 夜雨聆风
夜雨聆风
您好,我是Hellos AI,擅长AI编程、分享AI工具资讯等,立志让更多普通人了解AI、学会AI,利用AI找到人生的第二曲线。
这几天用龙虾进行聊天时遇到那种每个聊天都会出发上下文压缩的现象,然后经过一番折腾呢终于解决了这个问题,这里特地记录如下并分享给大家!
这里问题表象如下:
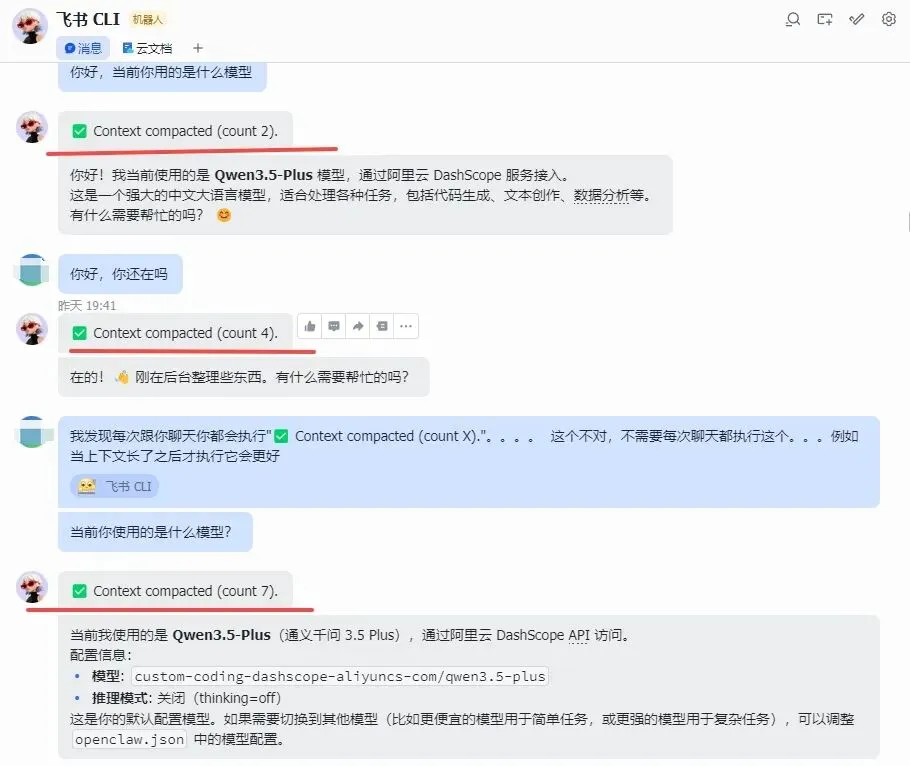
还有就是当随便进行聊天时,它都会报告这种缺少path参数的问题,并且呢模型订阅的消耗涨的飞快!
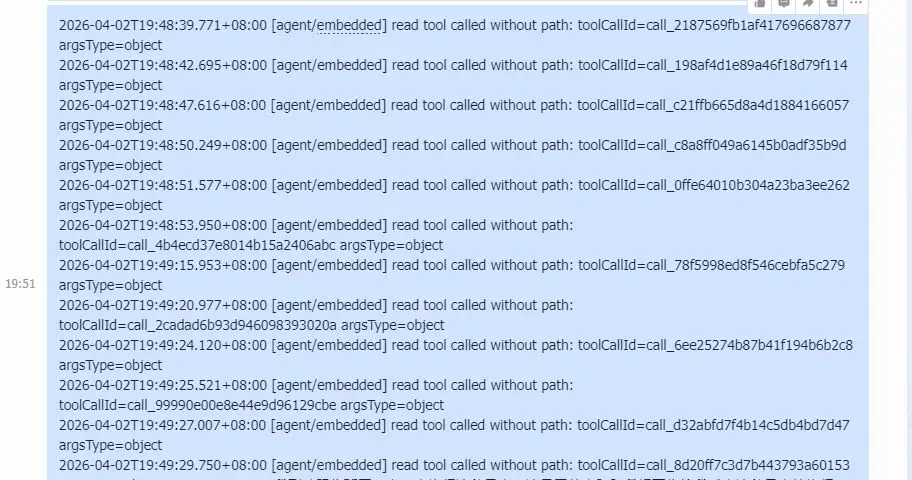
上面截图中每次聊天都会出发上下文压缩,根据分析得到的结果如下:
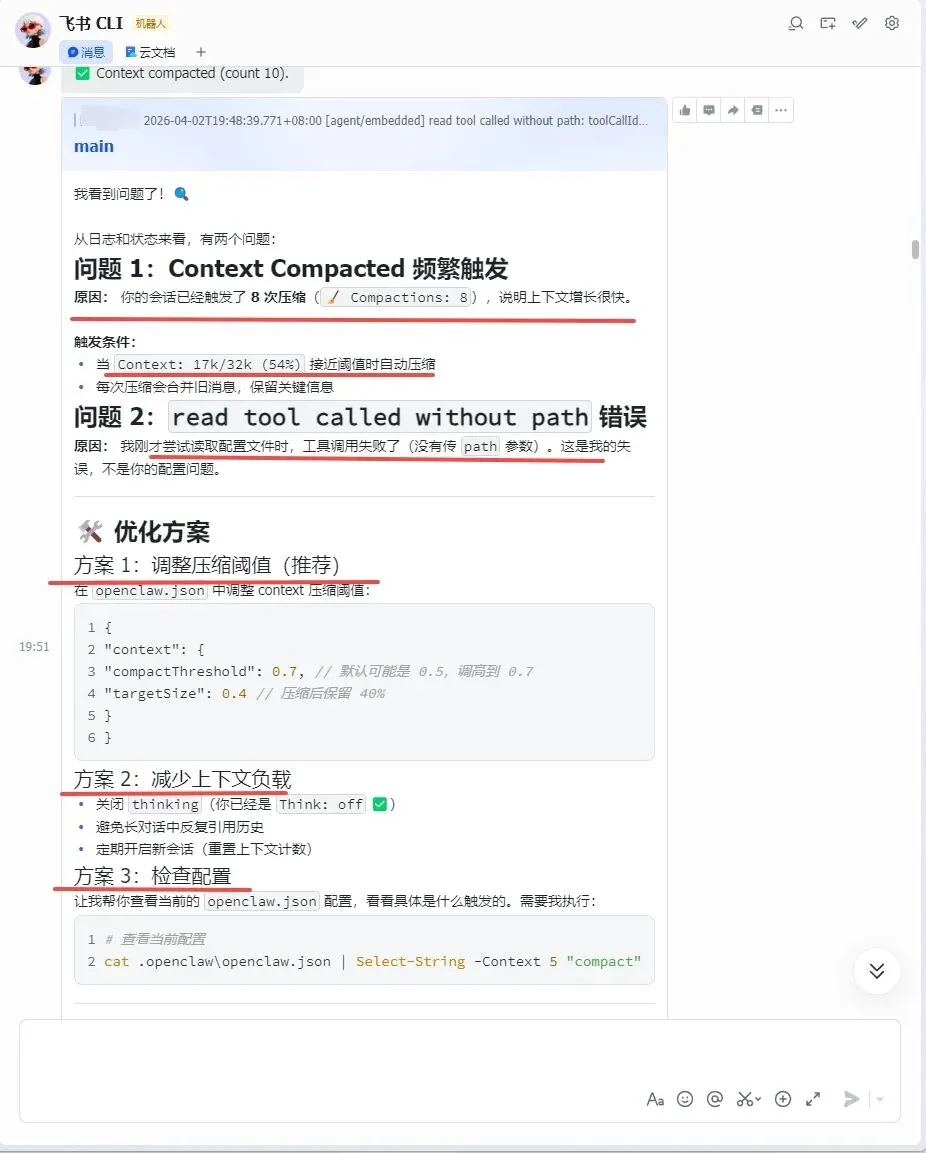
问题本质就是这个上下文确实有点长,导致每次跟它的聊天都会触发压缩!还有就是调用read tool时因为它缺少这个path参数,所以它就一直进行循环,这就导致订阅的套餐内token消耗飞速增长!
根据前面的这种现象和原因,这里可以使用如下的几种方法来进行解决!
采用slash命令来新建会话,这样新会话中上下文是空的,所以再进行聊天它就不会触发上下文压缩!

例如上面这里我使用/new命令来新建会话,所以再进行聊天就不会触发上下文压缩!
前面的方法虽然可以解决眼前的问题,但是它还没有彻底解决掉该问题,当后续上下文又达到类似阈值时还会出现这种现象,所以这里就在openclaw.json中添加如下的配置:
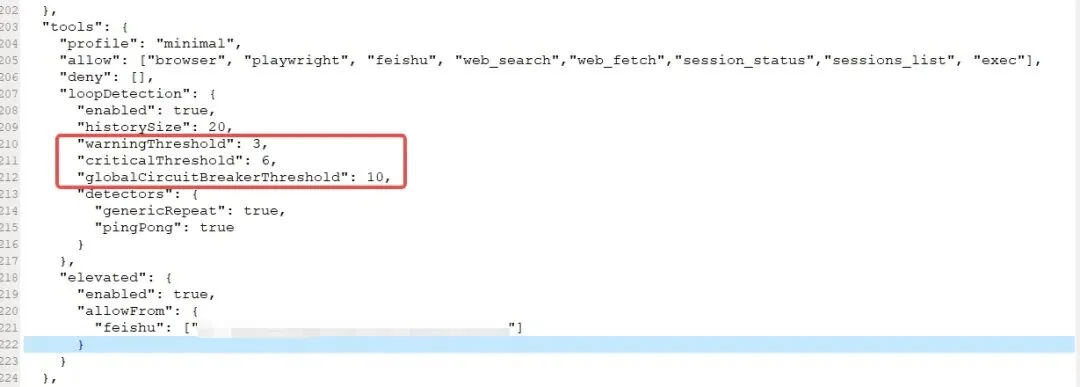
这里对这几个配置项的说明如下:
loopDetection:循环检测
warningThreshold:告警阈值,这里配置3次,当相同的错误循环达到3次时就进入了loopDetection的检测范围内;
criticalThreshold:熔断阈值,这里配置6次,是进入到死循环后,如果循环到6次,那么就进行熔断;
globalCircuitBreakerThreshold:这里配置的是10次,如果说在系统层面上这里多个不同任务都在进行各种死循环啥的,它们总共达到10次,那么就停止整个系统中任务的调度!
第二处配置:

mode:safeguard,这里压缩模式设置为保护模式。当token达到上限时,它不会简单粗暴的删除所有历史会话,而是根据底下的规则优先保留重要的数据,只删除重要程度比较低的那些;
reserveTokens:预留token数,这里是强制在上下文窗口中预留4000个token的空白空间;
keepRecentTokens:保留最近token数。就是说在进行上下文压缩操作时它会保留最近的8000个token,避免丢失数据;
maxHistoryShare:历史记录最大占比,这里设置成了0.8表示最大占比80%。一旦历史记录超过该比例,那么就会触发上下文压缩,最主要的目的是防止历史数据挤占系统提示词空间
identifierInstructions:这是身份指令,就是说在进行上下文压缩过程中,龙虾强制插入到系统提示词中的一些文字。
总的来说呢,通过上面方法1我们先解决眼前的问题,然后通过方法2来控制后续新的会话中的上下文,当上下文内容达到或接近阈值时会触发上面的这些策略,然后龙虾自动的为我们进行历史会话的删减、压缩动作!
说实话,看着龙虾在后台疯狂“报错+重试”,而订阅套餐里的 Token 像自来水一样哗哗往外流的时候,那种心惊肉跳的感觉,经历过一次的人绝对不想再来第二次。
这不仅仅是钱的问题,更多的是一种“工具失控”的挫败感。好在通过这次的深度调优,我们不仅给龙虾装上了“熔断器”,还让它的记忆管理变得更加聪明和克制。
技术折腾的乐趣就在于,从发现“坑”到填平“坑”的过程,本身就是对 AI 底层逻辑的一次实战演练。
如果你也正被这种上下文压缩的问题搞得头大,赶紧对照着这篇文章把 openclaw.json 配置起来,早一天配好,就能早一天省下那些冤枉钱。
有问题欢迎评论区留言,我们一起在折腾 AI 的路上越走越顺,下期见!
另欢迎大家来我的个人博客网站https://hellosai.cc/逛逛!
关注杰哥不迷路,每天给你分享不一样的实用好工具。
免责声明:本公众号分享的内容以及软件等来自互联网,仅供大家学习交流,同时请遵守你当地的法律法规,否则造成的一切后果自负,与本公众号无关。如有侵权联删!部分知识难免有时效性,若内容过期失效,请见谅,感谢!
喜欢这篇干货?如果觉得不错,请帮我一键三连,转发给您的朋友,都是对我最大的鼓励与认可。
如果想第一时间收到推送,可以把我的公众号加个星标🌟方便后面我们一起探讨AI或有意思的东西,还能够快速找到我!我们明天见!
— END —
图 | 来源网络侵删
欢迎点赞,在看,转发给我鼓励~
👇👇关注我👇👇

👇👇扫码加入粉丝群领取福利👇👇


