 夜雨聆风
夜雨聆风AI文献检索真的靠谱么
现在,AI 知识库产品几乎成了标配。
从 NotebookLLM、AnythingLLM,到 Cherry Studio 的知识库功能,再到 Flowith 的“知识花园”,叙事几乎一致:接入 Zotero、PDF、笔记,让 AI 基于你的资料回答问题。
这件事,确实比直接问 AI 更进一步。
但一个更关键的问题是——这些看起来结构严谨、逻辑清晰的回答,究竟是真的“来自你的资料”,还是只是“像是来自你的资料”?
界面不同,四步流程都一样
市面上这些AI知识库产品,无论界面怎么不同、卖点怎么差异化,核心技术路线都叫 RAG(Retrieval-Augmented Generation,检索增强生成)。
整个流程分四步:
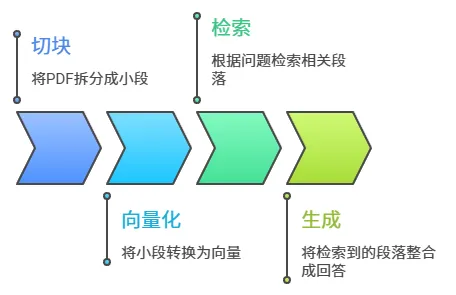
第一步:切块(Chunking)把你的PDF拆成若干小段,通常每段200-500个词。
第二步:向量化(Embedding)把每个小段转换成一串数字(向量),存进数据库。意思相近的段落,对应的数字也相近。
第三步:检索(Retrieval)你提问时,系统把问题也转成向量,在数据库里找出数字最接近的那几段内容,拉出来。
第四步:生成(Generation)把检索到的那几段内容塞进AI的上下文,让它整合成一段回答。
所以当产品说"2100篇文献、2分钟内检索",描述的是第三步有多快。这一步确实不慢,也不是问题所在。
问题在其他三步。
文献被切成块的那一刻,上下文就断了
假设你有一篇论文,Methods部分写了"采用随机森林方法",Results部分两页后写了"模型预测精度R²=0.81"。
在切块时,这两段内容大概率落进了两个不同的chunk。
检索时,如果你问"这篇文章用的什么方法",系统拉回来的是Methods那个chunk;如果你问"精度怎么样",拉回来的是Results那个chunk。但没有任何机制保证这两个chunk会同时出现在同一次回答里。
AI可能拿着"随机森林"这段内容,结合另一篇文献里的精度数据,拼成一个听起来完整的答案。不是AI编造了什么,是切块这个步骤本身破坏了上下文的连续性1。
找到了,不等于找对了
向量化(Embedding)的作用是把文字变成坐标:意思相近的内容,坐标也相近,检索时就能被优先找到。
但有一个精度陷阱。
如果一个chunk同时覆盖多个主题——比如一段话里既讨论了采样方法,又讨论了精度验证——那它对应的向量坐标会落在所有这些主题的模糊中间位置。
当你的问题是"采样方法"时,这个chunk的坐标和问题坐标之间的距离,可能比一个专门讲采样的纯净chunk更远。结果就是:信息在库里,但没被检索到2。
塞进去的内容,AI不一定都在读
哪怕检索步骤没出问题,把多个chunk塞进AI上下文时,还有另一个被实验反复验证的问题:"Lost in the Middle"(中间内容丢失)效应。
AI在处理长上下文时,对开头和结尾的注意力明显高于中间。如果检索到5个相关chunk,第3个chunk里恰好有最关键的数据,AI大概率会忽视它3。
最后这步才是真正的黑箱
前三个问题都有迹可循,这一步才是真正麻烦的地方。
生成(Generation)是整个RAG流程里错误率最高、也最难被发现的环节。AI拿到几个检索到的chunk之后,要把它们整合成一段连贯的回答。在这个过程中,最常见的错误模式是跨文档混搭:
- 文章A描述了随机森林方法
- 文章B报告了R²=0.81
- AI生成:"该研究采用随机森林方法,预测精度R²=0.81"
数字是真的,方法是真的,引用格式也正确,就是两件事来自两篇不同的文章,被拼在了一起4。
这种错误没有任何报错信号。不逐句回原文核对,根本发现不了。
改进版RAG系统经过多证据优化后幻觉率可以降低40%以上,但在标准的医学问答任务上,最终准确率仍只有79.13%5。学术综述的合成任务比问答复杂得多,且没有现成的标准答案来检验对错。
来自你的库,反而更容易信
直接问AI,它可能给你一篇不存在的文献,DOI是假的,作者名是拼出来的。这种幻觉你会怀疑,因为来源无法核实。
但RAG的问题不一样。
检索到的chunk来自你自己的Zotero库,引文格式完整,数字真实存在,语言逻辑通顺。正因为有"来自你的库"这个背书,核对的欲望反而降低了。
这才是真正的坑:不是AI编造了内容,而是AI把真实的碎片以一种看起来合理的方式拼成了错误的整体,而你因为信任来源,没有核对。
它能做的事,比宣传的窄很多
说了这么多,不是要说这类工具没用。
它真正能做好的事情是缩短"在大量文献里找方向"的时间:快速定位某个主题大概集中在哪几篇,判断哪些文献值得精读。这个价值是真实的。
但它不能替代的是:看原文这件事本身。
把它当成一个智能的文献索引系统,而不是综述代写机器——边界划清楚了,用起来才不会出问题。
每次AI给出文献支撑的结论,过一遍:
① 数字必须回原文对任何数值(R²、p值、样本量、时间范围、浓度),打开PDF找到原句逐一确认,这步不能省。
② 核查方法和结果是否来自同一篇文章AI说"某研究用了X方法得到Y结果",先确认X和Y来自同一篇文章,不是两篇内容被拼在了一起。
③ 综合性结论分别溯源AI把多篇文献整合成一段话,这段话里的每个具体说法,单独确认出处。不能因为整段话"来自你的库"就整体信任。
④ AI没提到≠那里没有内容检索有盲区,重要论点还是要手动搜一遍,不要因为AI没提就认为文献里没有相关内容。
⑤ 综合性总结只作索引,不作引用依据AI把多篇文献合并总结的那段输出,用来定位"应该重点精读哪几篇",这段总结本身不能直接进稿子
引文
Cross-Document Topic-Aligned Chunking for Retrieval-Augmented Generation. arXiv, 2025. 原文:when queries require synthesizing facts from multiple documents, traditional methods retrieve fragments each containing signal embedded in document-specific noise.
Brenndoerfer M. Document Chunking: Optimizing RAG Retrieval Pipelines. 2026. 原文:precision degrades not because the information is absent, but because it is diluted.
Solving the 'Lost in the Middle' Problem: Advanced RAG Techniques for Long-Context LLMs. Maxim AI, 2025. 原文:large language models struggle to effectively use information located in the middle of long contexts, posing significant challenges for RAG systems.
Hallucination Mitigation for Retrieval-Augmented Large Language Models: A Review. Mathematics, MDPI, 2025. 原文将此类问题定义为 context-generation alignment failure,即生成文本与检索内容之间出现内容或逻辑偏差。
MEGA-RAG: a retrieval-augmented generation framework with multi-evidence guided answer refinement for mitigating hallucinations of LLMs in public health. Frontiers in Public Health, 2025. 原文:achieving the highest accuracy (0.7913), precision (0.7541), recall (0.8304), and F1 score (0.7904).

