 夜雨聆风
夜雨聆风在人工智能快速发展的今天,AI Agent(智能体)的概念正变得无处不在。它们能执行任务、编写代码,甚至规划行程。但这些看似无所不能的智能体,却面临着一个巨大的阿喀琉斯之踵:它们患有“失忆症”。
目前最主流的、用于让 LLM(大型语言模型)“记住”外部知识的技术是 RAG(检索增强生成)。简单来说,RAG 就像是给 AI 配备了一个搜索引擎:当它遇到不知道的问题时,就去静态知识库中“搜”一下,然后把搜到的片段塞进当前的会话中,临时增加其“短期记忆”。
这种方法虽然有效,却有着致命的局限:AI 的“记忆”是暂时的。 会话一结束,搜到的知识就被抛诸脑后。在下一次会话中,它必须再次进行相同的检索,无法随着时间的增长建立起真正属于自己的、可持续的系统化知识。
RAG 的局限:AI 在混沌数据中沉没
我们可以通过下图形象地感受这种局限性。AI 的大脑(一个发光的核心)在混沌、汹涌的数据涡流(无序的数据片段、代码、文档)中苦苦挣扎。它试图使用一个名为“RAG NET”的小小光网去捕获信息。RAG NET 太小了,只能捕捉到混沌中的一小部分片段,而绝大多数数据依然在汹涌流失。这就像是用小网捞水,捞起来的只是极少量的暂时信息,无法系统性地组织和保存。

这种局限性正是安德烈·卡帕斯(Andrej Karpathy)提出的“LLM Wiki”试图解决的问题。他的核心观点是:将 AI 智能体视为一个“学习系统”,而不是一个“执行系统”。它应当主动建立和维护自己的知识体系(Wiki)。
LLM Wiki 的 V1:主动的学习者
卡帕斯的概念在 V1 版本中,核心是让 LLM 将其对外部信息的“学习”和组织,也视为一种“输出”:不是只给出一个答案,而是将学习到的、有价值的知识片段,自动编写成干净、结构化的 Markdown 文件。
这是一种根本性的转变。在 RAG 中,AI 是知识的消费者;在 LLM Wiki 中,AI 是知识的生产者和维护者。这种模式的魅力在于,它引入了复利知识(Compounding Knowledge)的概念:每次与外界的会话,不再只是一个消耗性的过程,而是一个积累性的过程。AI 可以不断地更新、修正、增强其已有的 Markdown Wiki,使整个系统的核心知识随着时间的推移而不断增强。
LLM Wiki V1:有序的学习图书馆
看看下图,我们能清晰地对比出这种改变:同一个 AI 智能体核心(仍然是 image_0.png 中的发光核心,但现在冷静、 methodical)漂浮在一个整洁、有序的数字矩阵中。它使用精确的、束状的操纵光,主动地将发光的 Markdown 文件整理成 neat、垂直生长的堆栈。每个堆栈都是 color-coded(彩色编码),并带有distinct标签:'CONCEPTS.md'、'OBSERVATIONS.md'、'PATTERNS.md'。随着新文件的创建,堆栈无缝地复制、复合,辐射出 faint、warm 黄金般的光辉(symbolizing 复合知识)。背景是一个 luminous、 structured 网络,取代了湍急的 vortex。这完全是一个系统化、主动的学习场所。

从 V1 到 V2:认知神经科学的集成
但这只是开始。随着 V2 版本的提出,卡帕斯的想法正变得更加深远。V2 不仅仅是增加了一些 Markdown 文件,而是将认知神经科学的原理集成进智能体的架构中。
传统的 RAG 类似于将所有记忆都存储在外部硬盘中(Semantic Memory/语义记忆)。V2 的重点在于,它试图在智能体的内部架构中,明确地区分不同类型的记忆:
Working Memory(工作记忆):类似于当前的会话 Context/Attention。
Episodic Memory(情节记忆/交互历史):这不仅仅是日志(Logs),而是经过 LLM Wiki 处理后的、带有时间戳和上下文的交互历史(如使用
agentmemory进行结构化的情节记录)。Semantic Memory(语义记忆):这就是 LLM Wiki V1 中所强调的,经过 AI 主动组织、提取出的结构化 Markdown 知识库。
这就像是一个真正的生物大脑:将临时的短期记忆(Working Memory)转化为带有情节的体验(Episodic Memory),最终从体验中提取出通用的知识(Semantic Memory),从而建立起智能体的核心本体(Ontology)。
LLM Wiki V2:认知复合蓝图
看看下图,这是一个 glowing、blueprint-style diagram, visualized as an extension of image_1.png 的 organized digital structure。它 bathed in soft blue and green light。一个 central, upgraded LLM 'Brain Core'(referenced as image_0.png and image_1.png entity)connects via intricate data pathways。Crucial structural modules are labeled with precise text: 'WORKING MEMORY (Context/Attention)', 'EPISODIC MEMORY (Logs, Interaction History)', 'SEMANTIC MEMORY (The Structured LLM Wiki / Markdown Files seen in image_1.png)', and 'EXTERNAL KNOWLEDGE (RAG/Search)'。Arrows indicate active, continuous feedback loops。A separate, circular gauge labeled 'ENTROPY CONTROL' monitor actively data inputs, while a specific processing block labeled 'KNOWLEDGE SYNTHESIS & CONDENSATION (using agentmemory)' filters information, maintaining structure。The entire schematic is technical, extremely detailed, and systematic, showing complexity under control。
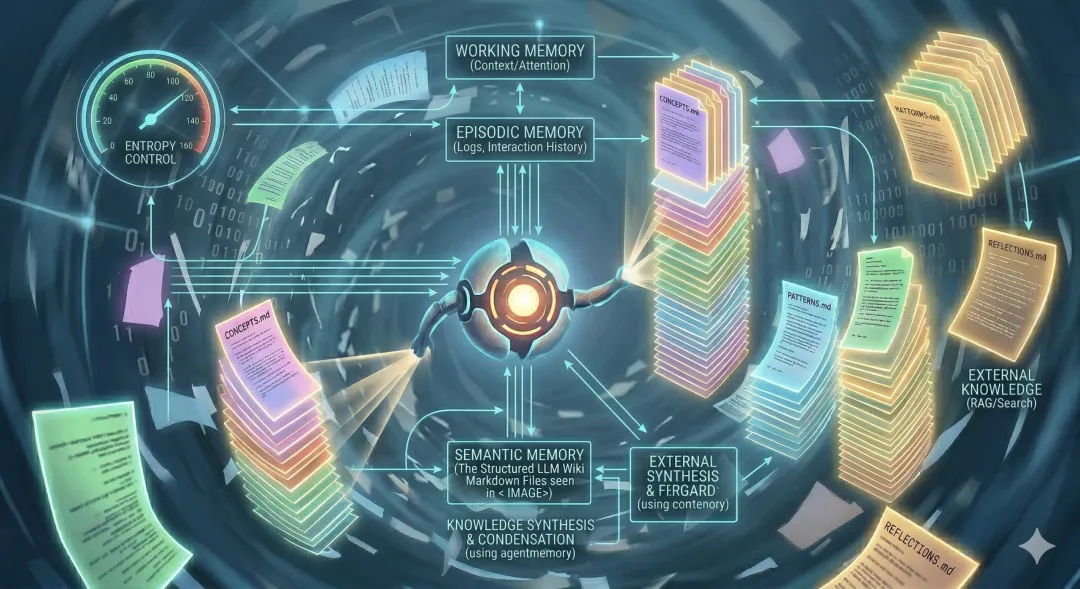
熵控:区分“墓地”与“活的记忆”
在实际部署中,LLM Wiki 面临着一个关键挑战:知识的“熵控(Entropy Control)”。 这也是为什么 RAG 数据库常常变成一个“saved links graveyard(被保存链接的墓地)”的原因。缺乏有效管理的静态数据库,其熵值会不断增加:过时、重复、冲突的信息充斥其中,导致检索效率低下和产生幻觉。
LLM Wiki V2 架构引入了**KNOWLEDGE SYNTHESIS & CONDENSATION(知识合成与凝聚)**过程。它不仅是存储信息,而是使用工具(如 agentmemory 或 MCP [Model Context Protocol])主动地对知识进行“清洗”和“提炼”:
归约(Reduction):将重复的信息合并。
清理(Cleaning):去除无关噪音。
对齐(Alignment):确保不同文件中的信息不发生冲突。
这种主动的熵控,保证了 LLM Wiki 是一个“活的记忆”系统,而不是一个不断坍塌的知识堆栈。它让智能体的语义记忆和情节记忆能够相互反馈,从而建立起真正的 compounding(复合)优势。
总结:迈向真正的“第二大脑”
卡帕斯的“LLM Wiki”概念,标志着 AI 记忆系统从简单的检索向*认知复合(Cognitive Compounding)*的根本转变。它不再是试图让 AI 学会“如何查找东西”,而是试图让 AI 学会“如何构建自己的大脑”。
最后的愿景:无限复合的数字未来
让我们用最后的愿景来总结这种范式:下图是一个 grand, panoramic conceptual landscape。一个 vast, intricate, self-replicating crystalline structure made of pure, harmonious digital light(a combination of golden-blue energy and structured order from image_1.png and image_2.png)extends into an endless horizon。It branches organically like a massive, illuminated neural network, but composed of precise geometric data blocks and glowing files。The entire structure radiates a constant, gentle humming energy。The AI agent (a tiny, luminous presence, the core seen in image_0.png, image_1.png, image_2.png) is visible at the very center of the system, observing and guiding the growth。Floating, integrated holographic panels subtly text within the light: "COMPOUNDING KNOWLEDGE," "PERSISTENT AGENT MEMORY," "LLM WIKI V2 PARADIGM," and "KNOWLEDGE ENTROPY MITIGATED." It visualizes the ultimate success of the paradigm shift.

在这个 compounding 的范式下,AI 智能体将不仅仅是一个临时的工具,而是一个真正可持续发展的、伴随我们一起成长的“第二大脑”。这才是 LLM 记忆系统的未来。
