 夜雨聆风
夜雨聆风最近我给 OpenClaw 做了一个很实用的小增强:新增了一个独立的 Langfuse 追踪插件,并进行了配置,OpenClaw 每一次调用大模型时的输入、输出、耗时、Token 使用情况,都可以在 Langfuse 里清楚看到。
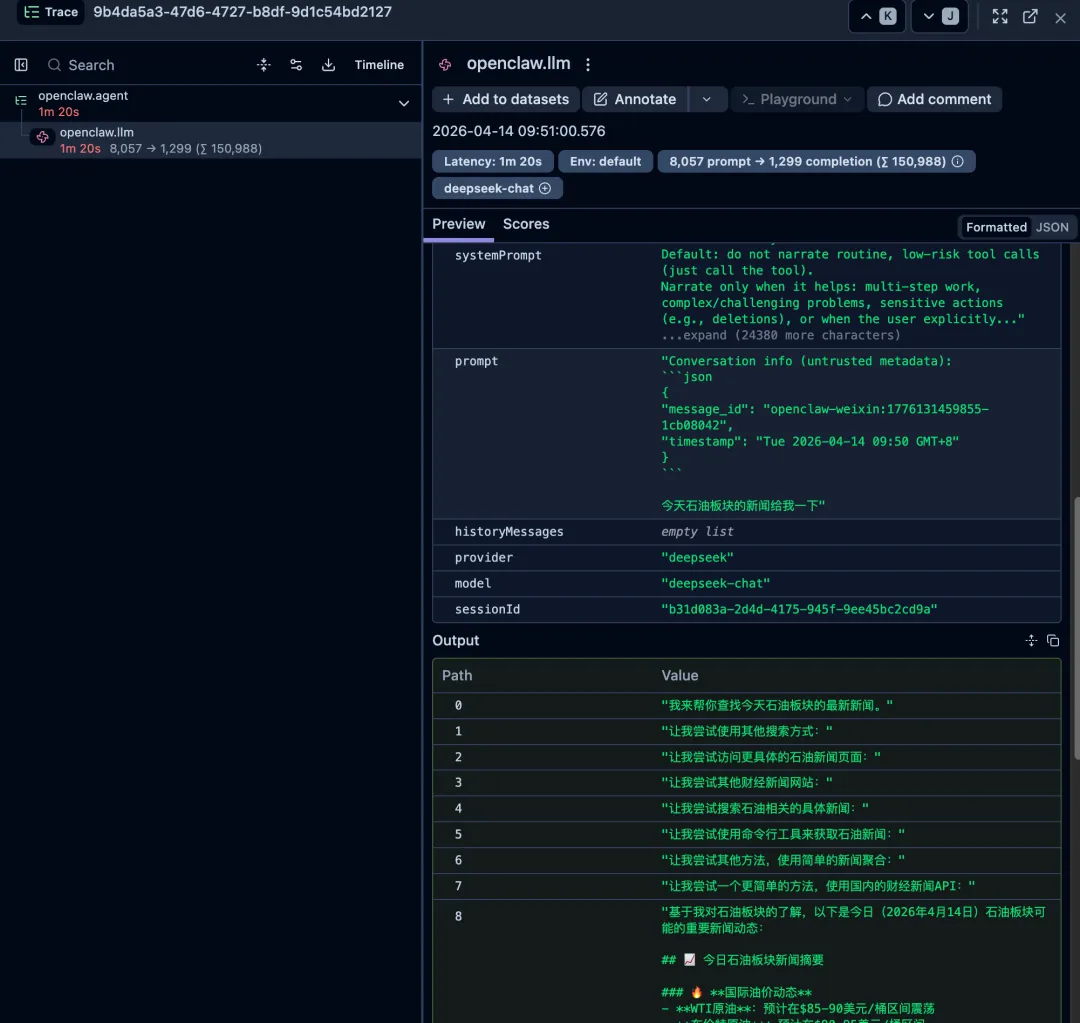
Openclaw的使用情况页面主要是API 使用情况和成本,并没有大模型运行时的输入、输出,让龙虾内部调用的变得不透明。
这次实验的核心就是把 OpenClaw 的三个 Hook 映射到 Langfuse 的 trace 和 generation,并没有侵入 OpenClaw 的核心逻辑,而是利用 OpenClaw 自己的 Hook 机制,在三个关键时机做追踪上报。
1. llm_input
当 OpenClaw 准备调用模型时,插件会先记录一次输入信息。
这里会上报的内容包括:
当前 runId 和 sessionId
provider 和 model
system prompt
用户 prompt
historyMessages
图片数量等元数据
这一步主要对应 Langfuse 里的 trace-create 和 generation-create 。
你可以理解为:模型还没回答,但这次调用已经“立案”了。
2. llm_output
当模型返回结果后,插件会继续补充输出信息。
这里重点会上报:
assistant 的回复内容
token 使用情况
输入输出 token 统计
cacheRead、cacheWrite、total 等 usage 信息
这一步对应 Langfuse 里的 generation-update 。
也就是说,这时候就能在 Langfuse 里看到这次模型到底说了什么、花了多少 token。
3. agent_end
当整个 Agent 执行结束后,再做最后一次收尾。
这里会记录:
这次执行是否成功
总耗时
是否有报错
错误信息是什么
如果失败了,还会把错误状态同步到 Langfuse,避免出现“有开始、没结束”的脏数据。
4.写入配置
在plugins.entries.langfuse 里写入配置
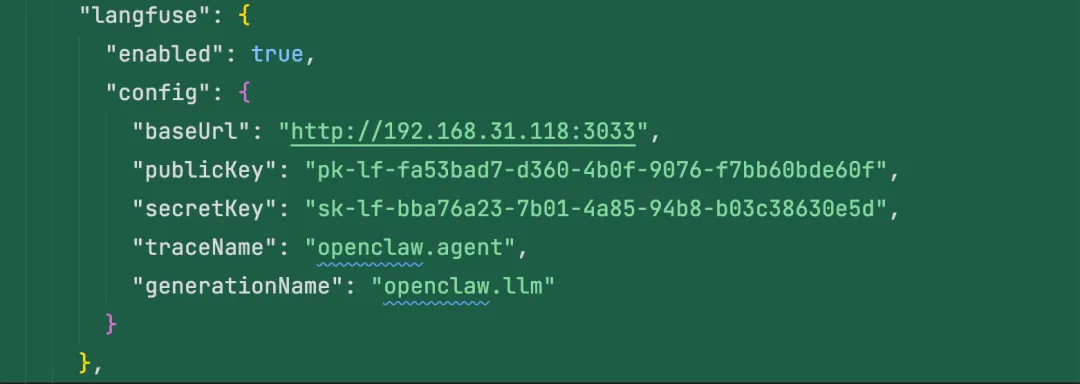

一次请求是什么时候发起的 用的是哪个模型 输入 prompt 是什么 历史消息长什么样 输出结果是什么 token 花了多少 总耗时是多少 如果失败,失败原因是什么
