 夜雨聆风
夜雨聆风阅读本文预计 8 分钟。
会介绍AI大神Karpathy为何不喜欢RAG!搞了LLM Wiki 的三层架构是什么?
怎么用这套方法管好你的知识!
前几天,Andrej Karpathy
OpenAI 联合创始人、特斯拉 AI 总监、百万粉丝的 AI 教育博主,发了一条推文,结果炸了!
1500 万浏览。
9 万收藏。
4.8 万转发。
你知道他发了什么吗?
不是代码。
是一套用 AI 管理知识的方法论。
而且他说了一句让很多人愣住的话——
"我现在 90% 的 token 都花在构建个人知识库上,而不是写代码。"
写代码的 Karpathy 跑去搞知识管理了!
在说 Karpathy 干了什么之前,先说个痛点。
你用 AI 读文档的场景,是不是这样的:
上传一堆 PDF → 问个问题 → AI 临时检索相关段落 → 生成答案
这套玩法叫 RAG(检索增强生成)。
用过就知道,问题贼明显
每次都在从零发现知识。
你问了一个问题,AI 临时拼凑答案,回复完了,这次探索就消失了。
下次问一个相关的复杂问题?
再重新拼一遍。
你读了 100 篇文章,AI 对这 100 篇的"理解"永远是零散的片段。
没有积累。
没有连接。
没有成长。
Karpathy 说:这条路可能从一开始就走偏了。

那换个思路呢?
Karpathy 的方案叫 LLM Wiki。
核心一句话:
让 AI 帮你编译和维护一个持久化的知识库,而不是每次临时检索。
你几乎不用自己编辑 Wiki——那是 AI 的领地。
你的工作是什么?
喂资料。
提问。
验证。
没了。
LLM Wiki 的架构分三层
听着复杂,但逻辑贼清晰。
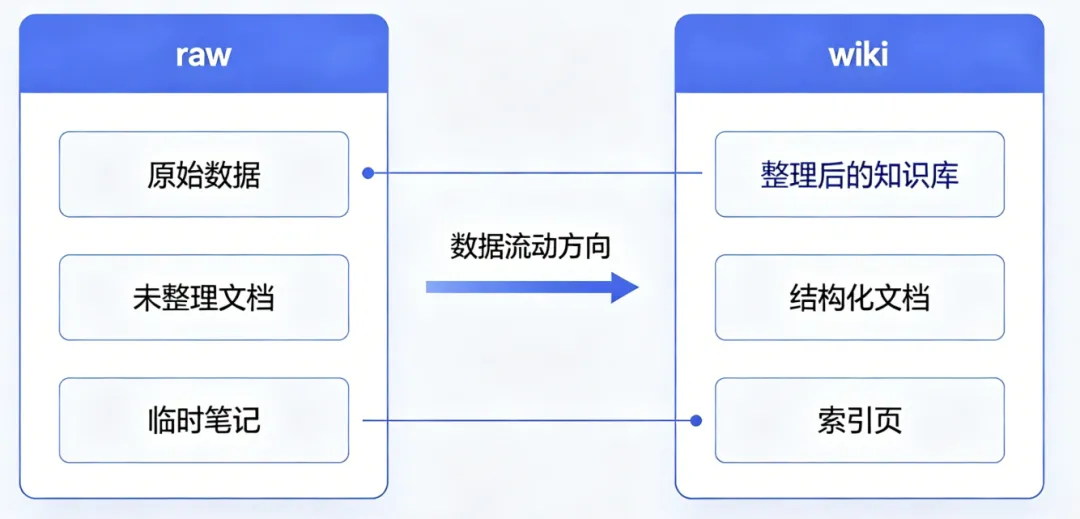
第一层:原始资料(Raw Sources)
你收集的文章、论文、播客笔记、图片,放在一个文件夹里。
如果未来升级,我觉得视频也可以放进来(我个人看法)
这里内容不可变。 AI 只读不写。
这是你的事实来源。
第二层:Wiki(知识库)
这是 AI 完全拥有和维护 的领地。
当你往 Raw Sources 里丢一篇新文章,AI 会:
读完全文 写一个摘要页 更新索引文件 增量更新相关概念页面 标注新旧信息可能矛盾的地方 在日志里记一笔
一篇资料,可能触发 10-15 个页面的更新。
这些页面之间自动建立交叉链接,形成一张知识网络。
关键点:知识是一次性编译好的,不是每次查询重新推导。
第三层:Schema(规则文件)
一个配置文件,告诉 AI:
Wiki 的目录结构怎么设计 不同类型的页面有什么格式要求 Ingest、Query、Lint 的标准流程是什么
这是把 AI 从"通用聊天机器人"变成"专业 wiki 维护员"的关键。
怎么打造这样的知识库?有三个核心操作。

Ingest(摄入)
把新资料丢进 Raw Sources → 告诉 AI 处理 → AI 完成上面说的那一套增量更新。
Karpathy 的建议:一次只处理一个,全程盯着。
前 5-10 篇是调校期,你会不断调整 Schema 让输出更符合你的预期。
Query(查询)
直接对着 Wiki 提问,AI 读取相关页面,综合回答。
输出的形式可以很多:Markdown、对比表格、幻灯片、图表
一个聪明的设计
如果你问了一个好问题,产生的答案本身也是有价值的。
Karpathy 说:
好的答案要归档回 Wiki,变成新页面(这个想法太棒了,我觉得这才是AI时代的知识库)
这样你的探索成果也会沉淀下来,而不是消失在聊天记录里。
Lint(健康检查)
定期让 AI 做 wiki 体检:
找出矛盾的数据 标记过时的结论 清理孤立页面 发现数据缺口 自动搜索补全空白
这就是为什么 LLM Wiki 能"自己长大"——Lint 会告诉你下一步该研究什么。
你可能会问:知识多了还是得检索啊,Wiki 怎么解决?
Karpathy 的秘密是两个文件:
index.md:内容索引,每个页面一行:链接 + 一句话摘要 + 标签。
AI 回答问题,第一步就读这个。
LLM 自己维护索引,质量随 Wiki 成长自动提升。
log.md:操作日志,按时间记录每次 Ingest、Query、Lint 操作。
grep 一下就能回溯:"上周我读过哪些相关资料?"
Karpathy 自己的规模是约 100 篇文章、40 万字。
这个量级,靠这两个文件 + LLM 自己的能力,完全不需要向量数据库。
社区经验来看,如果规模更大,可以用 qmd(本地 Markdown 搜索引擎,支持 BM25 + 向量混合搜索)。
项目地址:
https://github.com/tobi/qmd
那是后期的事。
真实案例:Farza 的"个人 Wikipedia"
有人已经把这套玩法跑起来了。
Farza(@FarzaTV)——把 2500 条日记 + Apple Notes 笔记 + 部分 iMessage 对话全部喂给 AI。
产出:关于自己的个人 Wikipedia,400 篇详细文章。
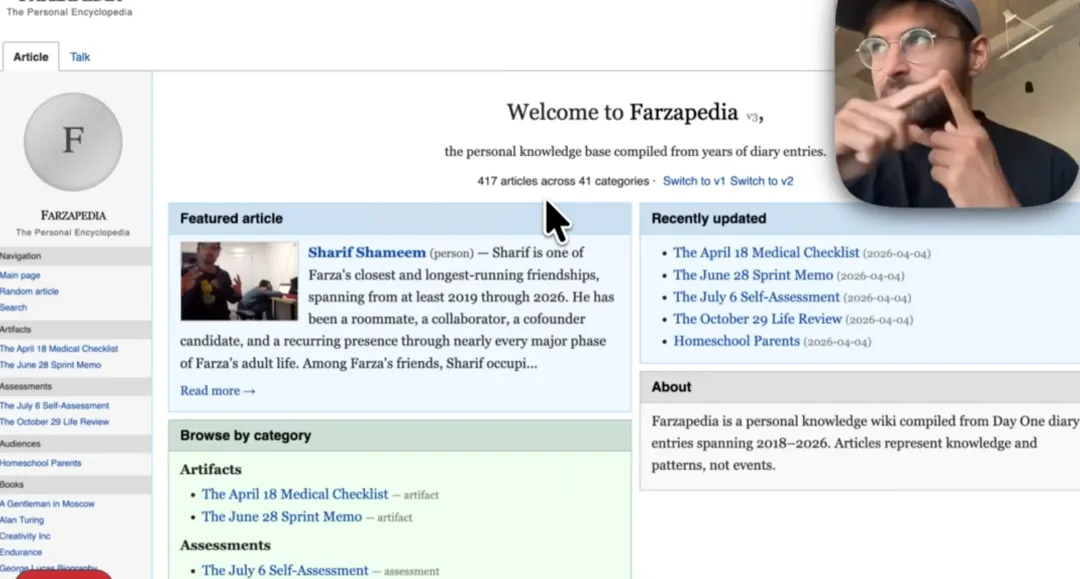
覆盖,朋友、创业项目、研究方向、动漫影响……所有文章之间有反向链接。
然后他让 AI Agent 对着自己的 Wiki 提问
"去看看最近启发我的图片和电影,给我文案和视觉方向的建议。"
Agent 从 Wiki 里翻出:吉卜力纪录片笔记、YC 公司落地页截图、1970 年代 Beatles 周边设计。
最后给出一套融合灵感的方案。
Farza 的评价很直接:之前用 RAG 做类似系统,"it was ass"(烂透了)。
资料来源:
https://www.linkedin.com/posts/farza-majeed-76685612a_this-is-farzapedia-i-had-an-llm-take-2500-activity-7446408553596166144-vwS2
和 RAG 到底有什么区别?
| 知识积累 | ||
| 知识更新 | ||
| 交叉连接 | ||
| 矛盾处理 | ||
| 维护方式 | ||
| 探索积累 |
本质上
RAG 是"用 AI 查资料"。
LLM Wiki 是"用 AI 建知识"。
一个是临时工。
一个是长期资产。
实测反馈:值不值得做?
有博主用 Cursor 完整实现了一套 LLM Wiki,跑了几天,结论比较实在:
优点:
提供了相对确定的核心框架 可作为基于 AI 的模糊查询搜索引擎 思想直接可用,Obsidian + 任意 Agent + Markdown 文件就够了
缺点:
高度依赖人工参与,实现效果取决于模型质量 Lint 功能较弱,高级功能难以完美实现 token 成本不可忽视,文档多了需要控制消耗 并非颠覆性创新,思路之前有人用过,但 Karpathy 提炼成了系统方法论
一句话评价:框架有价值,不要期待开箱即用的完美效果,需要持续优化。
其实80 年前就有人想到了
1945 年,Vannevar Bush 发表了一篇文章《As We May Think》,提出了 Memex 概念
一个个人知识设备,存储所有书籍和记录,能在任意两个条目之间建立永久链接,形成"思维路径"(trails)。
这套想法和 LLM Wiki 惊人地相似。
Bush 没解决的那个问题——谁来维护这个庞大的链接网络?
80 年后,LLM 补上了最后一环。
LLM Wiki 不是工具,是一种思路——
把 LLM 从"问答机器"变成"知识编译器"。
知识不是用来查的。
是用来编译和积累的。
这条思路值不值得践行,你自己判断。
但 1500 万人围观、9 万人收藏——
至少说明,这挠到了很多人的痒处。
有没有创业者在这方面?
期待好产品推出!
社区根据思路开源的项目推荐几个:
https://github.com/Benboerba620/karpathy-claude-wiki
https://github.com/Astro-Han/karpathy-llm-wiki
附:参考资料
Karpathy 原 Gist:
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
Farza 的 Farzapedia 帖子:
https://www.linkedin.com/posts/farza-majeed-76685612a_this-is-farzapedia-i-had-an-llm-take-2500-activity-7446408553596166144-vwS2
VentureBeat 报道:
https://venturebeat.com/data/karpathy-shares-llm-knowledge-base-architecture-that-bypasses-rag-with-an/
qmd 本地搜索引擎:
https://github.com/tobi/qmd
