 夜雨聆风
夜雨聆风20
25
INVITATION·WELCOME YOU
你会更相信长着
“人脸”的AI嘛?
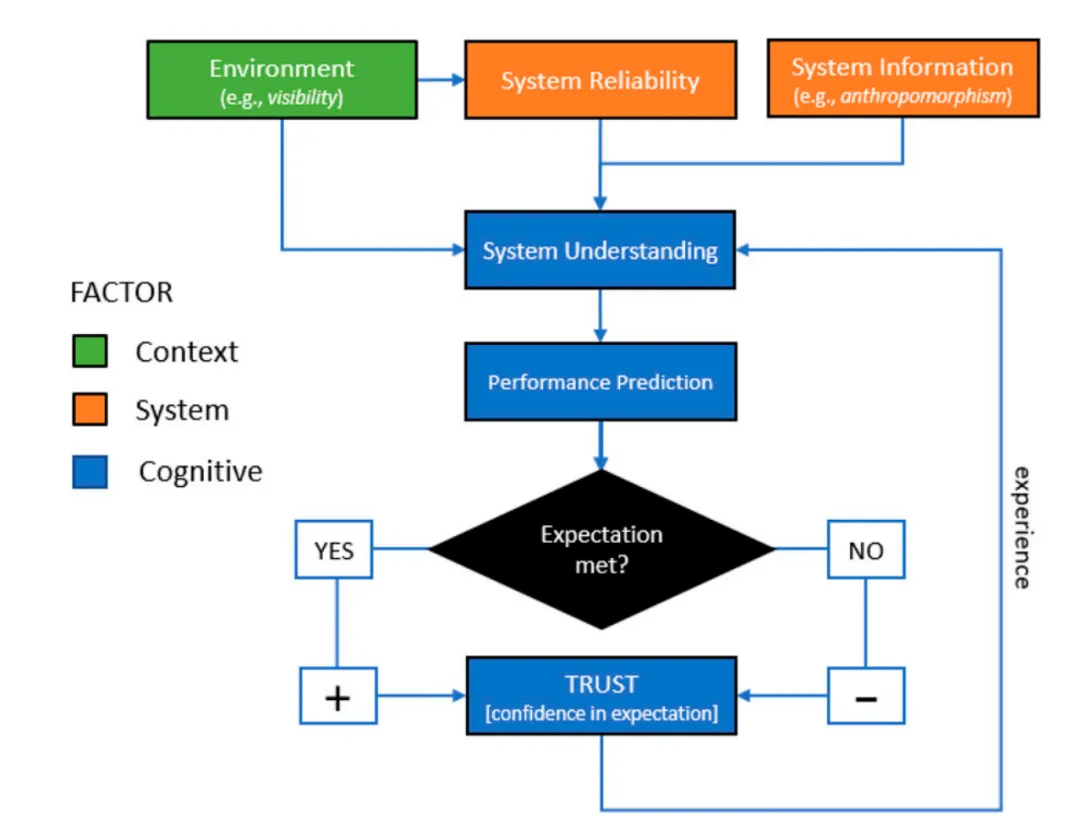
人-自动化信任期望模型

INTRODUCTION
你有没有因为一个机器人“长得像人”就莫名觉得它更靠谱?或者因为语音助手说话温柔,就更容易接受它的建议?
这背后是拟人化(anthropomorphism)在影响我们的判断,它能增进人对自动化的信任。毕竟,我们天生更擅长与人打交道,机器越像人,理应越可信。
但学术圈对此争议不断。有的研究发现拟人化确实提高了主观信任;有的发现毫无效果,甚至适得其反——机器人那张“脸”反而让人分心。
最近,一篇发表于《Human Factors》的论文给出了一个清晰的理论解释和实证答案。它不仅厘清了“拟人化何时有效”,还提出了一个可检验的模型——人-自动化信任期望模型(HATEM)。
01
假设建立:
信任的本质是预测误差
研究者Carter等人提出:人对自动化的信任,本质上是对自动化性能的“预测能力”。换句话说,你越能预判它什么时候会犯错,你的信任就越校准(calibrated);反之,你总是被它的错误“惊喜”到,信任就会崩塌。
这听起来有点像谈恋爱?不,这其实是认知科学中的“预测加工”理论:人脑就是一台预测机器,不断根据经验修正对世界的预期。自动化信任也一样——信任校准 = 预期可靠性 vs. 实际可靠性之间的差距。
HATEM模型的精髓在于:任何影响信任的因素(外观、可靠性、透明度等),都必须通过帮助用户更准确地预测自动化错误这一渠道才能发挥作用。

那么,拟人化呢?该模型做出两个尖锐预测
H1:表面拟人化(如加个人脸、起个名字)如果不传递有用信息,只能短暂提高主观信任,对行为信任(实际使用准确率)无益。
H2:只有那些能自然主义地传达上下文有用信息(比如明确表达“我确定”或“我不确定”)的拟人化特征,才能真正改善信任校准。
02
实验设计:语音语调操纵
研究者招募了98名大学生,让他们操作一个潜艇潜望镜模拟器,判断过往船只的类型(军舰/商船)和航向。任务有一定难度(能见度分三级),AI助手“SAM”提供建议,但SAM的整体准确率只有50%。
自变量操纵1:外观拟人化
高拟人化:一个经过预实验筛选、看起来最“能干且可信”的机器人头像(Avatar)。
低拟人化:一个冰冷的摄像头眼睛(Eye),几乎无人特征。
自变量操纵2:语音语调
单调(monotone):毫无感情的机械声。
无意义(meaningless):语调有升有降,但随机出现,与SAM是否准确无关——只是“听起来像人”,但不传递信息。
有意义(meaningful):当SAM对自己的判断确定时,用降调;当不确定时,用升调。这自然主义地传达了自动化当前的可靠性。
另外,所有参与者都知道SAM在清晰视野下100%准确,雾天0%准确,等等——这些背景信息是公开的。



03
结果:
语调有意义才有用
拟人化感知:成功了,但没用
通过“Godspeed拟人化量表”测量,参与者确实认为有意义和无意义语调都比单调更拟人,且后续补充实验证明:在被试内设计下,Avatar比Eye更拟人。但在被试间设计(本实验主设计)中,外观差异未被察觉——这本身已说明,外观对信任的影响微弱。
从实验结果来看
主观信任(TOAST问卷):Avatar vs. Eye无差异;有意义语调 > 单调语调,但无意义语调与单调无显著差异。
信任校准(行为指标):用信号检测论的d'衡量——即参与者恰当采纳正确建议、拒绝错误建议的能力。结果:有意义语调的d'远超单调和无意义,后两者之间无差异。贝叶斯因子显示,证据是“决定性的”(BF₁₀ > 1e23)。
接受建议时的信心:同样,有意义语调显著更高,且随时间推移持续提升;单调和无意义则无提升。
时间效应:只有“有意义”组越用越准
研究者将96次试验分为6个时段。有意义组在第一个时段到最后一个时段,信任校准和信心均有显著进步(BF=16.7和7.46);而单调和无意义组均无进步。这印证了HATEM的预测:只有提供可预测信息,经验才能优化信任。
相关性:客观与主观信任一致
整体上,信任校准(d')与接受建议时的信心呈正相关(r=0.546,BF>1e5),且有意义组的相关系数最强。这说明这些测量具有聚合效度。
04
总结讨论:
你可能会问:无意义语调也有升有降,听起来也很“人”,为什么不行?
因为它不传递任何关于自动化可靠性的信息。参与者无法根据语调预判SAM是否会犯错。换句话说,这种拟人化只是“表面社交”,如同一个永远用疑问句说话的人,你很快会忽略他的所有建议。
而有意义语调则把语调变化变成了可靠性信号:降调=大概率正确,升调=小心。参与者可以据此调整自己的行为——这才是真正的“沟通”。
关于这个研究另一个有趣的点是,一般认为AI准确度在70%以下就会大大降低用户的不信任度,但从本实验可以看出,低可靠性未必是问题。本实验中SAM只有50%准确率,但有意义语调组依然建立了良好的校准信任。可预测性比高可靠性更重要。
HATEM模型则重新定义了信任:信任校准程度 = 预期可靠性 vs. 实际可靠性之间的差距(预测误差)。用户真正需要的不是“永远正确”的AI,而是“我能预判你何时会犯错”的AI。
与其追求一个永远不会犯错的神,不如培养一个会诚实地告诉你“这次我可能不行”的队友。
这才是人机协作未来的正确方向。
参考文献
Carter, O. B. J., Loft, S., & Visser, T. A. W. (2024). Meaningful Communication but not Superficial Anthropomorphism Facilitates Human-Automation Trust Calibration: The Human-Automation Trust Expectation Model (HATEM). Human Factors, 66(11), 2485–2502.
ZJUpsy@喻晨宁供稿
