 夜雨聆风
夜雨聆风声明
本系列文章只是一组阶段性的思考与实践记录,主要用于抛砖引玉,并不构成对所有学科、所有工具或所有研究场景都适用的标准答案。由于 AI 工具迭代很快,本文中的部分判断、界面描述与工作流经验都具有较强时效性,随着模型、插件和平台的发展,后续很可能需要重新修订,因此也请读者结合自己的实际情况自行甄别。另需特别说明:本文讨论的是 AI 对研究工作区、材料组织与日常流程的辅助作用,而不是鼓励任何形式的学术不端。无论工具如何发展,文献理解、研究判断、结果核查与学术责任都不能外包给 AI。
此文章中的示意图与分析图由Gemini Nano Banana Pro生成,特此声明。

很多人第一次接触 AI,体验都差不多:问一个问题,得到一段回答;再追问一句,再得到一段更具体的解释。这个入口很自然,所以大家很容易把 AI 理解成一个更聪明的搜索框,或者一个更灵活的答疑助手。这种理解当然成立,只是还没有把问题说完整。
研究工作并不是若干次提问的简单叠加。它更像一个不断积累材料、不断回看旧判断、不断修订结构的过程。文献会越读越多,笔记会越记越散,草稿会出现多个版本,图表、表格、说明和临时想法也会一点点堆起来。到了这个阶段,真正耗人的,往往不再是“某个问题有没有答案”,而是“这些材料究竟如何组织”“哪些东西已经做过了”“哪一版才是现在应当接着写的那一版”。
这其实也是 AI 进入学术场景之后,一个很容易被忽略的变化。过去的工具更擅长支持单点任务。检索归检索,写作归写作,作图归作图,记笔记又是另一个地方。每个环节都能找到工具,但工具之间并不真正理解彼此。AI 出现之后,人们最先注意到的是它“会回答”“会改写”“会解释”。可从更深的层面看,它真正带来的变化是:工具第一次有可能开始理解上下文,甚至开始进入一个真实的项目现场,接触目录、文件、说明和历史痕迹。
所以我更愿意把 AI 的价值先说得朴素一点。它当然可以回答问题,也可以改写句子,但对研究者来说,更有意义的往往不是它答得多快、多像,而是它能不能帮助你面对那些真实存在的研究材料。这里说的材料,并不一定非得是复杂代码。你放在文件夹里的 PDF,写在文档里的阅读笔记,保存了多个版本的章节草稿,导出来的图表,以及那些给导师或同学看的说明文件,这些本来就是研究的一部分。只要它们开始积累,整理与衔接就会变成一件极其现实的事。
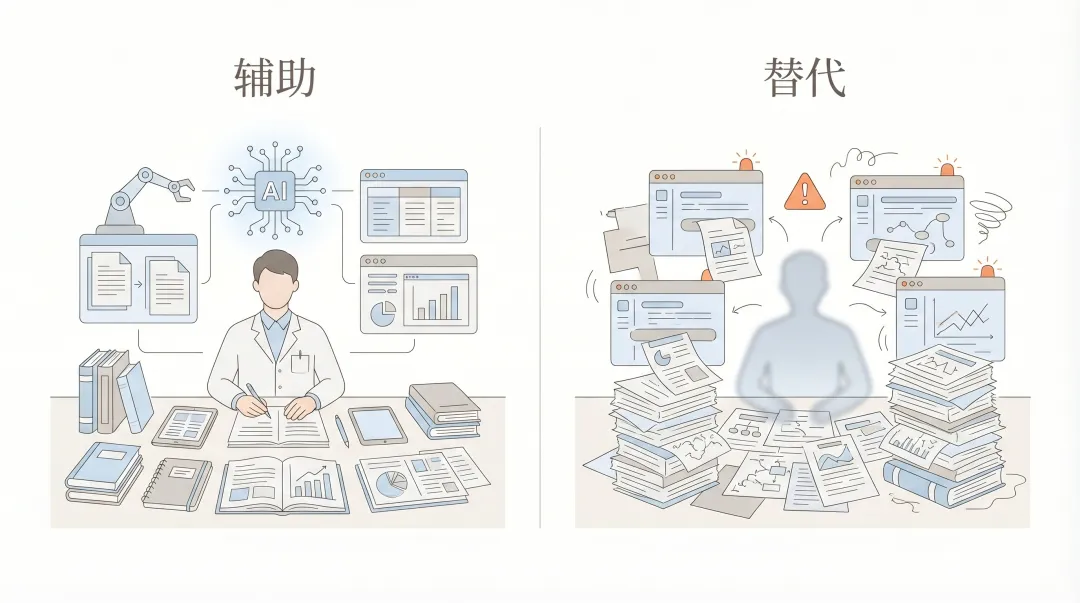
从这个角度看,我们需要的就不只是一个“会回答问题的 AI”,而是一个能在清楚边界内帮助你整理、连接、检查和辅助推进这些材料的助手。它不必一开始就做很多复杂的事,但至少应当逐步接近研究现场,而不是永远只停留在一个问一句答一句的窗口里。对很多研究者来说,这种变化可能比“某个模型又提高了多少分”更重要,因为前者改变的是工作方式,后者往往只是回答质量的边际提升。
这里的边界也必须提前讲清楚。AI 可以辅助研究,可以帮助阅读公开材料、整理目录、检查格式、撰写工具脚本、归纳思路,但它不应该替代研究者的判断,不应该替代你对材料的理解,也不应该被理解成“论文代写工具”。这不是一句为了保险而说的场面话,而是整套方法能不能成立的前提。只要这个边界没有立住,后面所有关于日志、脚本、工作区和最终输出的讨论,都会失去最基本的正当性。
很多人第一次听到“工作区”“Agent”这些词,会觉得它们像程序员世界里的概念,离自己有点远。其实不必这样理解。哪怕你从来没有系统接触过 VSCode,也已经有自己的研究现场了。你放资料的文件夹、写草稿的文档、记笔记的软件、导出图片的目录,这些东西合在一起,本来就是你手头的工作环境。现在真正发生变化的,不是突然多了一个高深的新概念,而是你开始意识到:这些材料如果能被组织得更清楚,再加上一个能够协助处理文件和说明的工具,很多重复性的低效动作就会少很多。OpenAI 在一份关于 agents 的实践指南里把它概括得很直接:"Agents are systems that independently accomplish tasks on your behalf." 这句话并不神秘,它真正点出的,是工具开始从“回答问题”转向“代表你完成一部分工作流程”的变化。
也正因为如此,在那些需要长期积累材料、反复修改版本、持续回看上下文的学习、科研或生产性任务里,面对 AI 的第一步不一定是立刻提很多问题,而是先回头看一眼自己的研究现场是否清楚。材料是否有一个相对独立的目录,草稿和图表是否混在一起,笔记有没有一个稳定的去处,项目中有没有最基本的说明文件。它们看起来普通,却决定了后面协作到底是零碎的,还是能够逐步积累起来的。说得更直接一点,AI 能否真正帮上忙,往往不是由它单方面决定的,也取决于你是否给它准备了一个能被理解的现场。
真正能让这种协作稳定下来的,往往也不是什么神奇提示词,而是工作本身有没有留下清楚的痕迹。有没有目录说明,有没有日志,有没有索引,有没有修改时间,有没有比较统一的命名和编码约定,这些看起来不算“厉害”的东西,反而经常决定了一个工具到底只能零散帮忙,还是能逐步接上一部分工作。它们既帮助后来的自己快速回到现场,也帮助 AI 少走很多弯路。
这也是为什么我会觉得 Codex 这一类工具值得研究者认真看一眼。它当然有代码能力,但它的意义并不只限于“写代码”。只要你的研究过程包含真实文件,包含逐步积累的资料,包含不断修改的文档,包含一些需要工具协助处理的流程,这类工具就已经和你有关。它能够帮助你整理目录,协助你检查文档,辅助你归纳材料,生成一些重复性的工具脚本,或者把零散的研究过程变得更有条理。说到底,它不是把研究变成编程,而是让原本已经文件化、项目化的研究过程变得更可管理。
因此,这组文章接下来真正想做的,不是告诉读者“某个模型有多强”,而是尽量把一条更稳妥的路线讲清楚:如何在不越过学术边界的前提下,让 AI 帮你组织材料、辅助处理文件、减少低效重复劳动,并把人的精力留给阅读、判断、论证和表达本身。
如果用一句最短的话概括本系列文章的核心想法,那就是:研究工作需要的,不只是一个会回答问题的 AI,而是一个能够在边界清楚的前提下,帮助你整理研究现场的助手。
