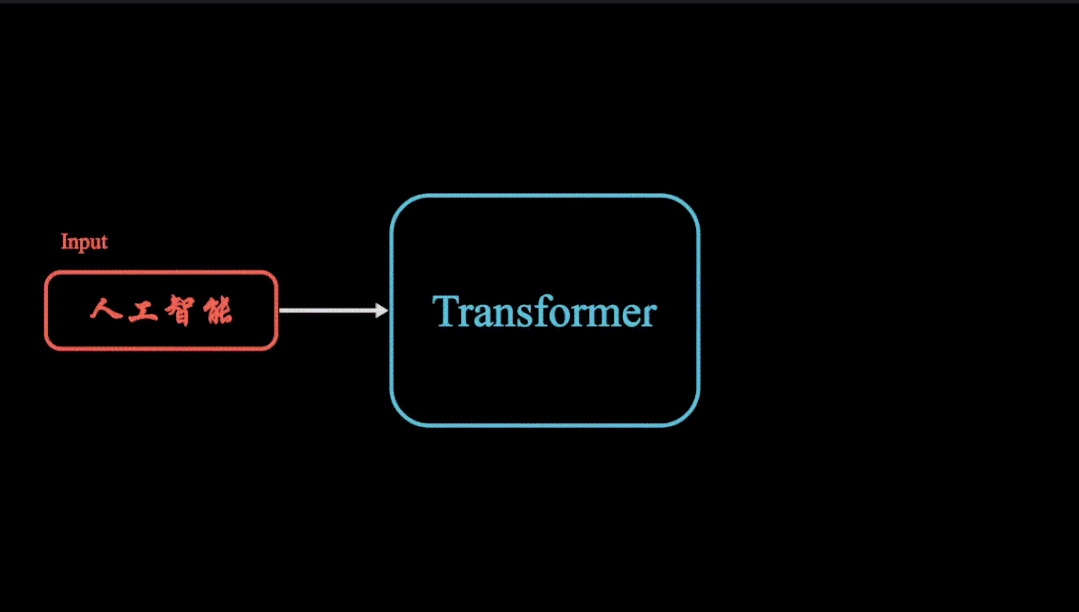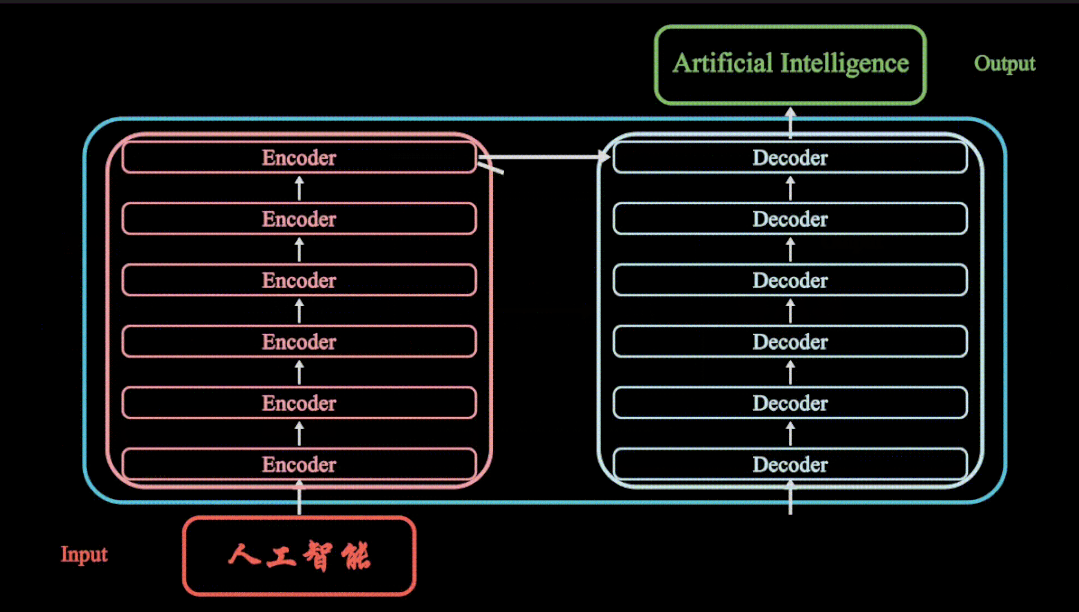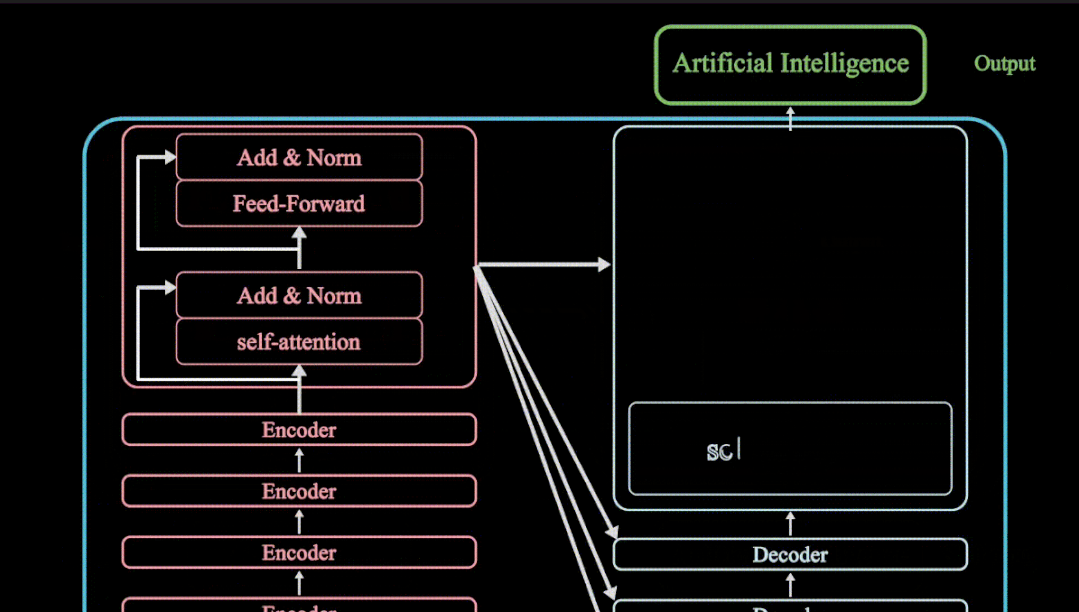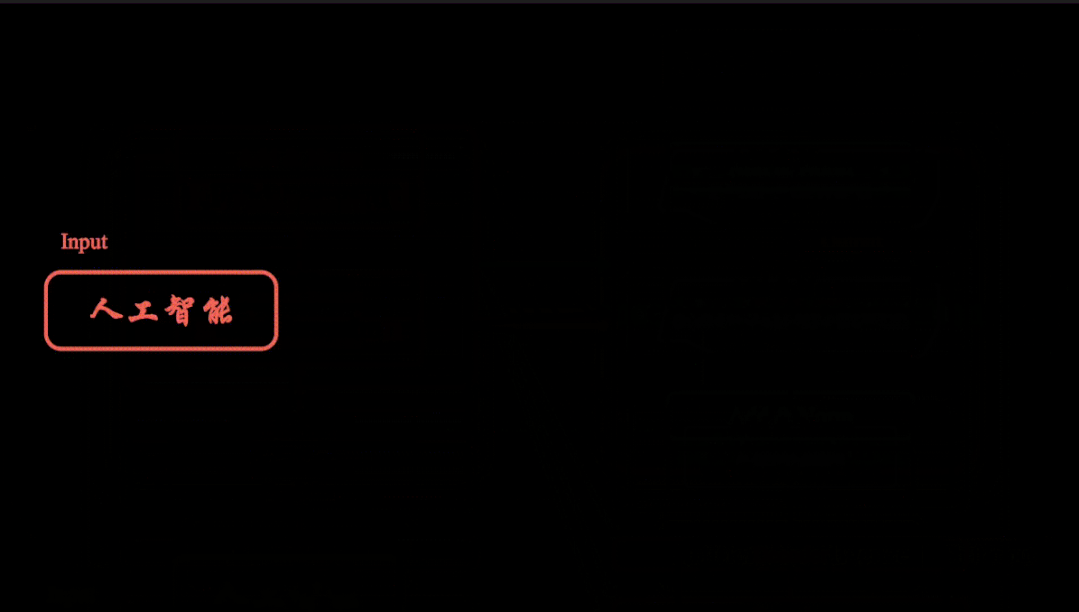
夜雨聆风
夜雨聆风在人工智能爆炸式发展的今天,无论是在背后默默提供预测的线性回归系统,还是为你写代码、作画的复杂生成式 AI,“模型训练(Model Training)”都是它们生命周期中最核心、最具决定性的一步。
那么,究竟什么是模型训练?它是如何工作的?今天,我们就来扒一扒 AI“炼丹”背后的硬核逻辑。

1. 什么是模型训练?“学习”的本质是什么?
简单来说,模型训练就是用相关数据集“教导”机器学习模型,以优化其性能的过程。如果训练数据与模型未来要面对的真实世界高度相似,模型就能精准捕捉其中的模式和相关性,对新数据做出准确预测。
在机器学习(ML)中,训练就是“学习”的过程。这种学习的本质,是调整算法数学函数中的参数(包括权重和偏差)。这些权重和偏差的最终数值,就是模型“知识”的有形体现。
从数学视角来看:
- 减小损失(Loss):
训练的目的是最小化“损失函数”,即量化模型输出误差的指标。当误差低于预定阈值时,模型就被视为“训练完毕”。 - 最大化奖励(Reward):
在强化学习等特定场景中,目标则相反,是最大化“奖励函数”。
在实践中,这是一个不断迭代的周期:
收集数据
运行模型
衡量损失
优化参数
验证性能,直到结果令人满意。此外,这个过程还需要调整
超参数
(影响学习过程但本身不可学习的结构选择,如学习率)。

进阶概念:预训练与微调(迁移学习)
当一个模型从头开始完成训练后,我们还能用新数据对其进行微调(Fine-tuning),使其适应更具体的领域。为了区分,最初的从头训练通常被称为预训练(Pre-training)。微调是迁移学习的一种,即将预训练模型适应新用途的总称。
辨析:模型(Model) vs 算法(Algorithm)
这两个词常被混用,但其实大有不同:
- 算法:
是数学逻辑或伪代码,是做决策的“配方”。 - 模型:
是算法在特定数据集上优化参数后的“结果”。也就是说,算法“拟合”数据集后,就成了模型。
两个模型可能使用相同的算法逻辑,但因为喂给它们的数据不同,其内部的权重和偏差完全不同。在深度学习(具有多层神经网络的 ML 子集)中,两个模型可能结构相同(如自动编码器),但在层数、神经元数量或激活函数上有所差异。

2. AI 训练的三大门派:监督、无监督与强化学习
AI 模型通常属于三种机器学习范式之一,每种都有独特的用例和算法。值得注意的是,现代顶级 AI(如大语言模型 LLM)往往是集大成者:它们通常先经过自监督预训练,然后进行监督微调,最后通过基于人类反馈的强化学习(RLHF)来完善。
门派一:监督学习(Supervised Learning)
这是目前最先进深度学习模型的基础,专攻需要准确率的任务(如分类、回归)。
- 核心逻辑:
训练时,模型会将预测结果与绝对正确的“基本事实(Ground Truth)”进行比对。传统的监督学习依赖人工标记的数据对(如图片+物体位置坐标标签)。 - 进化形态(自监督学习 SSL):
随着技术发展,现代 ML 从未标记数据中隐式推断“伪标签”。例如,LLM 通过预测文本中被遮蔽的词来学习,此时原始文本本身充当了监督信号,虽然名义上是“无监督”的数据,但本质仍在应用监督学习的逻辑。
门派二:无监督学习(Unsupervised Learning)
不预设“正确答案”,没有传统损失函数。它的任务是去发现未标记数据中隐藏的模式、相关性或潜在分组。
主要算法类别包括:
- 聚类算法:
根据相似性将数据分组。例如著名的 k-means 聚类,常用于市场细分,通过迭代优化质心将客户分为组。 - 关联算法:
识别条件与操作的相关性(如亚马逊等电商的推荐引擎)。 - 降维算法:
用更少的维度表示数据,降低复杂度的同时保留核心特征(用于数据压缩、可视化等)。
无监督学习带有一定“自我优化”色彩,其训练难点往往在于超参数调整(比如手动实验寻找最优的聚类数)。

门派三:强化学习(Reinforcement Learning, RL)
不同于前两者的“拟合数据”,强化学习是通过“反复试验”来训练的,没有唯一的正确答案,只有“好”与“坏”的决策。
其数学框架建立在四大组件上:
- 状态空间(State Space):
决策时的所有可用信息。 - 行动空间(Action Space):
模型可做出的所有决定(如下棋的合法落子,或 LLM 词汇表中的词元)。 - 奖励函数(Reward Function):
对行动的正负反馈。例如训练自动驾驶时,遵守交规给奖励,违规给惩罚。 - 策略(Policy,π\piπ ):
驱动行为的“思维过程”。数学上表示为接受状态并返回动作的函数: π(s)→a\pi(s) \rightarrow aπ(s)→a 。深度强化学习的目标就是更新神经网络的参数,以最大化奖励函数。

3. 炼丹实录:模型开发的八大黄金步骤
虽然三大门派各有所长,但训练一个机器学习模型的生命周期通常包含以下八个迭代步骤:
- 模型选择:
挑选合适的算法或神经网络架构。这不仅取决于数据类型,还需权衡准确性与速度的优先级,以及计算资源预算(如训练 LLM 需要大量 GPU)。 - 数据收集:
获取高质量数据。对于深度学习,可能需要数百万示例。除了开源数据集,使用合成数据在自然语言处理(NLP)等领域也日益可行。 - 数据准备:
对原始数据进行清理、规范化和标准化。可使用自动化工具(如开源工具 Docling,能将 PDF 转为机器可读文本并保留结构)。监督学习还需耗费人力时间进行精细的数据标记(如图像的像素级标注)。 - 选择超参数:
设定算法的模块化元素,如学习率、分批大小(Batch size)等。参数的初始化(通常是随机的,或通过“元学习”来学习最佳初始参数)也在此列。 - 在训练数据上运行模型:
初始阶段模型通常表现糟糕,首轮运行只为建立基线。此时会用到 PyTorch、Keras 或 TensorFlow 等开源框架,它们提供了丰富的教程。 - 计算损失(或奖励):
追踪模型输出与正确答案的差异。在深度学习中,使用反向传播来计算神经网络每个节点对整体损失的贡献(部分架构如 VAE 通过代理目标重新表述,而 RL 则计算奖励)。 - 优化参数:
这一步由单独的优化算法执行,旨在最小化损失函数或最大化奖励。神经网络通常使用梯度下降的变体;支持向量机(SVM)适合二次规划;线性回归用最小二乘法;强化学习则有 PPO、DPO 或 A2C 等专属算法。 - 模型评估:
训练数据得分高不代表万事大吉,必须警惕过拟合(Overfitting)——即模型成了只会死记硬背的“应试教育”产物,无法泛化到新数据。业界标准做法是留出部分数据进行交叉验证,用模型从未见过的数据来测试,确保其真正学到了知识。

总结:
从一行行数学公式到拥有惊人智慧的 AI,模型训练是将数据转化为“知识”的关键炼金术。了解了参数、损失函数、超参数以及三大经典学习范式,你就已经掌握了看透现代 AI 技术黑盒的最核心密码。