 夜雨聆风
夜雨聆风
有一句话,在这份报告里被受访者反复提到:
"技术不是最难的部分。"
不是客套。不是谦辞。是真的。
斯坦福数字经济实验室 2026 年 4 月发布的《企业 AI 实战手册》里,调研了 51 个案例、 41 家企业、 9 个行业、 7 个国家。研究团队花了 5 个月,专门挑已经跑通、产生了可量化价值的项目——不是"AI 能做什么"的畅想,是"AI 做成了什么"的复盘。
然后,受访者普遍认为:技术,是所有挑战里最不难的那一个。
一、关键认知:先把几个基本判断对齐
报告统计了真实阻力的来源分布:
技术排在倒数第二。
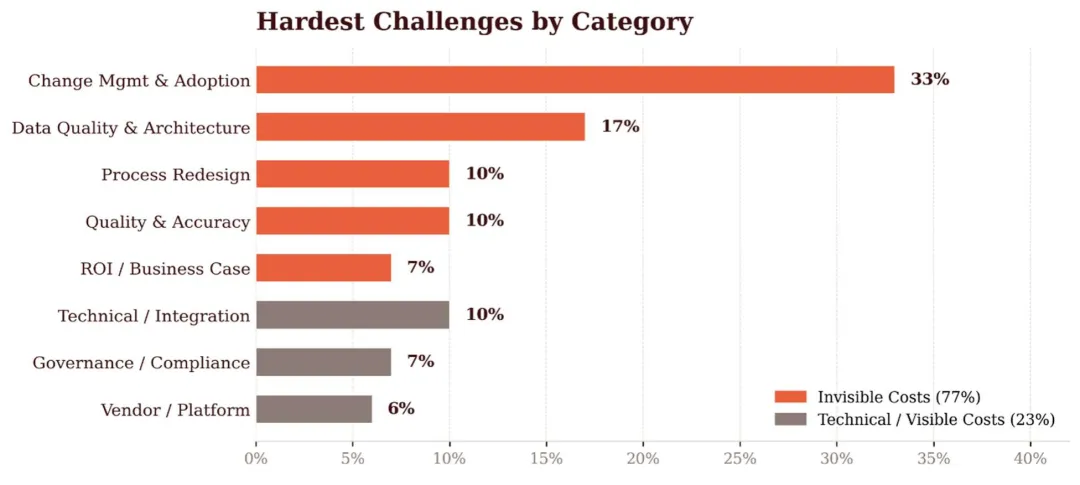
我第一次看到这组数字的时候,是有点不舒服的。
不舒服的原因很简单:行业内有多少公司,把"技术选型"当成核心议题来讨论?选大模型、选平台、选架构,开三天工作坊,然后产出一份"技术路线图"——这种东西我见过太多了,而且说实话,大部分都是废纸。
不是说这份报告也有问题。斯坦福这份不一样。但市面上那些跟风写的"AI 转型白皮书",你拿来垫桌角都嫌软。
技术讨论是舒适的。流程重设计是痛苦的。承认"我们其实不知道怎么让人用起来",比承认"我们选错了模型"要难得多。
另一个数字更让人睡不着:
61%的成功项目,之前都失败过。
你要是告诉我你们公司第一个 AI 项目就成功了,我倾向于不信。
失败的原因高度一致:把 AI 当技术项目做,没有业务 owner ,试图用 AI 去修一个本身已经坏掉的流程。
流程烂,上 AI ,只是让烂跑得更快。
这个判断不先对齐,后面所有的行动建议都是废话。
二、核心洞察:报告里最值得重视的五个结论
说真的,五个结论,随便拎一条出来,都比大多数公司开的"AI 战略研讨会"有营养。
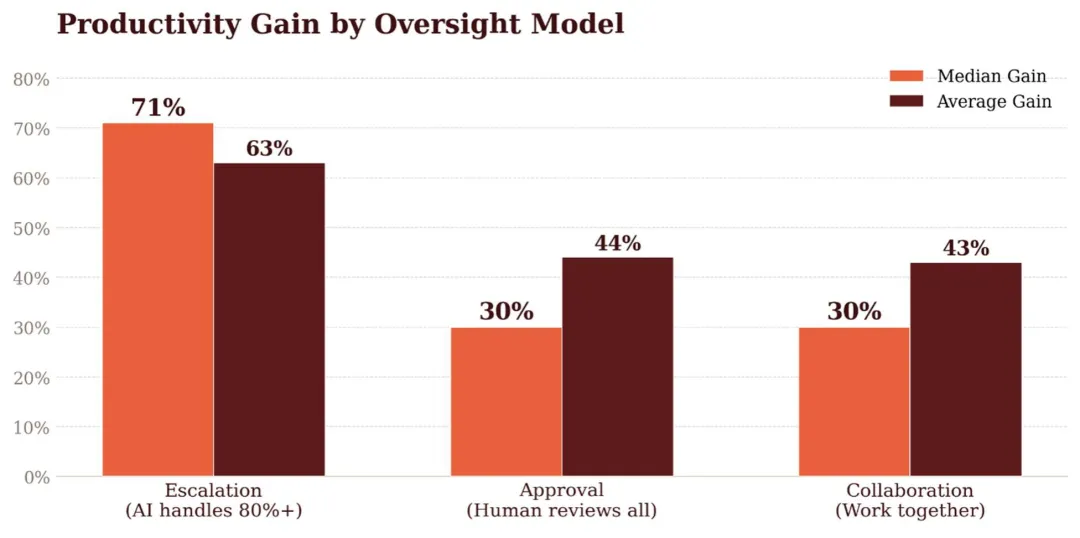
1. 人机协作的最优解不是"人盯着 AI"
报告把 AI 应用分了三个档次,效率提升中位值差异巨大,但多数公司还卡在第一档不肯动。
升级模式效果最好。但报告也坦承:这是"任务选择偏差"——能被设计成升级模式的,本身就是高重复、容错率高的任务。那些监管严格的场景,医疗文书、法律合规,该审的还是得审。
所以别一刀切。任务类型决定协作模式。
2. 阻力最大的不是一线员工
职能部门(法务、人力、风控)的阻力占 35%。终端用户 23%。中层管理 18%。 C 层 12%。
职能部门为什么最难搞?不是因为他们反对 AI 。
是因为他们不想为 AI 的失误背锅。
你让人家审 AI 的结论,一出问题,责任是 AI 的还是他的?他不傻。这事儿要真想推下去,得有人先把权责边界给钉死,不然永远是鸡同鸭讲。
报告给出的有效解法挺狠的:把 AI 写进公司级 OKR ,让职能部门从"审批者"变成"共同交付者"。锅分得出去,阻力就小一半。
3. 模型对 42%的场景来说是"大宗商品"
42%的案例里,模型选择完全可替换——换哪家效果差不多。
但在复杂任务(多步推理、领域专业判断、智能体工作流)中,这个数字掉到了 18%。 35%认为模型是关键差异点。
换句话说:简单任务,模型选谁都行;复杂任务,模型真能拉开差距。
关键差异不在模型本身,在模型调度层。
谁能根据任务类型动态选择模型?谁能把多模型的结果校验做好?谁能把模型切换的成本抽象掉?这才是壁垒。
国内现在有多少公司在吹自己"拥有最强大模型"?一多半都是在吹牛。真正难的不是拿到模型,是把它用好。
4. 数据不用完美,但"访问"比"清洗"更重要
只有 6%的项目启动时数据是"完全就绪"的。
但 91%的项目成功处理了非结构化数据。
大模型本身成了数据清洗工具——这是整份报告里最有实操价值的一句话。以前你觉得"数据脏没法用",现在可以直接喂给大模型,让它先处理一遍。
更关键的是:成功项目不追求数据集中化。 59%的项目数据散落在多个系统,他们做的事不是把数据搬到一起,而是做数据访问层——让 AI 能触达到数据。
这个思路的转变很值钱。
很多公司的数据治理搞了三四年,搭了一个巨大的数据中台,吭哧吭哧把数据洗干净、标签打上,结果呢?业务说用不起来,原因是"中台的数据不是我想要的"。
我之前在一家公司见过类似的事。数据团队搞了整整两年,上线了一套数据质量平台, dashboard 做得漂漂亮亮。然后呢?没人用。那套系统现在还活着,但活得像个摆设。
数据访问层不一样。你不用管数据在哪儿,你只需要告诉 AI :去这几个系统里查,有问题记下来,下次再优化。
先跑起来,边跑边修。说白了,脏数据喂给大模型,它自己能消化一大部分,比你雇人清洗快得多。
5. 智能体 AI 目前只占 20%,但效率提升显著
报告采集期是 2025 年 8 月到 2026 年 2 月,智能体 AI 还没大规模普及。即便如此, 20%的智能体项目效率提升中位值 71%,远高于非智能体项目的 40%。
这个数字让我有点焦虑。
但我更焦虑的是另一种公司:看了三份报告,开了一场对齐会,然后把这件事搁置了。"等我们准备好了再动"——说这话的,没一个真准备好了。
什么环境? API 可用性、权限体系、任务边界定义。这三件事技术含量不高,但需要时间和业务一起去磨。
磨得越早,主动权越大。
三、落地行动框架:五个可以马上开始的工作
基于以上洞察,这五件事优先级最高。不是咨询公司给你画的那种"三年数字化转型蓝图",就是五件真能动起来的事。
第一件事:做一次"流程债务"盘点
报告反复强调: AI 会让坏流程变得更坏、更快。
两周时间,选一个你打算上 AI 的业务领域,做三件事:
这份盘点不需要漂亮,但必须真实。
说白了,很多公司的流程就是一笔糊涂账,谁都不想承认。
第二件事:选一个"出错不致命"的场景起步
报告里跑得快的公司,很少一上来就挑最核心、最敏感的业务。
筛选标准:
内部知识库问答、会议纪要初稿、客服工单分类、代码注释生成——这些都是合适的起点。
先在一个不会出事的场景里跑通,建立信任,再往核心业务推。
第三件事:建立一个"数据访问层",而不是"数据中心"
说实话,这个坑我见太多人踩了——花两年时间搞数据治理,搭平台、上系统、做标签,结果业务部门一句"这数据不对"全给否了。
不要等数据全部清洗、集中、治理完。等不起。
三步走:
跑起来之后,记录 AI 返回结果时遇到的数据问题,形成一份"数据债务清单"。
这份清单就是后续数据治理的优先级排序——不是靠开会排,是靠 AI 在实际工作中暴露出来的。
用真实问题驱动数据治理。这比任何数据治理方案都靠谱。
说白了,就是别坐在办公室里憋大招,先让 AI 跑起来,它会告诉你哪儿卡住了。
第四件事:设计一个"信任积累"机制
不要一上来就追求全自动。
建议的路径:
每个阶段的阈值和放行条件提前定义好,用数据说话。
同时,选一个"出错代价低"的场景先跑这个机制,积累信任后再往高风险场景推。
这事儿的核心逻辑是:用户不会因为 AI"能干活"就信任它,他们会因为"AI 出错我能接受"才信任它。说白了,信任这东西,不是靠宣传得来的,是靠一次次放行积累出来的。
第五件事:找一个"翻译"角色,别找"全才"
报告里一个电信公司高管的原话:"我们最大的问题是缺乏既懂流程又懂 AI 的人。"
这种人在市场上基本不存在。
可以这样做:
三个月后,这个组合会比市面上大多数 AI 顾问更懂你的业务。
尾声
这份报告读下来,我最大的感受不是关于 AI 。
是关于一个组织面对变革时的底层能力:诚实面对问题的能力。
流程烂就是烂,数据乱就是乱,部门之间推责任就是推责任。这些事在 AI 之前就存在,只是被人力硬扛着。现在 AI 来了,扛不住了,问题暴露了。
暴露是好事。问题是藏不住的,早暴露早解决。
报告里那些跑得快的公司,没有一个是"问题比别人少"的公司。他们只是面对问题的速度快一点、逃避问题的次数少一点。
这个结论没什么新鲜的。
新鲜的可能是:你愿不愿意承认,你逃避过很多次?
关注公众号,发送“斯坦福报告”,下载报告原文。
报告原文链接:
https://digitaleconomy.stanford.edu/app/uploads/2026/03/EnterpriseAIPlaybook_PereiraGraylinBrynjolfsson.pdf
