 夜雨聆风
夜雨聆风副标题:FSD v12 架构重写、端到端神经网络、以及 EEA 为什么被迫走向集中
开场:那个工程师写下的一行笔记
(以下是基于公开信息构建的复合场景,用于说明 E2E 系统的典型工程体验,不是对某一具体事件的报道。)
2024 年,FSD v12 的早期测试者们反复报告了类似的场景:车绕过了一辆从没在训练数据里见过的异形障碍物——没有人工干预,没有规则匹配,神经网络自己想出来了。
一个在 E2E 社区里广泛流传的感受是:**"它做到了。但我不知道它为什么能做到。"**
这句话,精确地概括了 AI Defined Vehicle(AIDV,AI 定义汽车)这个概念的全部张力——
一面是惊人的能力进展,真实的;
一面是没人能完全说清楚"为什么",也是真实的;
以及一个没有人真正解答了的问题:你怎么证明一个你自己都看不懂的系统是安全的?
在回答这个问题之前,先说一件更重要的事。
关于 AIDV,外界有太多各自混在一起讲的声音——既有已经在百万辆车上跑的现实,也有还在实验室里的研究原型,还有行业路线图上的宏伟愿景。把这三类东西混为一谈,是技术科普里最常见的不诚实。
本文要做的是一次分类——明确区分哪些已经发生,哪些正在研究,哪些是我们希望发生。 因为对于 AIDV 这样一个仍处于快速演进中的领域,这种区分本身就是最重要的工程洞察。
第一幕:AIDV 和 SDV 的根本区别在哪里
从"人类写规则"到"AI 学规则"
上一篇(第九篇)讲了 SDV(Software Defined Vehicle,软件定义汽车)的工程账单:区域式 EEA(电子电气架构)、中央计算平台、SOA(面向服务的架构)通信、OTA(空中升级)能力——这些构成了 SDV 的基础设施。
但 SDV 有一个根本前提没有变:软件是人写的。
工程师把对驾驶的理解翻译成代码。如果左边有障碍物,往右偏;如果前方有行人,停车;如果交叉口有停止线,刹车到线前。每一个决策场景,都对应一段人类编写的逻辑。L2/L2++ 的自动驾驶系统里,感知层已经大量使用神经网络(目标检测、车道线识别等),但规划和控制层仍然是人类手写的规则引擎——可能有超过 30 万行 C++ 代码(Ashok Elluswamy,Tesla AI Day 2023),每一条规则都是某位工程师的知识被翻译成了代码。
AIDV 改变的是这个根本:不再由人类预先编程车辆行为,而是由从真实数据训练出来的 AI 模型实时推理生成。
听起来像微妙的语义区别,但工程含义是天壤之别。
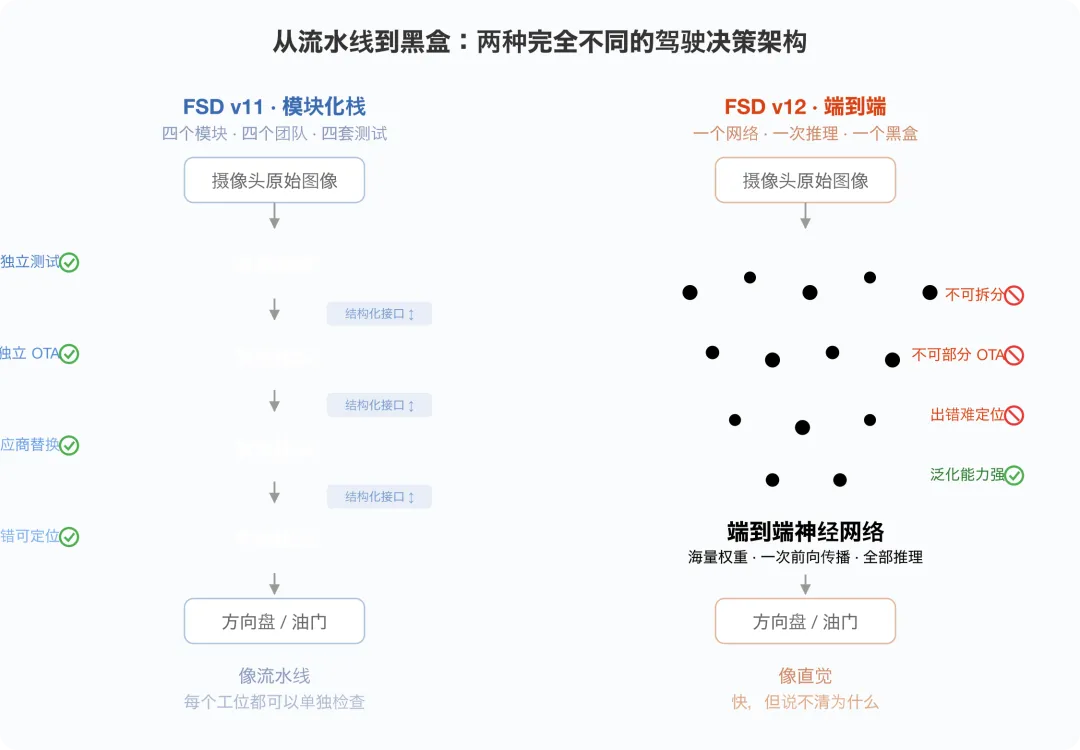
FSD v12:一次架构重写,不是功能升级
用 Tesla FSD(Full Self-Driving,直译"完全自动驾驶"——但需注意其法律定义仍为 L2 级驾驶辅助)的演进来说明这个区别,是目前最具说服力的真实案例。
FSD v11 及之前(已量产):Tesla 工程师维护了一套极其复杂的模块化系统。感知模块负责"看到"障碍物、识别车道线、检测行人;预测模块估计每个目标的未来轨迹;规划模块基于感知和预测结果计算自车应该怎么走;控制模块把规划结果转换成具体的方向盘转角、油门开度、制动力。每个模块有清晰的接口,有独立的测试,出了问题能定位到哪段代码。仅规划和控制栈就有超过 30 万行 C++ 代码(Ashok Elluswamy,Tesla AI Day 2023),但它是可读的——至少在原则上,工程师可以指着某一条说"这是它在这个场景做这件事的原因"。
FSD v12(2024 年初正式发布,已量产):架构重写。感知→预测→规划→控制这条流水线不见了。取而代之的核心是一个端到端(End-to-End,E2E)神经网络:摄像头原始图像输入,网络输出轨迹点(trajectory points)——自车未来若干秒应该走的路径,再由一个传统的控制器把轨迹转成具体的方向盘转角和油门/制动指令。中间是一个大规模神经网络(Tesla 未公开具体参数量),感知、预测、规划三个环节在一次前向传播中完成。此外,系统仍保留了一些规则安全层(safety checks)做最终兜底——但 30 多万行的规划规则代码被替换了,这是架构性的变化。
这不是 FSD 的版本迭代,是架构重写。就像从写满代码的白板,换成了一个黑盒。
那个黑盒能绕过从没见过的推车。工程师不知道为什么。
这个区别在工程上意味着什么
更强在哪里(已量产数据支持):神经网络能处理人类工程师"想不到"的边缘场景。传统规则树的上限是"工程师能枚举的场景"——而工程师无论多厉害,也无法预见所有的真实道路情况。E2E 模型从数百万个真实驾驶片段里学习,它"见过"的场景远比任何工程师能手动编码的多。大量 FSD 用户的实测报告和社区对比测试显示 FSD v12 相比 v11 在干预频率上有显著改善——但需注意,Tesla 官方从未发布过 v12 vs v11 的 disengagement 对比数据,这些主要是社区观察,不是经过控制变量的官方统计。
更难验证在哪里(也是确凿的):确定性代码可以被审查——你可以读它,测试它,在逻辑上证明在某些输入条件下它会做什么。一个拥有海量权重参数的神经网络,没有人能"读懂"它。你无法指着某个权重说"这是它在雨夜识别行人的部分"。验证方法从"穷举逻辑路径"变成了"在足够多的场景里测试,统计失效率"——但"足够多"是多少?没有人给出过令人满意的答案。
这就是 AIDV 最核心的工程张力:能力上的突破,和可验证性上的倒退,同时发生在同一个架构里。
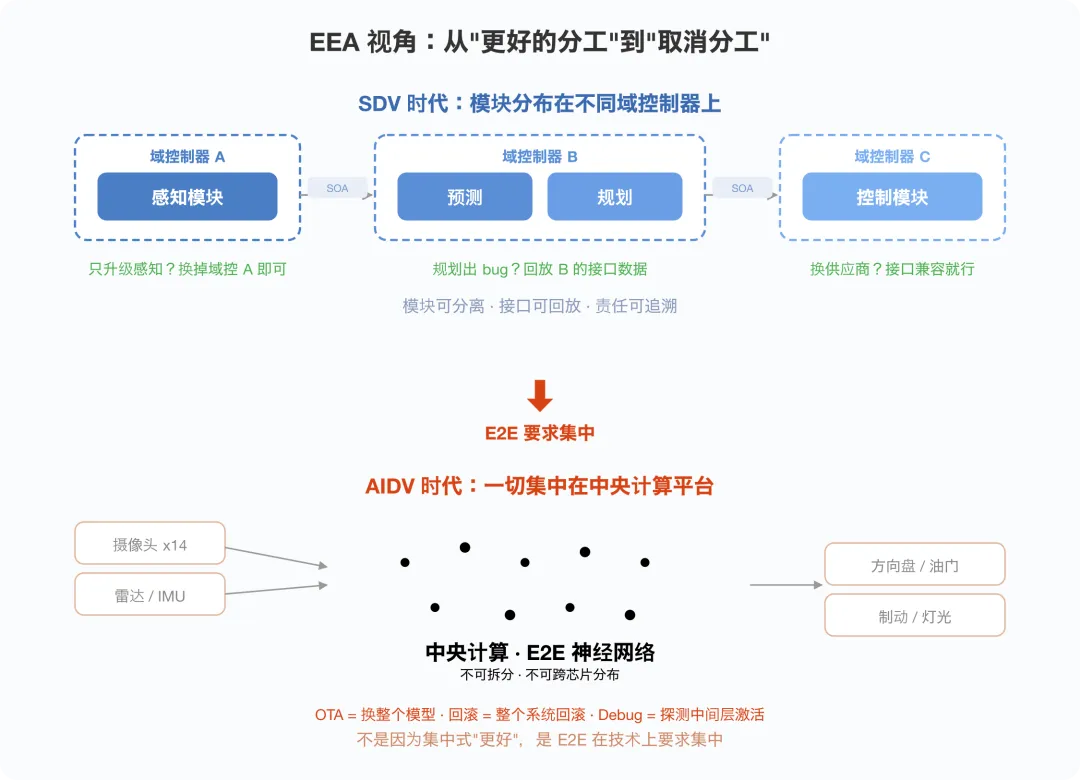
从 EEA 的视角看:为什么 E2E 逼出了中央计算
这个架构转折对 EEA 有一个直接的、不可逆的影响。
模块化栈时代,感知、预测、规划、控制四个模块虽然通常运行在同一个 ADAS 域控制器上,但它们在软件层面是清晰分离的——有定义好的接口、独立的代码仓库、独立的测试套件。理论上你可以只 OTA 感知模块而不动规划模块(实践中因为模块耦合,往往需要联合回归测试,但至少接口边界是存在的);debug 时可以回放中间接口的数据,精确定位是哪个模块出了问题;甚至可以把某个模块替换成另一家供应商的方案,只要接口兼容。
E2E 把这些灵活性全部收走了。
整个推理必须在同一个计算节点上完成——一颗芯片,一次前向传播,中间没有可以拆分的接口。OTA 的粒度从"模块级"变成了"模型级":要么换整个模型,要么不换。回滚也是如此——不存在"只回滚感知层"这种操作,因为"感知层"在 E2E 里不是一个独立的软件实体。
这直接推动了 EEA 向更集中的计算架构演进。不是因为集中式"更先进",而是 E2E 在技术上要求算力高度集中。跨芯片拆分推理(model parallelism)不是不可能——NVIDIA DRIVE Thor 的双芯片方案通过 NVLink-C2C 片间互联,正是将两颗 SoC 组成统一计算平台来跑更大的模型(下一篇会详细拆解)。但这种方案对芯片互联带宽和时延有极高要求,目前只有 NVIDIA 等少数平台能做到,且量产时间表仍在推进中。对大多数 OEM 和 SoC 供应商来说,"一颗足够强的芯片跑完全部推理"仍然是更现实的工程路径。
SDV 的 EEA 演进方向是"更好的分工";AIDV 的 EEA 演进方向是"取消分工"。 这不是程度的区别,是方向的区别。下一篇讲 2000 TOPS 的算力需求时,你会看到这个"取消分工"的决定在硬件层面激起了多大的连锁反应。
第二幕:端到端 AI 今天真正在做什么
E2E 架构的工程本质
在谈这一块之前,先把 E2E 架构讲清楚——不是定义,是结构。
传统模块化自动驾驶栈,有四个显式的环节:
感知模块:摄像头/激光雷达/毫米波雷达的原始数据进来,神经网络(或传统算法)处理,输出"结构化理解"——这里有一辆车,距离 3.2 米,速度 18km/h,置信度 0.92。
预测模块:拿到感知结果,推算每个目标未来 3 秒内的轨迹分布。
规划模块:给定感知和预测结果,规划自车的参考轨迹——什么时候变道、以什么速度通过交叉口、在哪里停车。
控制模块:把轨迹转成低层执行指令——具体的方向盘角度、具体的扭矩请求。
四个环节,四套代码,四套测试,四个团队。接口清晰,责任清晰,Debug 时能精确定位到哪个环节出了问题。
E2E 架构把前三层(感知、预测、规划)折叠进一个网络。没有显式的感知结果传递给独立的规划模块,神经网络直接从像素映射到轨迹决策,最后由传统控制器执行。
这带来了一个传统栈做不到的特性:消除了模块间的"误差传递"。传统架构里,感知模块输出的置信度误差会被预测模块放大,再被规划模块进一步放大——这是模块化分解的固有代价。E2E 网络在训练时优化的是最终输出(轨迹/决策)相对于人类驾驶示范的误差,而不是每个中间模块的输出误差。理论上,它能找到比人类工程师设计的分工方式更优的"隐式表示"。
同时带来了一个传统栈不必面对的代价:可解释性近乎为零,Debug 极其困难。出了问题,你很难直接判断是"感知出了错"还是"规划出了错"——因为这两个环节不再有显式的接口输出供你检查。你只知道"输入了这段视频,输出了错误的轨迹",而海量权重参数里没有任何一个能直接告诉你"原因"。(不过,正如下一节会讲的,工程师并非完全无计可施。)
这不是夸张,这是目前部署 FSD v12 的工程师每天面对的现实。
E2E 内部不是完全无结构——工程师的 debug 手段
"从像素到方向盘,中间是黑箱"——这是正确的高层描述,但如果以为 E2E 模型内部是一团完全无法理解的混沌,那就过了。工程上,多数 E2E 自动驾驶模型内部有清晰的功能分区——虽然这些分区是端到端联合训练的,不是手动设计的独立模块:
视觉编码器(Vision Backbone):从多路摄像头的原始图像中提取视觉特征。主流选择是基于 Transformer 的架构——和 ChatGPT 底层用的是同一族技术,但针对视觉任务做了适配(ViT,Vision Transformer)。
BEV 编码器:把多路摄像头各自提取的特征,投射到一个统一的鸟瞰图空间(Bird's Eye View,BEV)。这一步解决了一个关键问题:不同摄像头看到的是不同视角的 2D 图像,但驾驶决策需要的是一个统一的 3D 空间理解。BEV 是目前多数 E2E 方案的"隐式中间表示"——它不是传统栈那种显式输出的"3D 障碍物列表",但它在网络内部承担着类似的角色。
时序融合(Temporal Fusion):不只看当前帧,还融合过去数帧甚至数秒的信息。一辆车正在加速还是减速,一个行人是在走向斑马线还是已经停住了——单帧看不出来,需要时间序列。
规划头(Planning Head):从 BEV 特征直接预测自车未来若干秒的轨迹点。这些轨迹点再交给传统控制器转成方向盘转角和油门/制动指令——这最后一步通常仍是经典控制算法,不是神经网络。
这些功能分区之间没有显式接口(不像传统栈的模块间 API),但工程师可以探测中间层的激活(probe intermediate activations)——把 BEV 特征图可视化出来,看模型在鸟瞰空间里"看到"了什么。如果一个行人在 BEV 特征图里完全没有对应的激活,你就知道问题出在视觉编码阶段;如果 BEV 里看到了但轨迹预测仍然错误,问题就指向规划头。
这不是传统 debug 那种"读代码找 bug"的精确度。它更像是看一个人的脑部 MRI——你看不到具体的思维过程,但你能看到哪些区域在活跃,这足以缩小问题范围。学术界已经沿着这条路走得很远:UniAD(统一自动驾驶框架,上海 AI Lab / 香港大学,CVPR 2023 Best Paper)、VAD(向量化自动驾驶,北京大学 / 华为,2023)等方案明确展示了"端到端训练但内部可探测"的工程路径。Tesla 没有公开过 FSD v12 的架构论文,业界普遍推测其内部也采用了类似的分层特征结构——但这仍然是推测,不是已确认的事实。

一个被低估的工程优势:推理延迟
E2E 有一个在 EEA 层面很重要、但很少被讨论的工程优势:延迟更短,且更可预测。
传统模块化栈的端到端延迟是各模块延迟的串行累加:感知 ~30ms + 预测 ~10ms + 规划 ~20ms + 控制 ~5ms + 模块间通信和序列化开销——总延迟 80-100ms 级别(典型工程参考值)。更关键的是每个模块的延迟都有波动,最坏情况下的累加可能导致整条链路偶尔飙到 150ms 以上。
E2E 一次前向传播:20-50ms(取决于模型规模和芯片算力),没有模块间通信开销,延迟抖动更小。对于安全关键系统来说,延迟的可预测性和延迟的绝对值一样重要——你宁愿有一个稳定 40ms 的系统,也不要一个平均 30ms 但偶尔飙到 150ms 的系统。
从 EEA 的角度,这意味着 E2E 对计算节点之间的网络通信要求反而更简单——不需要多个域控制器之间来回传消息和同步中间状态。但代价是对单个计算节点的算力要求极端集中——这就是下一篇要讲的 2000 TOPS 的故事。

端到端的力量来自训练数据。但这些数据从哪里来?怎么筛选?为什么说这是一场"越跑越赢"的游戏?当 500 万辆车变成一张遍布世界的传感器网络,当"大海捞针"成为日常工程,数据飞轮的每一层都藏着残酷的竞争逻辑。
下一篇,我们拆开这个飞轮。
本文是"AI 定义汽车"系列(一)。下一篇:《数据飞轮:越跑越赢的残酷游戏》。
