 夜雨聆风
夜雨聆风人类一直在想「造人」
用一组模块拼出一个完整智能体,这件事的源头比深度学习古老得多。
1982年,卡内基梅隆大学的 Allen Newell 和他的学生 John Laird、Paul Rosenbloom 在一栋灰色的学术楼里,造出了 Soar——人类历史上第一个真正意义上的「认知架构」。Soar 的野心是定义一组「固定的计算构建块」,然后用这些块组装出通用的智能行为。它有工作记忆、有产生式规则、有通用子目标机制,本质上是在模拟人类怎么从感知到思考再到行动。
几乎同一时期,同校的 John R. Anderson 开发了 ACT-R(Adaptive Control of Thought–Rational),一个混合认知架构。ACT-R 把人类心智拆成模块:视觉模块处理看到的东西,陈述性记忆模块存储知识,程序性记忆模块处理技能。每个模块各司其职,又通过「缓冲区」彼此通信。
Soar 偏工程——它想造一个通用AI系统;ACT-R 偏科学——它想解释人类认知。但两者的核心思路惊人地一致:把智能拆解成功能模块,再用一套协调机制把它们串起来。
这和我们今天讨论的主题——LLM当大脑、视觉模型当眼睛、Agent当手脚——在哲学层面上是同一件事。只不过1980年代没有Transformer,没有大规模数据,也没有足够的算力。Soar 和 ACT-R 只能在小规模任务上验证概念,离「像人类一样」差了十万八千里。
但种子已经种下了。
2012-2019:深度学习各走各的路
2012年,AlexNet 在 ImageNet 上一战成名。此后几年,深度学习的各个分支像高速公路上的车流一样,各自往前冲,互不相干。
计算机视觉领域,从 AlexNet 到 VGG、GoogLeNet、ResNet,一年一个突破。到2015年,图像分类的准确率已经超过人类。
自然语言处理领域,从 Word2Vec 到 LSTM、GRU,再到2017年的 Transformer——Google 那篇「Attention Is All You Need」改变了整个游戏规则。
语音领域,深度学习同样在快速推进。2014年 DeepMind 发布了 Deep Speech,2016年百度的 Deep Speech 2 把语音识别错误率降到了接近人类水平。
这些进步都是单模态的。图像模型只看图,语言模型只读文,语音模型只听声。每条赛道都在飞速进步,但彼此之间没有对话。
像一个幼儿园里的小朋友,有的擅长画画,有的擅长说话,有的听力特别好,但他们还不会合作完成一个项目。
转折点在2020年前后。
2020-2021:多模态的第一次握手
2020年6月,OpenAI发布了GPT-3。1750亿参数,在语言任务上展示了惊人的few-shot能力。它不是视觉模型,不能看图不能听声音,但它的「泛化能力」让人们第一次感觉到:也许一个足够大的语言模型可以成为某种「通用推理引擎」。
同年,OpenAI还在默默做另一件事——训练CLIP。这个模型用4亿个图像-文本对做对比学习,让视觉和语言第一次在表征空间里对齐了。你给它一张照片,它能用自然语言描述看到了什么;你给它一段文字,它能找到对应的图像。
2021年1月,OpenAI同时发布了DALL-E和CLIP。DALL-E(12亿参数的GPT-3变体)可以根据文字描述生成图像。CLIP则实现了零样本图像分类——不需要针对特定任务训练,直接用自然语言指令就能完成分类。
这两件事的意义在当时可能被低估了。人们被DALL-E生成的「牛油果形状的椅子」惊艳到了,忙着玩文字生成图片。但更深层的变化是:多模态之间的墙开始裂开了。视觉和语言不再是两个独立的世界,它们找到了一种共享的「语言」。
同一时期,DeepMind的Flamingo(2022年)展示了few-shot多模态学习的能力——只需要少量示例,就能让模型理解图片和文字之间的复杂关系。
这些是「感官融合」的第一步。眼睛和嘴巴开始学会同一种语言了。
2022:Agent的元年
2022年发生了一件改变一切的事:11月30日,ChatGPT上线。
五天,100万用户。两个月,1亿用户。全球震动。
但ChatGPT只是催化剂。真正开启「AI Agent」时代的是三个学术上的突破和三个开源项目。
学术突破:
第一,ReAct(Reasoning + Acting)。2022年,普林斯顿和Google的研究者提出了这个框架——让语言模型在推理和行动之间交替。不是单纯地思考,也不是盲目地行动,而是「想一步、做一步、根据结果再想」。这成了后来几乎所有Agent框架的基础范式。
第二,Toolformer。Meta在2022年底展示了语言模型可以学会自己调用API——搜索引擎、计算器、翻译工具。模型不再是孤岛,它可以伸出手去触碰外部世界了。
第三,Chain-of-Thought(思维链)。Google在2022年初提出,通过在推理过程中展示中间步骤,大模型能解决更复杂的问题。这为Agent的「规划」能力提供了方法论。
开源项目:
2023年3月,一个叫Toran Bruce Richards的开发者发布了AutoGPT——一个用GPT-4驱动的自主Agent。你给它一个目标(比如「调研电动汽车市场并写一份报告」),它就会自己去搜索网页、整理信息、写文件,全程不需要人类干预。AutoGPT成了GitHub历史上增长最快的仓库之一。
两周后,Yohei Nakajima用大约100行Python代码写了BabyAGI。它的核心循环极其优雅:创建任务 → 执行任务 → 根据结果创建新任务 → 重复。就这么简单,但它展示了一个基本的自主智能体需要什么:目标分解、记忆管理、迭代执行。
几乎同时,AgentGPT提供了一个浏览器界面,让不懂代码的人也能创建和运行自主Agent。
2023年春天被后来的人称为「Autonomous Agent Summer」。这三兄弟虽然粗糙、容易跑偏、经常死循环,但它们证明了一件事:大语言模型可以当一个智能体的「大脑」,指挥其他模块去感知和行动。
从这个时候起,LLM=大脑、工具=手脚这个隐喻不再是哲学讨论,而是工程实践了。
2023-2024:框架大战与多模态大爆发
AutoGPT和BabAGI点燃了火,接下来行业要做的是把火变成引擎。
Agent框架爆发:
LangChain(2022年底由Harrison Chase创建)从一个简单的「LLM调用链」工具,迅速演变成最成熟的Agent编排框架。它的核心理念是用链(Chain)把各种组件串起来——LLM、工具、记忆、数据源。
CrewAI走了另一条路——角色扮演。你定义一组Agent,每个Agent有角色、目标和工具,然后让它们像团队一样协作。一个负责调研,一个负责写作,一个负责审核。
微软的AutoGen则专注于多Agent对话——让多个Agent之间进行结构化的交流来解决问题。
这三家代表了Agent编排的三种哲学:流程驱动(LangChain)、角色驱动(CrewAI)、对话驱动(AutoGen)。
多模态大模型:
2023年3月,GPT-4发布。它不只能读文本,还能看图片。你可以给它一张冰箱照片,问「我能做什么菜」,它会根据食材给出菜谱。GPT-4V(视觉版)是人类第一次拥有一个能同时理解和生成文字、分析图像的生产级模型。
2023年12月,Google发布了Gemini——从设计之初就是多模态的模型(文本、图像、音频、视频),不是把视觉模块「接」到语言模型上,而是在底层统一处理。
这条路线和「组装」路线形成了一个有趣的对比:端到端多模态 vs 模块化组合。前者像一个天生的多面手,后者像一个精心组建的团队。
2024年5月,OpenAI发布了GPT-4o(「o」代表omni,全能)。320毫秒的语音响应延迟,实时视觉理解,文字、语音、图像在一个模型中无缝切换。第一次,一个AI系统能用接近人类的速度和方式同时看、听、说。
Computer Use和工具使用:
2024年10月,Anthropic发布了Claude Computer Use——Claude可以通过截图来操控电脑:移动鼠标、点击按钮、输入文字。2025年1月,OpenAI发布了Operator,一个可以自主浏览网页、填写表单、完成购物的AI Agent。
Google的Project Mariner也在同期推进,让Gemini能够自主操作浏览器。
这些进展意味着AI的「手脚」已经伸进了人类最重要的数字工具——电脑和浏览器。
2024年末-2025年:协议与标准化
如果说2023年是Agent的元年,2024年是框架大战年,那2025年就是标准化年。
MCP(Model Context Protocol):
2024年11月,Anthropic发布了MCP——一个开放标准,让AI模型可以安全地连接外部数据源和工具。就像USB接口统一了设备连接一样,MCP想让Agent连接工具这件事变得标准化。到2025年中期,OpenAI、Google、Hugging Face都采纳了MCP。Anthropic后来把MCP捐赠给了Linux基金会旗下的Agentic AI Foundation。
Google A2A(Agent-to-Agent)协议:
2025年4月,Google在Cloud Next大会上发布了A2A协议——让不同厂商、不同框架的Agent之间可以互相发现、通信和协作。如果MCP解决的是「Agent怎么连工具」,A2A解决的就是「Agent怎么连Agent」。
OpenAI Agents SDK:
2025年3月,OpenAI发布了开源的Agents SDK——一个轻量级的Python框架,用来编排多Agent工作流。它是对之前Swarm实验的正式化。
Apple Intelligence:
Apple在2024年发布了Apple Intelligence,2025年进一步开放了Foundation Models框架给开发者。它的路线很独特:~3B参数的设备端模型处理日常任务,更大的服务器端模型处理复杂推理,两者通过Private Cloud Compute协调。Apple的路线代表了「隐私优先的分布式AI中枢」——不是所有智能都在云端,而是尽可能在本地完成。
这一时期的核心变化是:从「能不能做」变成了「怎么标准化地做」。各大公司不再只是展示酷炫的Demo,而是在制定游戏规则。
2025-2026:碎片整合的攻坚期
到了我们正在经历的当下,「组装一个AI中枢」这件事已经不再是幻想。但就像拼乐高一样,零件有了,图纸也有了,拼出来的东西离「像人」还有多远?
答案是:有些部分已经很接近人类,有些部分还差得远。具体分析见横向部分。
这个阶段最值得关注的新趋势:
实时多模态交互成为标配。GPT-4o、Gemini 2.5、Claude都支持实时语音+视觉+文字的混合交互。延迟从秒级降到了百毫秒级。
端到端模型在蚕食模块化方案的地盘。GPT-4o用一个模型同时处理文字、语音和图像,而不是分别调用三个模型再拼接结果。这条路线的效率更高,但灵活性更低。
具身智能开始落地。Tesla Optimus在工厂里搬运零件,Figure的机器人在BMW车间里干活,Agility Robotics的Digit在Amazon仓库里搬箱子。AI的「身体」正在从模拟器走进物理世界。
RAG从向量检索进化到知识图谱。纯向量检索的RAG只能做模糊匹配,GraphRAG加入了关系推理,HybridRAG把两者结合。AI的「记忆」正在从「印象模糊」变成「有据可查」。
四十年的回路:Newell在1982年用Soar构想的「模块化智能架构」,到2026年终于有了真正能用的零件。从符号推理到神经网络,从单模态到多模态,从API调用到自主Agent,从实验室Demo到工厂里的机器人。路径变了无数次,但目标始终没变——像人类一样,把感知、思考、记忆、行动组装成一个整体。
当前「模型类别」
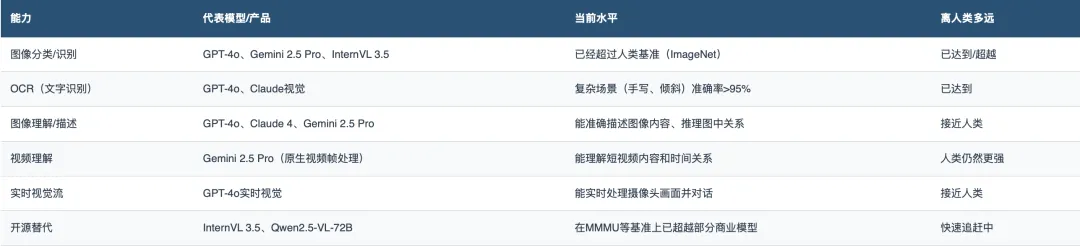
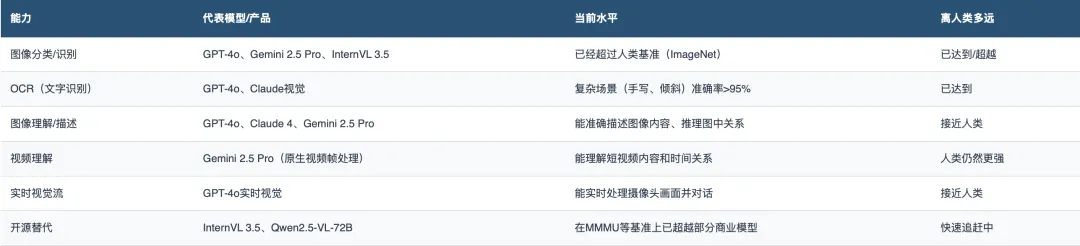
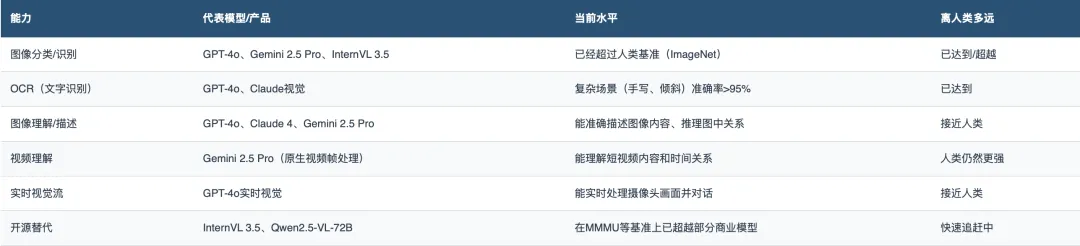
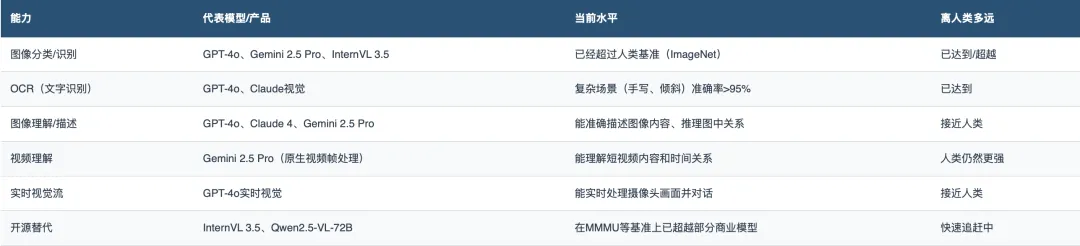
1.视觉(眼睛)
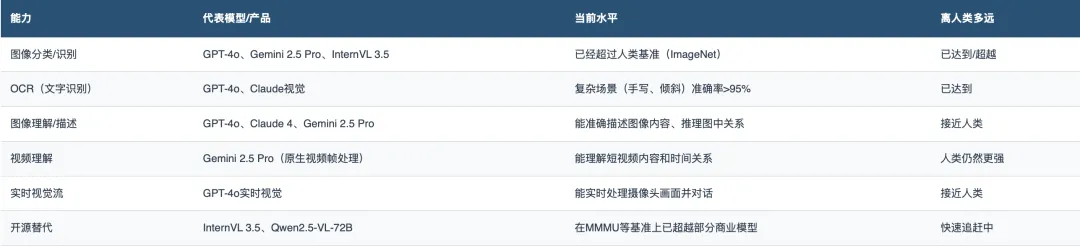
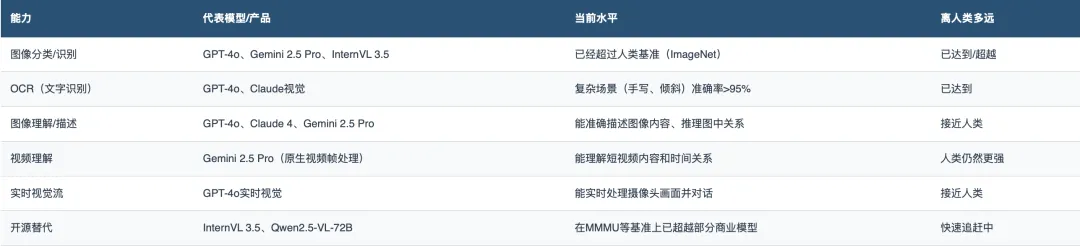
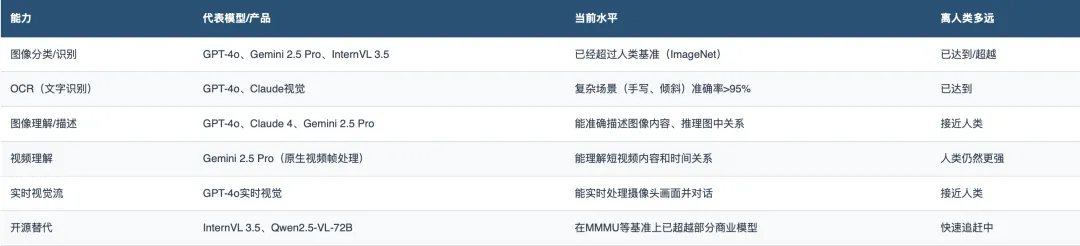
视觉是目前AI最成熟的感知能力。
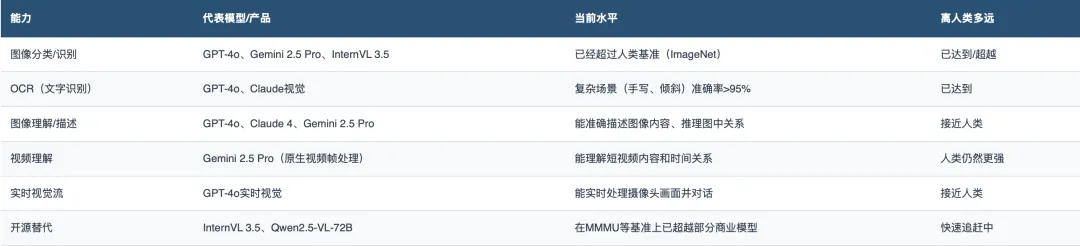
GPT-4o和Claude 3.5 Sonnet在视觉-语言任务上都达到了74%的得分。而开源模型InternVL 3.5在多模态多任务基准(MMMU)上已经击败了GPT-4V和Claude 3。
判断:视觉是AI目前做得最好的「感官」。静态图像理解已经接近甚至超越人类水平,实时视觉理解正在快速跟进。这是整个AI中枢的「眼睛」——它已经睁开了,而且看得比很多人类还清楚。
2.听觉(耳朵)
ElevenLabs的v3模型已经支持情感方向控制、多说话人切换,70多种语言的语音合成都达到了以假乱真的水平。Whisper则在语音识别领域几乎成了事实标准。
实时语音交互的突破来自GPT-4o——320毫秒的响应延迟已经接近人类对话的自然节奏(人类对话平均约200-300毫秒的响应间隔)。
3.触觉和空间感知
这是最不成熟的感知通道。
目前的触觉感知主要集中在机器人领域——力传感器、压力传感器安装在机械手指上,让机器人能感知抓取力度。但和人类皮肤的触觉丰富度相比,差了几个数量级。
空间感知方面,3D场景理解正在进步(通过深度摄像头、激光雷达+视觉模型),但还远未达到人类对物理空间的本能理解。
判断:触觉和空间感知是当前AI感官体系中最薄弱的环节。对于纯数字世界的AI中枢,这不是硬伤;但对于具身智能(机器人),这是最大的瓶颈之一。
4.思考层:大脑
推理是LLM的看家本领。在数学、编程、逻辑推理等结构化任务上,顶级模型已经达到甚至超越了人类专家水平。但在开放式推理、常识推理、因果推理上,人类仍然更灵活。
最大的短板不是推理本身,而是「知道自己不知道什么」。人类有个元认知系统,能在思考过程中意识到「等等,我这个假设可能有问题」。当前LLM的self-reflection能力在快速进步(通过多轮思考、self-correction),但和人类的元认知相比还很原始。
5.记忆系统
记忆是「大脑」最复杂的部分,也是当前最活跃的研究方向。
RAG(检索增强生成)是当前AI记忆系统的核心架构。2025年的趋势是从纯向量检索向混合架构演进——Vector RAG做语义相似度搜索,GraphRAG做关系推理,HybridRAG把两者结合。
NeurIPS 2025上已经有论文专门benchmark这三种RAG方案。学术界的共识是:纯向量检索在复杂推理场景下表现不佳,加入知识图谱的结构化信息是必经之路。
判断:AI的「记忆」有容量但缺乏质感。它能记住海量的文本信息(上下文窗口越来越大),但记忆的组织方式——什么是重要的、什么之间有联系、什么时候该用什么记忆——远不如人类的记忆系统精致。
6.行动层:手脚
2025年的AI Agent框架生态已经相当成熟。20+个框架各有侧重,从研究原型到生产部署都有覆盖。Turing的一项对比研究详细评估了LangGraph、LlamaIndex、CrewAI、Semantic Kernel、AutoGen和OpenAI Agents。
7.工具使用
Computer Use是2024-2025年最令人兴奋的进展之一。Claude可以通过截图理解屏幕内容,然后模拟鼠标和键盘操作。OpenAI的Operator专注于浏览器场景。Google的Project Mariner也在做类似的事情。
但当前Computer Use的可靠性大约在60-70%——对于复杂的多步骤操作(比如「帮我整理一下桌面上所有项目文件夹」),经常会出错、迷路或陷入死循环。
判断:AI的「手脚」在数字世界里已经能用了,但还不够稳。在物理世界里,机器人的能力正在快速提升,但离「像人一样灵活」还有很长的路。
8.具身操作
2024-2025年是具身智能从实验室Demo走向商业部署的转折点。几家头部公司已经在真实的工厂和仓库里跑机器人了。
但「能用」和「像人」之间还有巨大的鸿沟。当前机器人在非结构化环境中的灵活度——比如一间凌乱的客厅——远远不如人类。它们擅长的是在结构化环境中执行预定义的动作。
9.通信协议的标准化
2025年最重要的进展是标准化协议的出现:
协调层:中枢神经
这是整个系统最复杂、最不成熟的部分,当前存在两条根本不同的技术路线:
路线A:端到端多模态。一个大模型处理所有模态。代表:GPT-4o、Gemini。
- 优势:效率高、延迟低、模态之间天然对齐
- 劣势:不灵活、难以替换单个组件、训练成本极高
路线B:模块化组合。多个专用模型通过编排框架协调。代表:LLM+Whisper+ElevenLabs+Agent框架。
- 优势:灵活、可替换、可扩展
- 劣势:延迟高、组件间对齐困难、编排复杂
路线C:混合方案。大模型负责核心推理,外部工具通过标准化接口连接。代表:Claude+MCP、GPT+Plugins。
- 当前最主流的方案
Apple Intelligence代表了一种特殊的混合方案:设备端小模型(~3B参数)处理实时任务,云端大模型处理复杂推理,Private Cloud Compute保证隐私。这种分布式架构可能是指端侧AI中枢的未来方向。
当前能力全景:离「像人」还有多远?
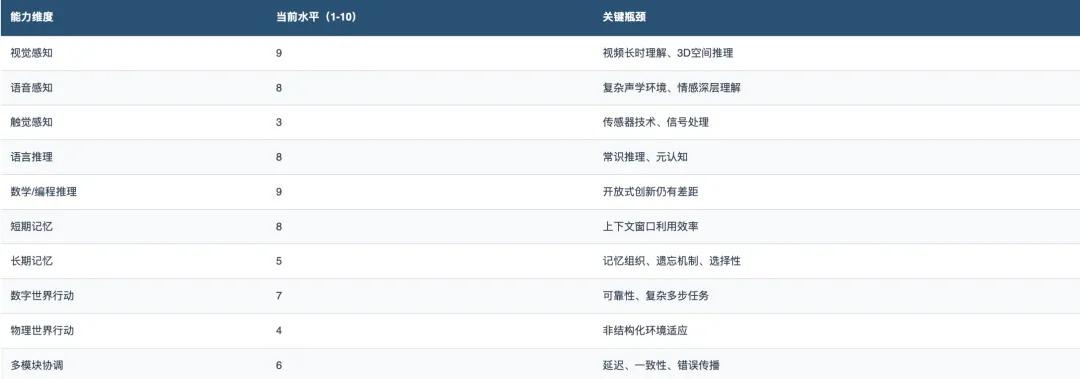
当前组装一个AI中枢的技术清单
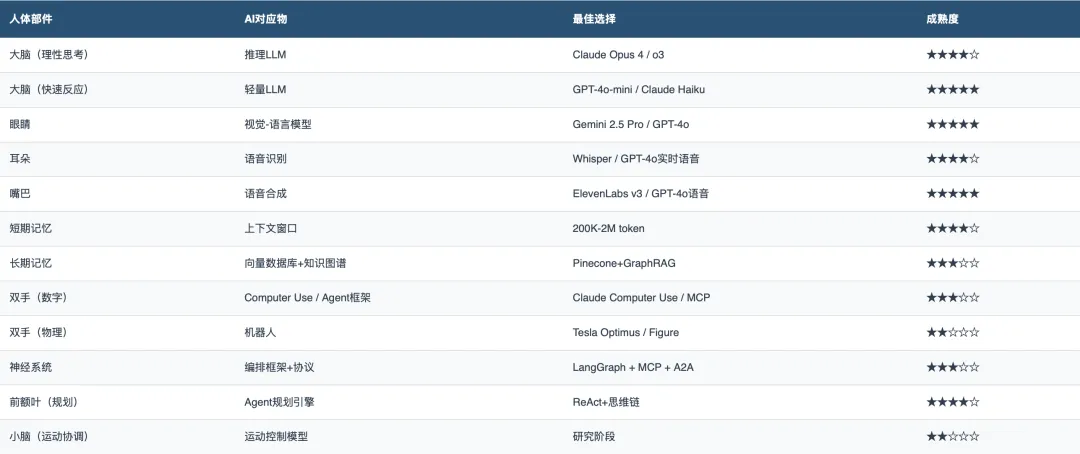
能组装出来,但离「像人」还远。最大的差距不在于单个模块的能力,而在于模块之间的协调效率——就像一支拥有顶级球员但缺乏默契的球队。
信息来源:
Introducing the Model Context Protocol — Anthropic Announcing the Agent2Agent Protocol (A2A) — Google Developers Blog OpenAI Agents SDK — GitHub AI Agent Frameworks Compared — Turing Comprehensive Comparison of Every AI Agent Framework in 2026 — Reddit Apple Intelligence Foundation Language Models — Apple ML Research Vision-Language Models Overview — GitHub Top Vision-Language Models — DataCamp Stanford HAI AI Index Report 2025 Best TTS APIs in 2025 — Speechmatics Voice Agents: Building Real-Time Conversational AI — Medium Soar Cognitive Architecture — Wikipedia ACT-R — Wikipedia An Analysis and Comparison of ACT-R and Soar — arXiv Benchmarking Vector, Graph, and Hybrid RAG — arXiv GraphRAG Complete Guide — Meilisearch MCP Impact on 2025 — Thoughtworks Donating MCP to the Agentic AI Foundation — Anthropic One Year of MCP — MCP Blog AI Models 2025 Complete Comparison — LocalAI Master ReAct: Synergizing Reasoning and Acting in Language Models — arXiv
