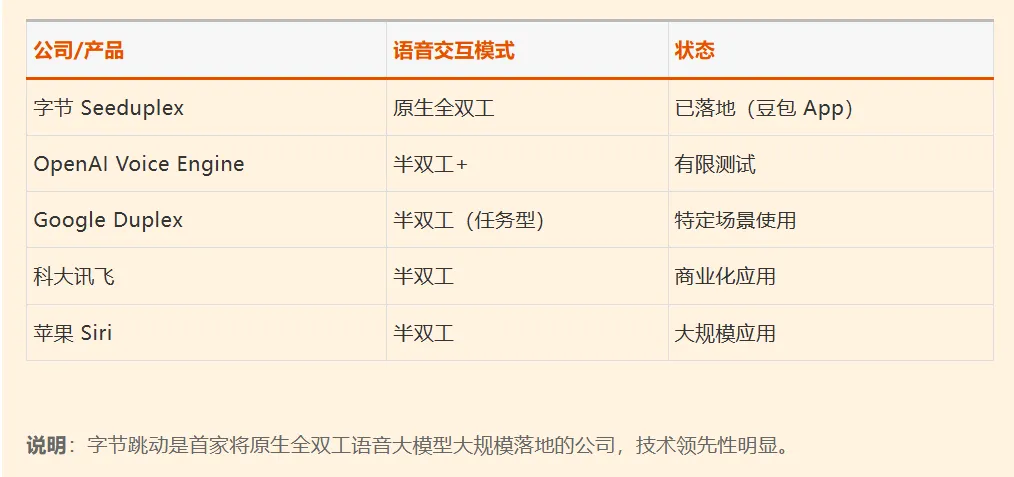
 夜雨聆风
夜雨聆风谁懂啊家人们!跟AI语音聊天,从来都是一场“忍耐力测试”——你刚停顿两秒想组织语言,它立马抢话打断;在奶茶店、地铁里开口,它要么把邻桌的闲聊当指令,要么直接卡壳装死;你说“等一下记个笔记”,它像没听见似的,自顾自念完剩下的内容。

我们要的是“对话搭子”,不是只会机械接话的“复读机”!
就在今天,字节跳动Seed团队悄悄搞了个大动作——原生全双工语音大模型Seeduplex正式发布,而且是全量上线豆包App!划重点:不是内测,不是灰度,不用蹲资格,上亿豆包用户升级到最新版本,点击右上角的电话图标,就能直接解锁这份“丝滑到离谱”的语音体验。
实测完我只有一个感受:那种和AI说话时如鲠在喉的机械感,终于被彻底磨平了。这一次,AI真的学会“像人一样听和说”了。而这件事,远比我们想象中更有分量——它意味着,全双工语音技术第一次真正走出实验室,实现了规模化落地,语音交互的“全民自然时代”,真的来了。
实测4个高频场景:这哪里是AI,分明是懂分寸的“真人搭子”
以前吐槽AI语音,核心就一个:不懂分寸。但Seeduplex的出现,直接把“分寸感”拉满。我们找了4个最贴近日常的场景实测,每一个都让人惊艳。
场景1:奶茶店聊周末计划,嘈杂环境也不“翻车”
周末约朋友出门,我在人声鼎沸的奶茶店,一边排队一边跟豆包聊行程:“帮我推荐一下近郊的短途游,不要爬山,适合拍照,车程不超过1小时。”背景里,店员的点单声、顾客的笑声、冰块碰撞的脆响混在一起,我刚聊到一半,店员喊我:“您好,您的三分糖珍珠奶茶好了,拿好慢走~”

换做以前的语音助手,要么把店员的话当成指令,要么直接卡壳。但豆包的表现彻底刷新认知:它没有抢话,安静等我接过奶茶、说完“谢谢”,立马顺着话题接:“推荐你去近郊的云栖小镇,有大片草坪和白色灯塔,车程40分钟,不用爬山,拍照巨出片,还能逛文创小店。”
Seeduplex的抗干扰,不是单纯“降噪”,而是能精准分辨“谁在对它说话”“哪句话是主线”,这已经接近人类的“交互意图识别”,就像和朋友聊天时,能自动过滤周围杂音。
场景2:雅思口语模拟,故意卡壳10秒,它居然不催
备考雅思的朋友都懂,口语练习最尴尬的就是“卡壳”。以前用语音助手模拟面试,只要停顿超过3秒,它就急着接话,把“模拟面试”变成“抢答比赛”。
这次我让豆包扮演雅思口语考官,问我:“Describe a time when you helped someone,and how did you feel?”我故意放慢语速,多次卡壳:“Well... um... Last month, I helped an old lady... um... she was lost in the subway station... Let me think... um... I helped her find her way to the exit...”全程卡壳三次,最长停顿10秒。
但豆包没有一次抢话,像有涵养的考官,安静听我组织语言,直到我说完,才不紧不慢追问:“Could you tell me more about how you helped her find the exit?”
Seeduplex的“动态判停”,不再只靠“静音时长”判断,而是结合语气、呼吸节奏等声学特征,以及是否在思考的语义状态综合判断——它不仅听你“有没有停”,还判断你“为什么停”,这就是全双工和半双工最本质的区别:不是“更快”,而是“更懂你”。
场景3:飞花令快问快答,零延迟对答,比朋友还默契
想测试AI反应速度,飞花令是“硬核考验”。我跟豆包玩“带‘花’字的诗句”,故意加快语速逼它“秒回”。
我:“人间四月芳菲尽,山寺桃花始盛开。”豆包:“接天莲叶无穷碧,映日荷花别样红。”——几乎话音刚落就回应,零延迟。我:“乱花渐欲迷人眼,浅草才能没马蹄。”豆包:“借问酒家何处有,牧童遥指杏花村。”我:“桃花潭水深千尺,不及汪伦送我情。”豆包:“待到重阳日,还来就菊花。”

更绝的是,我故意重复它的诗句,它立马秒回:“哈哈,你重复我的诗句啦~换一句哦,比如‘人面桃花相映红’。”这种上下文记忆和逻辑一致性,让对话充满“人情味”。
官方数据显示,Seeduplex相比半双工时延降低约250ms,实际体感就是“它在等你说完的那一刻,已经准备好了回答”,这种零延迟默契,越用越上瘾。
场景4:说到一半突然打断,它能秒收声、再续聊
最惊喜的细节的是,当豆包长篇大论时,你突然打断它,它能立刻收声,还能记住话题,等你忙完再继续。
我让豆包介绍成都美食,它正说:“成都必吃的美食有很多,比如火锅、串串、钵钵鸡,还有蛋烘糕、钟水饺……其中火锅一定要吃牛油锅底,搭配毛肚、鸭肠,七上八下涮15秒,口感最脆……”
我突然打断:“等一下,我记个笔记,把你说的火锅搭配记下来。”话音刚落,豆包瞬间收声,还贴心问:“需要我把刚才说的火锅搭配再重复一遍吗?方便你记笔记~”等我说完“不用啦,继续说”,它立马从“钟水饺”接着讲,衔接丝毫不生硬。
这种“被打断—收声—等待—继续”的闭环,以前只有和真人打电话才能体验到,现在豆包也做到了。
Seeduplex凭什么?拆解它的“硬核实力”
惊艳体验的背后,是Seeduplex解决了传统语音AI的三大硬伤,啃下了全双工技术的两块“硬骨头”。
我们以前用的语音助手,本质上都是“半双工”——你说一句,它听;它说一句,你听,像老式对讲机,天生有三个硬伤:反应慢,必须等你说完才处理;难打断,它说话时听不见你;易误判,分不清噪音和指令。
而全双工,就像打电话——你和它可以同时说、同时听,靠“对话节奏感”自然流转。这要求AI每毫秒同时做三件事:听你说、想答案、判断要不要开口,难度极大,而字节Seed团队做到了极致。

第一块硬骨头:精准抗干扰,告别“环境噪音翻车”
Seeduplex的抗干扰是“主动识别”,能持续解析声学环境,自动忽略噪音和无关对话。官方测试显示,复杂场景下,它的误回复率、误打断率比传统半双工模型减少一半。
核心技术是它抛弃了“语音转文字再理解”的流水线,直接对原始音频信号做特征提取,能在声学层面分辨“哪句话是冲我来的”,反应更快、识别更精准。比如在地铁里,再嘈杂它也能精准捕捉你的指令。
第二块硬骨头:动态判停,懂你的“停顿与思考”
人与人对话时,我们会通过语调、呼吸节奏判断对方是否说完,Seeduplex把这些“隐性信号”内化进模型训练,结合语音和语义特征综合判断你的状态。
因此,它的抢话比例比传统半双工模型下降40%——不催你思考、不卡壳时抢话、不停顿记笔记时自顾自念,这种“懂分寸”,才是全双工的核心价值。
不止是模型:从技术到工程,全链路打通的“工业级系统”
把全双工做成Demo不难,难的是全量上线、扛住上亿用户并发。Seeduplex能实现,背后是字节团队的工程极致打磨,重点攻克四件事:
1. 模型框架重构:抛弃“ASR→LLM→TTS”三段式拼接,构建端到端架构,延迟大幅降低;
2. 训练体系升级:海量数据预训练+多任务后训练,协同优化五项核心能力;
3. 推理性能压榨:用投机采样、量化技术,平衡成本与延迟;4. 服务稳定性兜底:解决收音、播报卡顿等问题,确保大流量不翻车。
一句话总结:Seeduplex不是“花架子Demo”,而是从模型到工程全链路打通的工业级系统,这也是它能领先行业、实现规模化落地的关键。
刷新行业SOTA:不止赢了上一代,更领跑全行业
数据更有说服力,Seeduplex的表现堪称惊艳,不仅碾压豆包上一代半双工框架,还领先行业主流App语音功能。
和上一代对比:判停MOS分(用户体验评分)提高8%,对话流畅度MOS分提升12%,判停延迟降低约250ms,抢话比例下降40%,复杂场景误回复、误打断率减半,打断响应延迟缩短约300ms。
行业横向对比:它在“判停准确性”“打断流畅度”“对话自然度”三项核心指标上均领先。
团队做的“人机对话vs人人对话”测试很有戏剧性:响应打断上,Seeduplex比真人更稳定;整体流畅度上,虽和真人有差距,但已让语音交互离自然类人对话近了一大步——它不用比真人厉害,只要和真人一样懂分寸,就赢了。
不止是豆包好用:全双工,正在重构整个语音交互产业
Seeduplex的价值远不止让豆包好用,当AI学会“边听边说、懂分寸”,整个语音交互产业都将被重构。我们先看语音大模型的演进路线:
第一阶段:级联时代,ASR、LLM、TTS各干各的,体验生硬;第二阶段:端到端实时语音时代,以GPT-4o、Gemini Live为代表,解决低时延,但仍未摆脱回合制问答;第三阶段:原生全双工时代,解决真人交流核心痛点,而Seeduplex是率先踏入这个阶段并实现规模化落地的玩家。
全双工普及后,多个行业将被深刻影响:
1. 车载场景:开车聊天,终于不用“小心翼翼”
开车时用语音助手,都是“随口问”,比如“导航到最近的加油站”“调整空调到24度”。以前的半双工AI易误判、抢话,影响安全。Seeduplex的抗干扰和动态判停,能稳住主线,你被路况打断时它会等待,不用反复喊唤醒词,安全又省心。
2. 教育场景:口语陪练,终于告别“假交流”
雅思口语、少儿英语启蒙等,最忌讳“假交流”。以前的陪练机械出题、打分,卡壳时催你,毫无互动感。Seeduplex能理解你的犹豫、等待你思考,像真人老师一样配合节奏,让练习更自然沉浸。
3. 客服与企业服务:复杂对话,终于能“稳住节奏”
高价值语音客服,核心是能在复杂场景稳住对话。以前的AI易翻车,要么听不懂插话,要么打断客户宣泄。Seeduplex能精准分辨需求和情绪,稳住节奏,先安抚再解决问题,大幅提升效率和体验。
除此之外,会议纪要、老人陪伴、智能硬件等场景,也会因全双工技术变革。Seeduplex把全双工从“概念”变成“实用工具”,推向更多高频场景。
语音交互的“GPT-3.5时刻”,终于来了
我大胆判断:Seeduplex的全量上线,就是语音交互领域的“GPT-3.5时刻”。
GPT-3.5被记住,不是因为最强,而是第一次让普通人觉得“和AI对话有用”,让大模型从极客玩具变成大众工具。Seeduplex异曲同工——它第一次让普通人觉得“和AI说话自然”。
在此之前,语音AI只是“能用”,我们要迁就它;Seeduplex之后,AI迁就我们,语音交互从“任务式对话”变成“自然聊天”。当机械感被磨平,语音AI的应用爆发才刚刚开始。
更深一层,全双工的本质是AI第一次拥有“对话流控制能力”——知道什么时候听、说、停、等,这是AI从“工具”走向“伙伴”的必经之路。
写到最后,我又点开豆包,跟它说:“今天聊得挺开心的,谢谢你呀。”它停顿半秒——那种恰到好处的、像人一样的半秒,然后温柔说:“不客气呀,不管是聊天、问问题,还是想吐槽,我都随时在~”
那一刻我意识到,有些技术革命,就在不经意间改变生活。现在打开豆包,点击电话图标你会发现:AI,终于学会像人一样听和说了。而这,只是一个开始。
❤️ 觉得这份体验惊艳的朋友,麻烦点赞+在看,把这份“丝滑语音体验”分享给身边的人,让更多人告别AI语音的机械感~也可以在评论区留言,说说你最想用它做什么?
