 夜雨聆风
夜雨聆风各位茶友,下午好!欢迎来到【AI下午茶】,
咱们平时不管是做 3D 打印教程发抖音科普,做科技前沿的视频解说,最痛苦的环节是什么?配音!自己录吧,不仅容易嘴瓢,环境噪音还难搞;用市面上的 AI 配音软件吧,声音一股浓浓的“机器味”,而且稍微好点、能“克隆”你本人音色的软件(比如大名鼎鼎的 ElevenLabs),每个月都要收你高昂的订阅费。如果遇上几万字的长篇稿件,那点免费额度瞬间就能烧光。更别提把自己的声音传到云端,还有隐私泄露的风险。
作为一名热衷于把所有算力都捏在自己手里的硬件极客,我怎么能忍受这种被“卡脖子”和持续“吸血”的感觉? 直到这两天,我在 GitHub 上挖到了一个刚刚爆火、狂揽 1.7 万颗 Star的超级开源神器——Voicebox。 我愿意称它为目前地表最强的“个人专属本地配音工作台”!
它到底牛在哪里?为什么说它是我们做个人 IP 和搞自媒体副业的终极外挂?这就不得不提它极其硬核的三大降维优势:
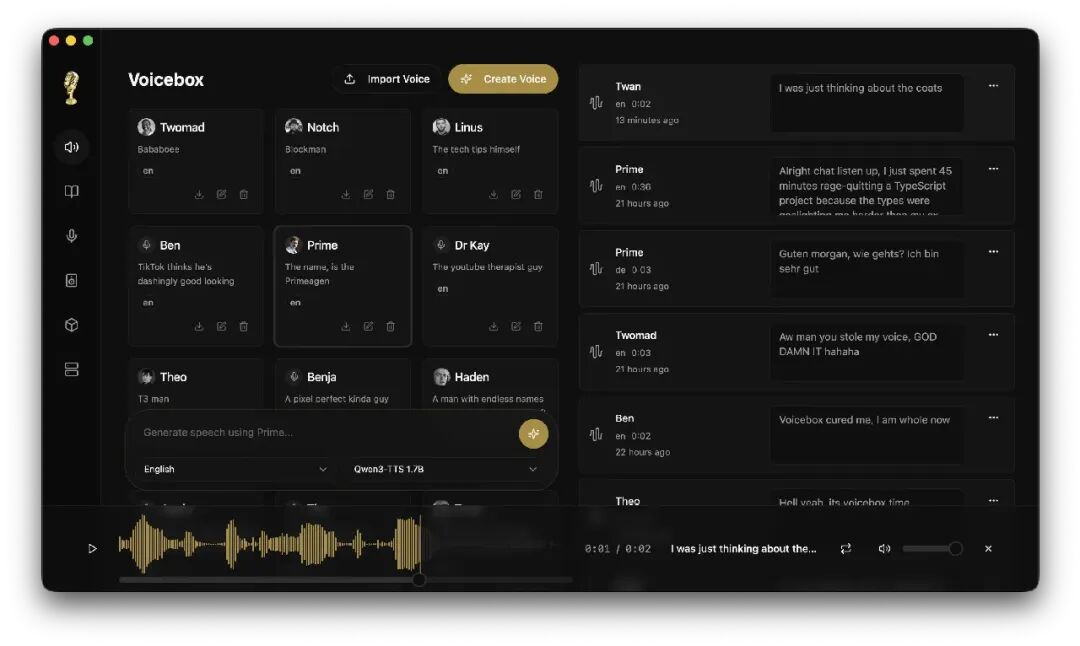
第一招:断网运行,零成本的“超级缝合怪”这是一个 Local-First(本地优先)的开源软件。这意味着你的模型和声音数据完全不会上传云端,彻底保护隐私。更绝的是,它不是单模作战,而是内置了整整 5 种顶级开源 TTS(文本转语音)引擎! 需要极致的多语种高保真?切 Qwen3-TTS;想在老电脑上跑?切 150倍速生成的 LuxTTS;需要包含 [笑声]、[叹气]、[清嗓子] 这种极其生动情绪的?直接切 Chatterbox Turbo。这就像你的开发板上同时外挂了 5 种不同特性的高级音频解码芯片,随意切换!
第二招:图形化时间轴与专业后期(干翻一众付费软件) 别以为开源软件就只有简陋的黑框框。Voicebox 用 Rust (Tauri) 写了一个极其丝滑的桌面端界面。 它不仅支持无限长度的文本自动分段和淡入淡出(几万字的书直接丢进去都没问题),它甚至内置了一个 多轨故事编辑器(Stories Editor) 和 Spotify 的高级后期效果器。给声音加混响、做延迟、甚至是做“高低频过滤”和音调偏移,在这里点两下鼠标就能搞定。
第三招:全平台硬件通吃,无需高配显卡 作为搞硬件工程的,咱们最关心的就是“吃不吃配置”。Voicebox 的底层优化堪称变态:不管是 Windows 的英伟达显卡(CUDA)、Mac 的苹果芯片(Metal),还是AMD 的显卡,甚至你只有一块 Intel 的核显或者纯靠 CPU,它都能跑!不需要你去敲代码配环境,Windows 用户甚至只要下载一个.msi 安装包,双击就能直接安装使用。
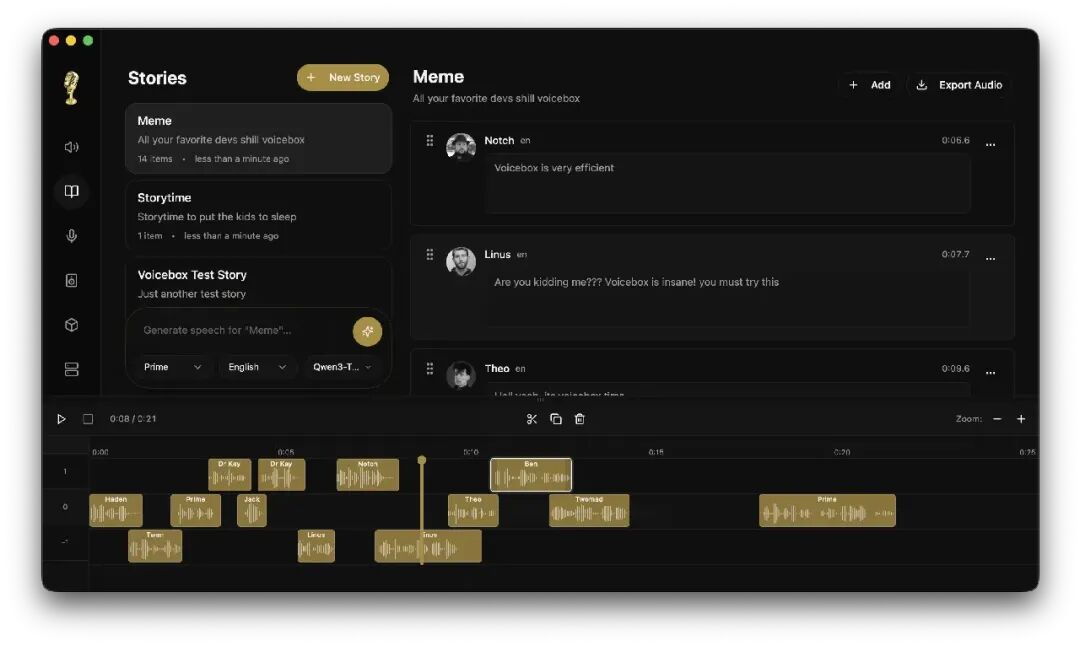
在这个节奏极快的时代,生产内容的效率就是你的护城河。 有了 Voicebox,你只需要录制自己几秒钟的清晰声音作为“种子”,它就能克隆出一个永远不会疲倦的“赛博王工”。不管是做有声书、短视频解说,还是开发需要语音交互的自制桌面机器人(别忘了它还提供了本地 REST API 接口),它都是一把瑞士军刀。
这绝对是你电脑里最该拥有的超级客户端之一!
想立刻拥有你的全免费、无限量的私人 AI 播音员吗?关注公众号【AI下午茶】,在后台回复关键词“配音神器”,获取
如果你觉得好用,别忘了把这篇文章转发给身边做自媒体或者需要配音的朋友们,大家一起降本增效!我们下期见!

