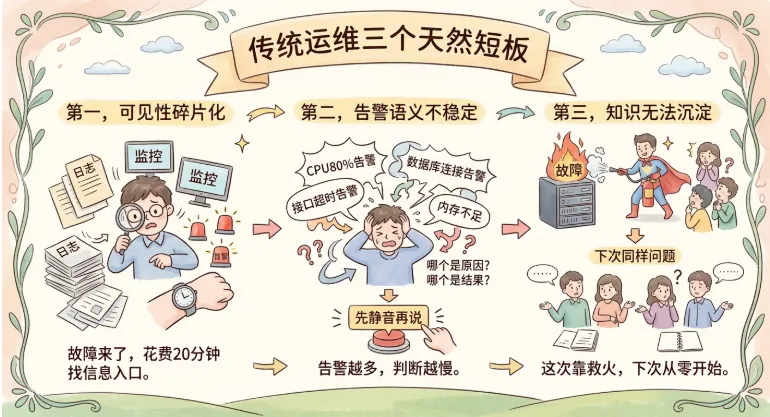
第一,可见性碎片化。 日志在一处、监控在一处、告警在另一处。故障来了,先花20分钟“找信息入口”。
第二,告警语义不稳定。 CPU80%告警、接口超时告警、数据库连接告警一起响,但没人知道哪个是原因、哪个是结果。告警越多,判断越慢,最后变成“先静音再说”。
第三,知识无法沉淀。 这次故障靠某个同学临场救火解决了,下次同样问题再来,团队还是从零开始。
AIOps真正补的是这三个洞: 不是替代工程师,而是让工程师在高压时刻少走弯路。
行业变化已经很明确:AIOps正在从“系统工程”变成“能力组件”
过去提AIOps,默认是“大厂平台化工程”:统一采集、海量建模、复杂规则引擎。小公司听完只会得出一个结论:做不起。
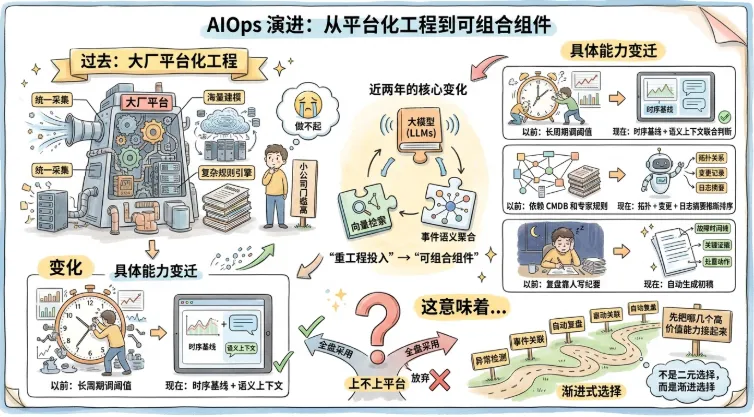
但这两年变化很大。大模型、向量检索、事件语义聚合,把很多“以前必须重工程投入”的能力,变成了“可组合组件”:
以前做异常检测,常常要长周期调阈值,现在可以用时序基线 + 语义上下文做联合判断。
以前做事件关联,依赖重CMDB和专家规则,现在可以把拓扑关系、变更记录、日志摘要一起做推断排序。
以前复盘靠人写纪要,现在可以自动生成“故障时间线 + 关键证据 + 处置动作”的初稿。
这意味着一件事:AIOps不再是“上不上平台”的二元选择,而是“先把哪几个高价值能力接起来”的渐进选择。
更适合小公司的AIOps能力建设:轻、准、可复用
如果把能力建设抽象成优先级,小公司更该先抓这几件事:
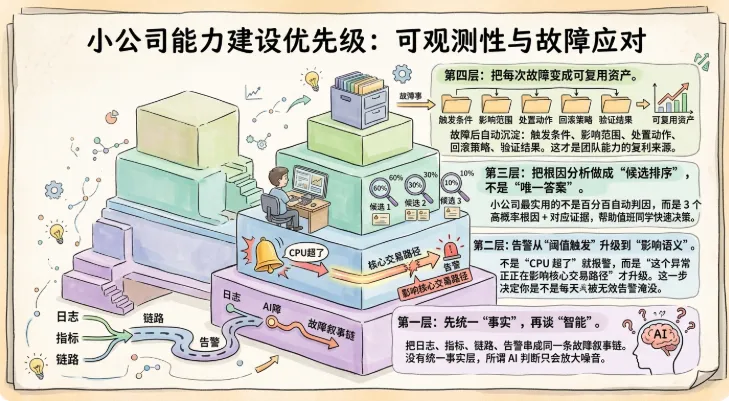
第一层:先统一“事实”,再谈“智能”。把日志、指标、链路、告警串成同一条故障叙事链。没有统一事实层,所谓 AI 判断只会放大噪音。
第二层:告警从“阈值触发”升级到“影响语义”。不是“CPU 超了”就报警,而是“这个异常正在影响核心交易路径”才升级。这一步决定你是不是每天被无效告警淹没。
第三层:把根因分析做成“候选排序”,不是“唯一答案”。小公司最实用的不是百分百自动判因,而是 3 个高概率根因 + 对应证据,帮助值班同学快速决策。
第四层:把每次故障变成可复用资产。故障后自动沉淀:触发条件、影响范围、处置动作、回滚策略、验证结果。这才是团队能力的复利来源。
你会发现,这套路径并不重,但非常工程化。它追求的不是“智能炫技”,而是“组织抗故障能力”。
小公司做AIOps,不是为了像大厂,而是为了活得更稳
回到最初问题,小公司有必要做AIOps,而且越早做“轻量正确版”,越能避免后期用高成本补作业。
AIOps在小公司里的价值,不是把系统做复杂,而是把故障处理做确定。不是追求全自动,而是让关键环节可观测、可判断、可复用。
本质上,这是一种工程化能力建设。在不确定的业务周期里,用更低的运维波动,换更高的组织稳定性。对小公司来说,这不是“锦上添花”,而是“活下去并活得更好”的基础设施。
如果你有不同的意见,可以留言区讨论下!
顺便介绍下我的大模型课:我的运维大模型课上线了,目前还在预售期,有很大优惠。AI越来越成熟了,大模型技术需求量也越来越多了,至少我觉得这个方向要比传统的后端开发、前端开发、测试、运维等方向的机会更大,而且一点都不卷!
扫码咨询优惠(粉丝优惠力度大)

