 夜雨聆风
夜雨聆风引言:本地大模型时代的“显存焦虑”
2024年到2025年,AI 领域发生了一场悄无声息的“权力转移”。随着 Llama 3、DeepSeek、Gemma 等开源模型的性能跨越式增长,越来越多的开发者和极客开始放弃昂贵的 API 订阅,转向本地部署(Local LLM)。
本地部署的诱惑是巨大的:隐私安全、无需联网、没有审查限制、一次购买硬件终身免费使用。 然而,现实往往是骨感的。当你满心欢喜地从 Hugging Face 拖回一个几十 GB 的权重文件,配置好环境点击运行,迎接你的往往不是智慧的火花,而是屏幕上冷冰冰的一行报错:torch.cuda.OutOfMemoryError: CUDA out of memory.
在大模型领域,显存(VRAM)就是入场券。参数量多大、量化精度多高、上下文长度设为多少,这些都受到硬件的严格物理约束。
那么问题来了:在下载之前,我怎么知道我的电脑能不能跑?能跑多快?是用 CPU 跑还是 GPU 跑?今天,我们要深度拆解两款能够救你于水火的神器:极客必备的 llmfit 和小白友好的 canirun.ai。
第一章:llmfit——大模型时代的“硬件精算师”
llmfit 是一个近期在 GitHub 上备受推崇的开源项目。它使用 Rust 编写,主打高性能和极致的精准度。如果说普通工具只是“估算”,那么 llmfit 就是在为你的硬件做“压力模拟”。
1.1 核心逻辑:为什么它比别人准?
很多简单的在线表格只会告诉你:“8B 模型需要 8GB 显存”。这其实是极其不专业的。
llmfit 的计算公式考虑了以下变量:
• 模型参数(Params): 模型的基础大小。 • 量化位宽(Quantization): 是 4-bit、8-bit 还是 FP16? • KV 缓存(KV Cache): 随着对话变长,显存占用会激增。 • 运行后端(Backend): 使用 llama.cpp(CPU/GPU混合)还是显卡直驱?
1.2 详细操作过程:保姆级上手指南
第一步:环境准备与安装
llmfit 几乎不依赖复杂的 Python 环境,因为它被编译成了二进制文件。
• Linux/macOS 用户:打开终端,输入以下一键安装脚本: curl -sSL https://raw.githubusercontent.com/AlexsJones/llmfit/main/install.sh | sh• Windows 用户:建议前往 GitHub Release 页面下载 .exe文件,或者使用cargo install llmfit。
第二步:启动交互式体检
在终端输入 llmfit 后,你会进入一个基于文本的图形界面(TUI)。它会立即扫描你的系统:
• CPU: 识别核心数和指令集(是否支持 AVX512 等加速)。 • RAM: 系统物理内存总量。 • GPU: 识别 CUDA 核心数或 Apple M 系列的统一内存。
第三步:模型筛选与“虚拟配机”
界面中会列出当前主流的模型(Llama 3.1, Phi-3, Mistral 等)。你可以通过上下键切换,右侧会实时更新:
• Fit Score: 100% 代表完美运行,低于 50% 代表会极其卡顿。 • Estimated Speed: 它会给出一个预估的 Token/s(每秒出字速度)。
神级功能:S 键模拟模式这是 llmfit 最硬核的功能。假设你现在只有 8G 显存,但你想知道如果买了 RTX 5090 之后能不能跑起 Llama-3-70B。你只需按 S,输入虚拟显存大小,它就能穿越时空告诉你答案。
第二章:深度提炼——llmfit 的三大精华亮点
2.1 智能量化感知
大模型之所以能跑在电脑上,全靠“量化”技术。llmfit 深入理解 GGUF 格式的各种量化级别(Q2_K, Q4_K_M, Q8_0)。它会根据你的显存剩余量,自动为你计算出那个“既不浪费显存,又能保持最高智商”的平衡点。
2.2 多后端联动
它不仅仅是一个查看器。llmfit 与 Ollama 深度集成。当你在界面上选中一个满意的模型后,可以直接触发下载和运行命令。这种从“评估”到“落地”的一站式体验,极大简化了流程。
2.3 内存压力测试预测
很多模型在刚启动时占用很小,但当你输入 2000 字的长文后,显存会瞬间爆表。llmfit 允许你手动调节 Context Window(上下文窗口) 参数,它会预判在高负载下硬件的承受能力,防止你在工作到一半时模型崩溃。
第三章:视觉直观——llmfit 工作原理图解
由于许多用户处于无 GPU 环境,我们通过文字逻辑图来展示其内部运作机制:
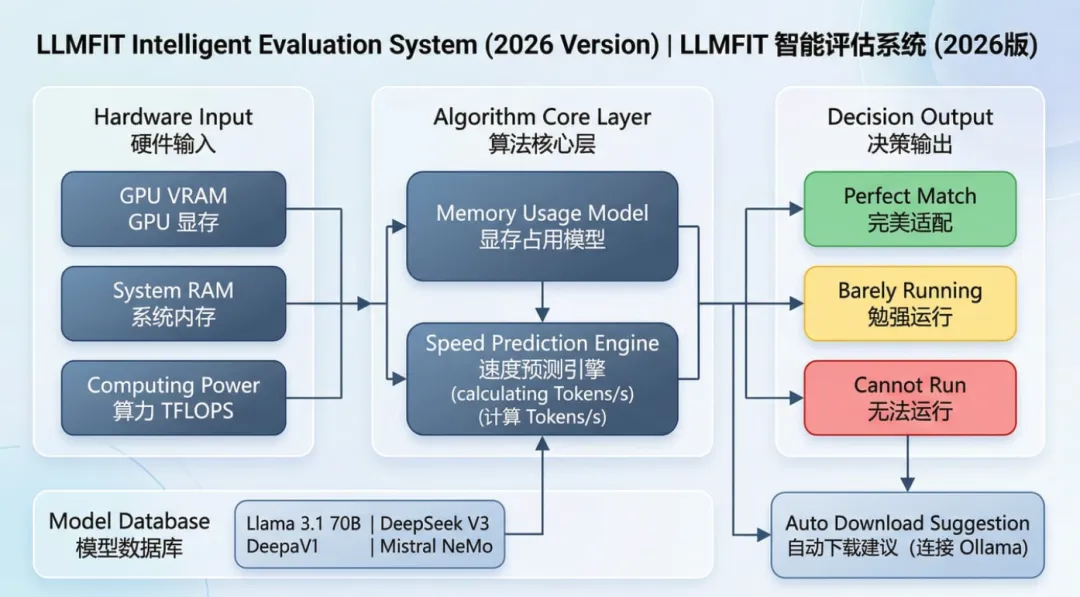
第四章:canirun.ai——小白的一键式“云诊断”
如果说 llmfit 是专业修车工手里的解码器,那么 canirun.ai 就是保险公司的在线估价单。
4.1 网页版的直观优势
你不需要懂任何 Git 命令,甚至不需要打开终端。
1. 访问网页: 界面极其简洁。 2. 选择配置: 它可以自动识别你的浏览器环境,或者由你从下拉菜单选择 GPU(从远古的 GTX 1060 到最新的 H200 都有)。 3. 结果可视化: 它会给出一张类似“游戏配置要求表”的清单,清晰地标明: • Minimum: 最低能跑的量化版本。 • Recommended: 推荐的体验版本。 • Ultra: 无损运行的需求。
4.2 为什么推荐配合使用?
• 购买决策参考: 在你双十一打算买显卡前,先去 canirun.ai 测一下。 • 分享性: 它可以生成一个配置链接,你可以发给朋友:“看,我的机器能跑 DeepSeek!”
第五章:应用案例实战分析
为了让大家更有代入感,我们模拟了三个典型配置的测试结果:
案例一:轻薄本/网课机(8G RAM, 集成显卡)
• 诊断结果: 运行 7B 以上模型几乎不可能。 • llmfit 建议: 寻找 Qwen-1.8B 或 Phi-3-mini 的 4-bit 量化版。 • 体验: 速度约 5-8 tokens/s,可以胜任简单的代码查错或润色工作。
案例二:主流游戏本(RTX 4060 8G 显存 + 16G RAM)
• 诊断结果: 显存刚好够跑 Llama-3-8B 的 Q8 版本。 • llmfit 建议: 为了留出 Context 空间,建议使用 Q6_K 量化,并在 Ollama 中限制上下文为 4096。 • 体验: 非常流畅,响应时间在毫秒级。
案例三:生产力怪兽(Mac Studio M2 Ultra 128G)
• 诊断结果: 降维打击。 • llmfit 建议: 毫不犹豫运行 Llama-3-70B 甚至更强大的模型。 • 体验: 由于统一内存架构,它可以调动超过 100G 的显存,是目前本地跑大模型的终极解法。
第六章:深度避坑指南——你必须知道的硬件潜规则
在阅读完工具反馈后,你还需要掌握几个“冷知识”,以免被数据蒙蔽:
1. 显存速度 ≠ 内存速度: 即使你的电脑有 64G 内存,但如果用 CPU 跑,速度可能只有 1-2 tokens/s;而只有 12G 的显存跑,速度能达到 50 tokens/s。核心原因在于带宽(Bandwidth)。 2. 统一内存的优势: Mac 的 M 系列芯片为什么强?因为它的内存和显存是合二为一的,这打破了普通 PC 显存容量的上限。 3. 量化的代价: Q4(4位量化)通常是性能与智力的甜点位。如果降到 Q2,模型可能会开始胡言乱语。
第七章:总结与未来展望
AI 的民主化正在加速。曾经需要数万美元服务器才能运行的智慧,现在正逐渐被塞进我们的书包。
llmfit 和 canirun.ai 的出现,标志着大模型部署从“玄学阶段”进入了“工程化阶段”。它们不仅是工具,更是我们探索本地 AI 世界的地图。
给读者的建议:如果你是技术流,请务必在你的 GitHub 收藏夹里给 llmfit 留一个位置。如果你只是想快速知道自己的旧电脑还有没有救,canirun.ai 是你的首选。
不要让你的显卡只用来玩 3A 大作,给它一个机会,让它成为你私人的“最强大脑”。
