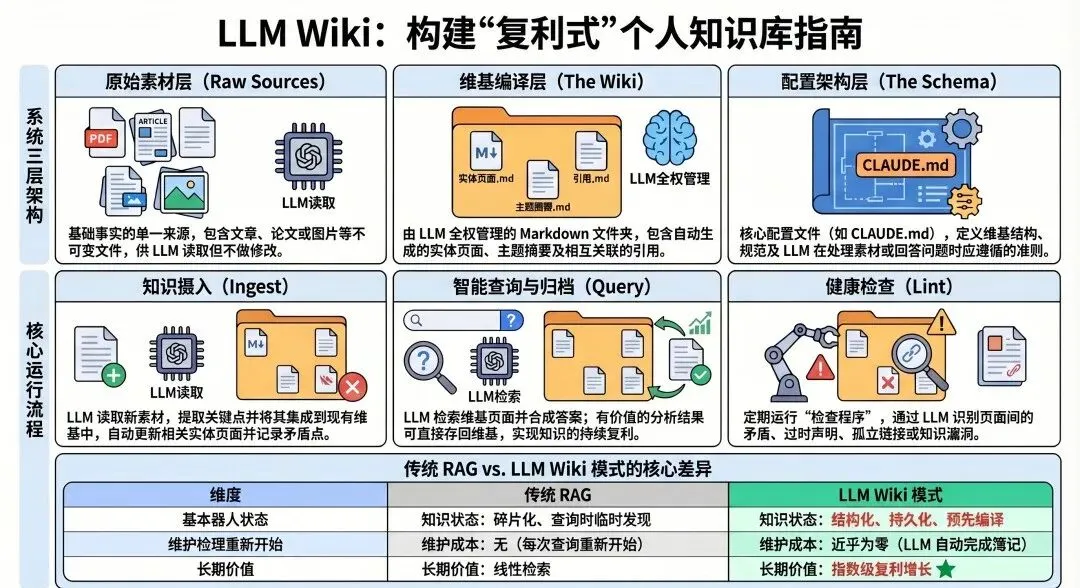
你有没有过这种经历:之前让豆包生成了一稿方案,你觉得非常好。过了1个月,你有类似的任务,想再让豆包生成一个类似的,却再也生成不出那么满意的。你记得上个月和豆包聊了好久,最后才打磨出来的一个方案,但当时的聊天已经淹没在茫茫多的日常对话中了。你也没办法再重现当时的讨论场景了,只好退而求其次,使用现在那版没那么满意的方案。前段时间,前OpenAI科学家、特斯拉AI前负责人Andrej Karpathy(卡帕西)在X上发了一条长推文,分享他自己搭个人知识库的工作流。其中有句话让我停下来想了很久——“The wiki is a persistent,compounding artifact.” 知识库,是一个持续复利积累的产物。他还说:每一次探索、每一次提问,都会叠加进这个知识库里,越用越厚。这句话正好戳中了我的一个困惑:AI这么好用,我还需要自己维护知识库吗?当我每天至少用掉500万Token后,我才发现在AI时代,个人知识库的价值反而更大。AI替代不了的,恰恰是这三件事01 你的私有知识,AI根本够不着AI能回答你任何公开的问题,但它完全不知道你做过什么。你上个月跑的那场客户调研会议,你整理的行业一手数据,你踩过的坑和总结出来的经验——这些东西既不在互联网上,也不在任何AI的训练集里。要用的时候,AI给不了你。有人会说:那我把资料喂给AI不就行了?可以,但每次用都要重新上传、重新交代背景,AI没有记忆,上次的对话下次全忘。相当于每次对话,都是从0开始搭建一套Harness系统。不知道Harness的可以补个课:Harness:AI 真正干活,靠的不只是模型。但光说「有数据、调不出来」可能还不够具体。我举个实际的场景:你去年做过一个销售激励政策,花了三天整理,最后形成了一套判断框架—什么情况下新签客户的提成更高,什么情况在要提升销售的续约提成。现在新来一个项目,你想重新用起来,但那份文档存在哪儿?是那个笔记App?还是当时随手发给文件传输助手的微信?还是在某个邮件附件里?你记得有,但找不到具体在哪。然后你就只能靠脑子里的模糊印象重新拼——或者干脆让AI帮你重新生成一个「通用框架」。但那个框架是通用的,不是你的。你花三天踩出来的判断,AI一秒就抹平了。这部分知识,只能存在你自己手里。用的时候调不出来,等于没有。02 AI给你的,永远是「通用答案」这是一个更隐蔽的问题。AI的输出是基于全网的通用知识拼出来的。它不知道你的行业积累,不知道你的判断框架,更不知道你在某个具体项目里踩过什么坑。举个让感受更直接的例子:年终总结。假设你和同事同时让AI来写,你们给的 prompt 差不多,都是“帮我写今年的年终总结,突出亮点和成长”——然后呢?AI给你的,是一篇结构完整、措辞得体,但可以套在任何人身上的文章。什么“深入参与了多个项目”、“在团队协作中发挥了重要作用”、“持续提升了专业能力”——每一句话单独看都成立,合在一起,却不是你,是任何一个说得过去的职场人。现在换一个人,他手边有一份积累了三年的项目笔记——每个项目结束后写的复盘,踩过的坑,当时的判断和后来的结果,以及一些只有他自己才懂的上下文。他把这些资料调出来,让AI帮他整理和提炼,最后出来的年终总结,里面有真实的项目名、具体的数据变化、他自己当时做了什么决策、带来了什么影响。两份总结放在一起,差距一眼就出来了:一份是模板,一份是经历。AI是放大器,但它放大的是你已经有的东西。你没有积累,它放大的就是通用——而通用,在这个AI人人都能用的时代,几乎等于没有竞争力。03 内容存在别人平台,随时可能失控关于这件事,我吃过三次亏。1. 第一次是在5年前,当时我还是一个印象笔记重度用户,我所有的笔记都在里面,一切都是那么的美好。直到有一天,印象笔记开始重度商业化,即使你买了会员,还是不停的有各种各样的广告。2. 后面我开始做笔记的迁移工作。当时锚定了一款非常前沿的笔记工具,Notion。当时花了很大的力气,将我的笔记从印象笔记逐步迁移到了Notion。但随之而来的又有两个问题:一是网络问题,二是离线编辑的问题,虽然这两个问题放到现在都不是问题,但当时确实给我造成了很大的困扰。3. 于是我开始寻找国内有没有优秀的平替,最后发现有一个小而美的笔记软件,叫Wolai(我来)。当时的产品理念和设计,和Notion简直如出一辙,且没有任何网络障碍,所以我又把笔记内容平移到了Wolai。但不久后,Wolai被阿里收购,虽然现在还在运营,但不敢赌后续的运营风险,于是又开始寻找新的笔记软件。所以你看,如果把内容存在笔记平台上,就有可能发生:1. 运营策略调整导致的体验变差;2. 魔法上网的问题;3. 平台自身运营风险;说完痛点,再说一个更根本的问题上面三个坑,更多是“防守”层面的——用户体验、网络问题、运营更新啊。但我觉得还有一层更值得想:在AI时代,个人知识库到底意味着什么?通用知识已经不值钱了这件事正在悄悄发生,但很多人还没意识到。过去,竞争力的来源之一是“我懂得比你多,我记得住”。但现在,任何一个公开的知识点,AI一秒就能给你。行业报告、方法论框架、专业术语解释——这些东西的获取门槛,已经无限接近于零。如果你的积累主要是“攒了很多通用知识”,这部分的价值正在快速缩水。真正开始值钱的,是你用自己独有的经验,去整合AI的通用输出,做出只有你才能做的结果。举个具体的例子:同样是做行业咨询方案,刚入行的人用AI能拼出一份结构完整的报告,但里面全是公开套话;一个有五年项目积累的顾问,能把自己做过的案例、踩过的坑、一手调研数据直接调进来,AI帮他整合和表达——出来的方案,是别人拿不走的。差距不在于谁用了AI,而在于谁有东西可以给AI用。你的知识库,是你给自己训练的“私有数据集”卡帕西在分享他的工作流时说了一句话,我觉得是整件事的核心:“So my own explorations and queries always 'add up' in the knowledge base.” 我的每一次探索和提问,都会持续叠加在知识库里。这个“叠加”的概念很关键。现在所有的大模型,都是基于全网公开数据训练的——它们懂的,所有人都能调用。要让AI真正理解你、为你服务,就得持续给它喂你自己的数据。但「喂数据」这件事,听起来技术,落地其实很日常:你做完一个项目,花二十分钟写一份复盘,记录当时的决策依据、踩过的坑、以及最后结果和预期的差距——这就是数据。你读完一本书,整理出三条真正改变了你判断的观点,加上你自己的理解——这也是数据。你有一次让你困惑的客户沟通,你把那个对话里觉得费劲的地方和后来想通的逻辑写下来——同样是数据。这些东西单独看,都只是“一条笔记”,但当你在Obsidian里把它们和相关的项目、人物、方法论关联起来,形成一张相互引用的知识网,你再打开AI说“帮我针对这个客户场景设计一套方案”,然后把相关的那几条笔记一起丢进去——AI给出的答案,就不再是从公开资料里拼出来的通用方案,而是基于你的真实经历、判断偏好、踩坑记录定制出来的东西。这才是卡帕西说的「持续复利积累」真正指向的东西:不只是笔记越来越多,而是你和AI协作的效率,会因为这个库的存在,持续复利地提升。你的思考方式、项目经验、写作风格、决策偏好,全部沉淀在这里。AI是帮你提速的外挂,但个人知识库才是你的私有内核。没有这个内核,AI给每个人的东西都差不多;有了它,AI才真正变成你的。接下来怎么搭?说到这里,你可能会想:道理我懂了,但从哪里开始?其实卡帕西的工作流给了一个很清晰的思路。他在GitHub Gist里描述自己的体系时,用了这样一个比喻:“Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.”Obsidian是IDE(开发环境),LLM是程序员,Wiki是代码库。这个比喻让我觉得挺准的——Obsidian负责让你看见和管理所有内容,LLM负责帮你整理和提炼,而你积累的Wiki本身,才是那个越跑越顺的「代码库」。他的实际工作流大概是这样的:用Obsidian Web Clipper把文章、论文、资料存进一个raw/目录;让LLM把原始资料「编译」成结构化的Markdown笔记,包含摘要和概念之间的关联;积累到一定规模之后,就可以直接对这个知识库提复杂问题,LLM给出的答案也会被归档回去,继续增厚这个库。听起来有点技术?其实核心逻辑并不复杂:原始资料进来,LLM帮你消化,结构化笔记沉淀,下次调用更快。我接下来这个系列,就是把这套思路落地成普通人能直接用的版本,工具选 Obsidian,记录使用 PARA 笔记法,知识库+AI落地借鉴卡帕西大神的方法,和大家一起从0开始构建AI时代的知识管理工作流。该系列不涉及任何代码,在文章后,我也会附上参考模板。下一篇会先为大家分享为什么选择Obsidian,以及如何快速安装上手Obsidian。最后也和向大家请教一下:你现在存笔记和资料,主要用什么工具?
基本文件流程错误SQL调试
请求信息 : 2026-04-14 19:21:20 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/523750.html
 夜雨聆风
夜雨聆风