夜雨聆风
夜雨聆风大多数 AI 记忆是被动的。Active Memory 在回复前先搜记忆再注入上下文,让 AI 真正记住你的偏好和历史。
我是 AI灵感闪现,使用 OpenClaw 小龙虾 让 AI 自主管理工作和生活上的问题;使用 Claude Code + BMAD AI 驱动敏捷开发框架,让 AI 自主开发和交付软件来表达想法和灵感。是 MoneyMind 省钱思维 App 和 HeartPetBond 心宠纽带 App 开发者。正在实践和分享让 AI 自主解决健康、生活、投资和等方面的问题。我尽可能让 AI 自己完成从目标到交付以及演进的闭环,以最少的人为交互与监督,让 AI 自己跑流程。我只给 AI 想法或目标,全程不陪跑,让 AI 自主运行类似 Tesla FSD 自动驾驶。
解决什么问题
大多数 AI 记忆系统是被动的——要么等用户说"记住这个",要么靠主模型自己决定"该搜搜记忆了"。问题是:等模型意识到该搜记忆的时候,最佳时机已经过了。
举个例子:
你说"今晚吃什么",AI 不知道你上周说过讨厌香菜,给你推荐了香菜沙拉 你问"帮我订机票",AI 不知道你偏好靠窗座位、东航会员 你说"周末安排",AI 不知道你每周六固定打羽毛球
这些信息都存在记忆里,但主模型在生成回复时根本没去查。
Active Memory 的解法很直接:在主回复生成之前,插入一个轻量记忆子代理,先搜一遍相关记忆,把结果注入上下文,再让主模型回复。
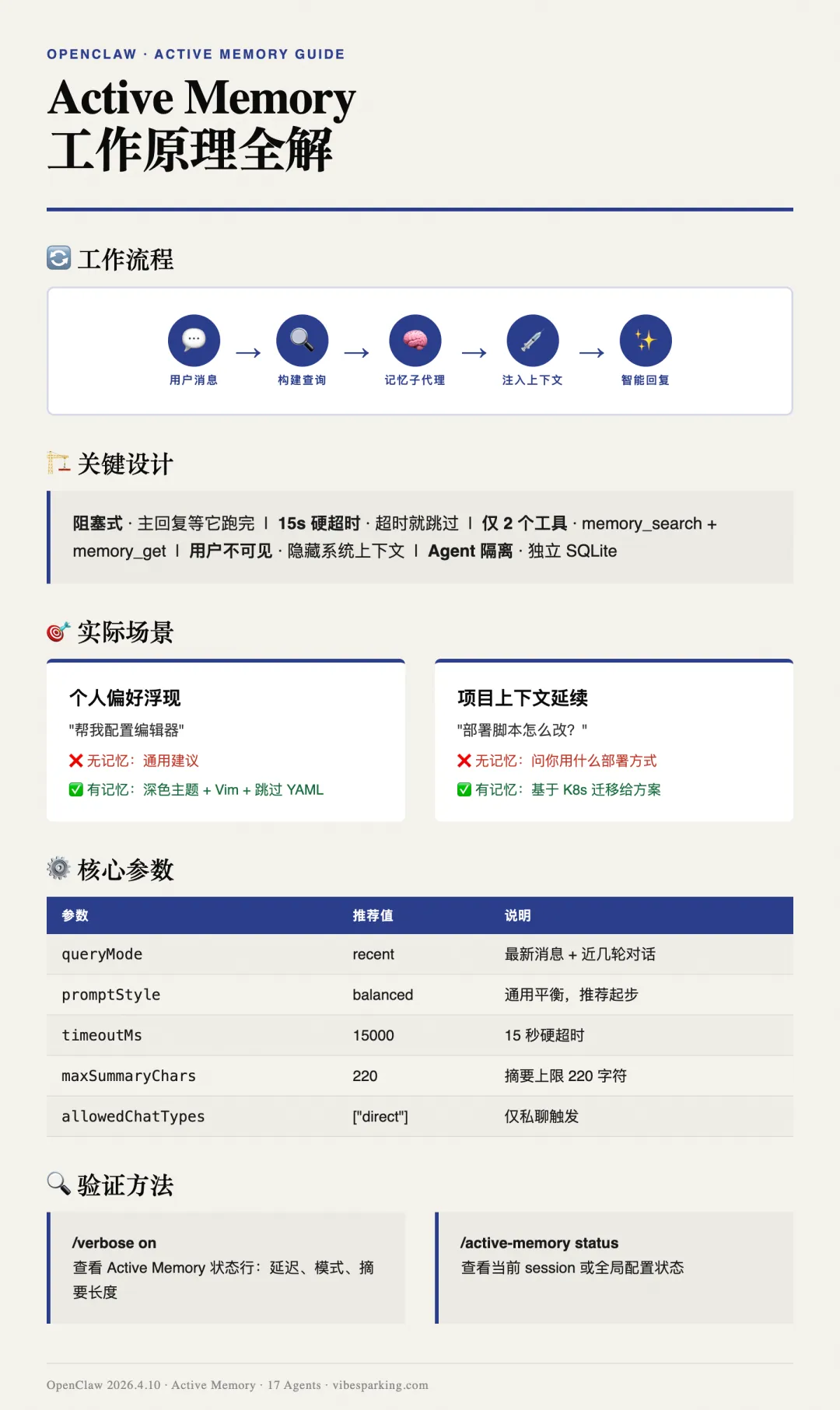
工作原理
用户消息 → 构建记忆查询 → 阻塞式记忆子代理(memory_search / memory_get) ↓ 有相关记忆? / \ 是 否 ↓ ↓ 注入隐藏上下文 什么都不加 ↓ ↓ 主模型生成回复关键设计:
阻塞式——主回复等它跑完才开始,不是异步的 有硬超时——默认 15 秒,超时就跳过,不会卡死 子代理只能用两个工具—— memory_search和memory_get,不会乱跑结果对用户不可见——注入的是隐藏系统上下文,用户看到的只是更聪明的回复 记忆按 agent 隔离——每个 agent 有独立的 SQLite 数据库,不会串
实际使用场景
场景一:个人偏好自动浮现
用户之前聊过"我喜欢深色主题"、"我用 Vim 键位"、"我讨厌 YAML"。
现在用户说:"帮我配置一下编辑器。"
没有 Active Memory:AI 给出通用配置建议。 有 Active Memory:子代理搜到偏好,主模型直接给出深色主题 + Vim 键位的配置,跳过 YAML 格式。
场景二:长期项目上下文
用户上周讨论过"我们在把服务从 Docker Compose 迁移到 K8s"。
今天用户说:"部署脚本怎么改?"
没有 Active Memory:AI 不知道迁移背景,可能问"你用的什么部署方式?" 有 Active Memory:子代理搜到迁移上下文,主模型直接基于 K8s 迁移给出方案。
场景三:多 agent 集群中的个性化
我们有 17 个 agent,每个负责不同领域(开发、运维、QA、产品等)。Active Memory 让每个 agent 都能记住与自己领域相关的用户偏好和历史决策,而不是每次都从零开始。
配置方法
在 openclaw.json 的 plugins.entries 中添加:
{"active-memory":{"enabled":true,"config":{"enabled":true,"agents":["main","其他agent-id"],"allowedChatTypes":["direct"],"modelFallbackPolicy":"default-remote","queryMode":"recent","promptStyle":"balanced","timeoutMs":15000,"maxSummaryChars":220,"persistTranscripts":false,"logging":true}}}核心参数说明
queryMode — 子代理能看到多少对话:
message | |||
recent | 推荐起步 | ||
full |
promptStyle — 子代理多积极地返回记忆:
balanced:通用默认,推荐起步strict:保守,宁可不返回recall-heavy:积极召回,软匹配也返回precision-heavy:极度保守,只返回明确匹配preference-only:专攻偏好、习惯、口味contextual:重视对话连续性
allowedChatTypes — 哪些聊天类型开启:
direct:私聊(推荐默认)group:群聊channel:频道
如何验证
方法一:/verbose on
在任意对话 session 中输入 /verbose on,之后每条回复会附带 Active Memory 状态行:
🧩 Active Memory: ok 842ms recent 34 chars🔎 Active Memory Debug: 用户偏好深色主题,讨厌 YAML。ok= 正常运行842ms= 子代理耗时recent= 使用的查询模式34 chars= 注入的摘要长度
方法二:/active-memory status
查看当前 session 的 Active Memory 状态:
/active-memory status # 当前 session/active-memory status --global # 全局配置状态方法三:Gateway 日志
开启 logging: true 后,在 gateway 日志中可以看到每次 Active Memory 的运行详情:
# 查看实时日志tail -f ~/.openclaw/logs/gateway.log | grep -i "active.memory"方法四:Memory 状态检查
确认底层记忆系统正常:
openclaw memory status --deep方法五:手动对比测试
先存一条记忆(在对话中提到某个偏好) 开新 session, /verbose on提一个相关但不直接的问题 观察 Active Memory Debug 行是否召回了那条记忆
调优建议
记忆太吵:降低 maxSummaryChars,或换strict/precision-heavy风格太慢:降级 queryMode到message,缩短timeoutMs没有召回:确认 openclaw memory status --deep正常,确认 agent id 在列表中调试需要:临时开启 persistTranscripts: true保留子代理 transcript,但注意会积累文件
我们的部署
实例:本机(OpenClaw 2026.4.10) 开启范围:全部 17 个 agent 记忆隔离:每个 agent 独立 SQLite 数据库,互不干扰
完整配置
{"active-memory":{"enabled":true,"config":{"enabled":true,"agents":["vs","vs-apexdata","vs-dev","vs-ops-mgr","vs-park-service","vs-po","vs-qa","vs-yude","careinner-all","claude","main","test","vibesparking","vs-claude","vs-openclaw-mgr","vs-sites-astro","vs-wechat"],"allowedChatTypes":["direct"],"modelFallbackPolicy":"default-remote","queryMode":"recent","promptStyle":"balanced","timeoutMs":15000,"maxSummaryChars":220,"persistTranscripts":false,"logging":true}}}配置要点
agents | ||
allowedChatTypes | direct | |
queryMode | recent | |
promptStyle | balanced | |
timeoutMs | 15000 | |
maxSummaryChars | 220 | |
modelFallbackPolicy | default-remote | |
persistTranscripts | false | |
logging | true |


全网首发?第一款 GLM 4.7 + Claude Code AI 自主开发的心宠纽带 App 首次通过 App Store 审核并上架发布
智谱 GLM 4.7 模型 AI 自主开发 HeartBetBond 心宠纽带 App,从想法到提交 App Store 仅用 12 天
实战测评:用 Claude Code + BMAD + GLM-4.7 打造 HeartPetBond App (心宠纽带)
加入 AI灵感闪现 微信群
长按下图二维码进入 AI灵感闪现 微信群

长按下图二维码添加微信好友 VibeSparking 加群

关注 AI灵感闪现 微信公众号