 夜雨聆风
夜雨聆风最近在做全网热搜聚合工具,一开始雄心勃勃想用crawl4ai把百度、微博、抖音的网页全爬一遍,结果发现完全没必要——微博和抖音居然有未公开的官方JSON接口,直接请求就能拿到结构化的热搜数据,比解析HTML稳定十倍。
当然,API有失效或被封的风险,所以我还是用crawl4ai做了浏览器兜底。今天就重点分享如何通过微博、抖音的API直接获取数据,顺便看看crawl4ai怎么给兜底策略兜底。
一、为什么优先用API而不是爬网页?
网页抓取痛点:
微博未登录会重定向,登录态需要维护Cookie 抖音的React哈希类名每周变化,选择器不停失效 页面渲染依赖JS执行,慢且资源消耗大
而官方API的优势:
返回纯JSON,无需解析HTML 结构稳定,字段明确(热搜词、热度值、标签) 请求速度快,并发友好 部分接口甚至无需Cookie
只要找到正确的接口地址和参数,就能像调天气API一样轻松拿到热搜。
二、微博热搜API:/ajax/side/hotSearch
微博的热搜榜其实有个公开的Ajax接口,PC端热搜页会异步请求这个地址获取数据。
2.1 接口详情
URL: https://weibo.com/ajax/side/hotSearch方法: GET 请求头: 需要携带合法的 User-Agent、Referer、Accept,最好加上Cookie(尤其要包含SUB字段)
2.2 响应结构
{"ok": 1,"data": {"realtime": [{"word": "五一档电影票房破纪录","num": 1820345,"label_name": "热","url": "https://s.weibo.com/weibo?q=%23%E4%BA%94%E4%B8%80%E6%A1%A3%23"}, ...]}}word: 热搜词条num: 热度数值(可用于排序)label_name: 标签如"热"、"沸"、"新"url: 搜索链接
2.3 Python调用代码
import aiohttpimport jsonasync def fetch_weibo_hot(cookies: dict = None): url = "https://weibo.com/ajax/side/hotSearch" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36","Referer": "https://weibo.com/","Accept": "application/json, text/plain, */*", }if cookies: headers["Cookie"] = "; ".join(f"{k}={v}" for k, v in cookies.items())async with aiohttp.ClientSession() as session:async with session.get(url, headers=headers) as resp: data = await resp.json()if data.get("ok") == 1:return [ {"rank": i+1,"title": item["word"],"hot_score": item.get("num", ""),"label": item.get("label_name", ""),"url": item.get("url", "") }for i, item in enumerate(data["data"]["realtime"])if not item.get("is_ad") # 过滤广告 ]return []小技巧:无Cookie也能返回数据,但可能缺少部分字段或条目数有限。加上包含 SUB 的登录Cookie后数据更完整。
三、抖音热搜API:/aweme/v1/hot/search/list/
抖音的热搜API同样隐藏在PC版网页的网络请求中,需要携带正确的参数和Cookie。
3.1 接口详情
URL:
https://www.douyin.com/aweme/v1/hot/search/list/方法: GET
必需参数:
device_platform:webappaid:6383channel:channel_pc_webhot_search_type:10pc_client_type:1version_code:170400等版本号关键Cookie:
msToken: 必填,用于防爬校验ttwid: 设备标识,可选但建议携带passport_csrf_token: 登录态相关,可选
3.2 响应结构
{"status_code": 0,"data": {"word_list": [{"word": "NBA季后赛","hot_value": 9342100,"label": 1,"event_time": 1744627200}, ...]}}word: 热搜词hot_value: 热度值(数值型,越大越热)label: 标签类型(数字映射,如1=热)event_time: 上榜时间戳
3.3 Python调用代码
async def fetch_douyin_hot(cookies: dict = None): url = "https://www.douyin.com/aweme/v1/hot/search/list/" params = {"device_platform": "webapp","aid": "6383","channel": "channel_pc_web","hot_search_type": "10","pc_client_type": "1","version_code": "170400","version_name": "17.4.0", } headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36","Referer": "https://www.douyin.com/hot", }if cookies: headers["Cookie"] = "; ".join(f"{k}={v}" for k, v in cookies.items())async with aiohttp.ClientSession() as session:async with session.get(url, params=params, headers=headers) as resp: data = await resp.json()if data.get("status_code") == 0:return [ {"rank": i+1,"title": item["word"],"hot_score": item.get("hot_value", ""),"label": item.get("label", ""),"url": f"https://www.douyin.com/search/{item['word']}" }for i, item in enumerate(data["data"]["word_list"]) ]return []注意:抖音API对Cookie的 msToken 校验较严格,如果没有有效的 msToken,接口可能返回空数据或报错。从浏览器登录后复制完整Cookie即可。
四、百度热搜
百度热搜没有找到公开的JSON接口,所以还是用crawl4ai渲染页面提取。好在百度反爬较弱,crawl4ai一个配置搞定。
run_config = CrawlerRunConfig( wait_until="networkidle", wait_for=".c-single-text-ellipsis", # 标题元素 delay_before_return_html=2.0, simulate_user=True,)用CSS选择器提取标题列表即可。
五、运行效果
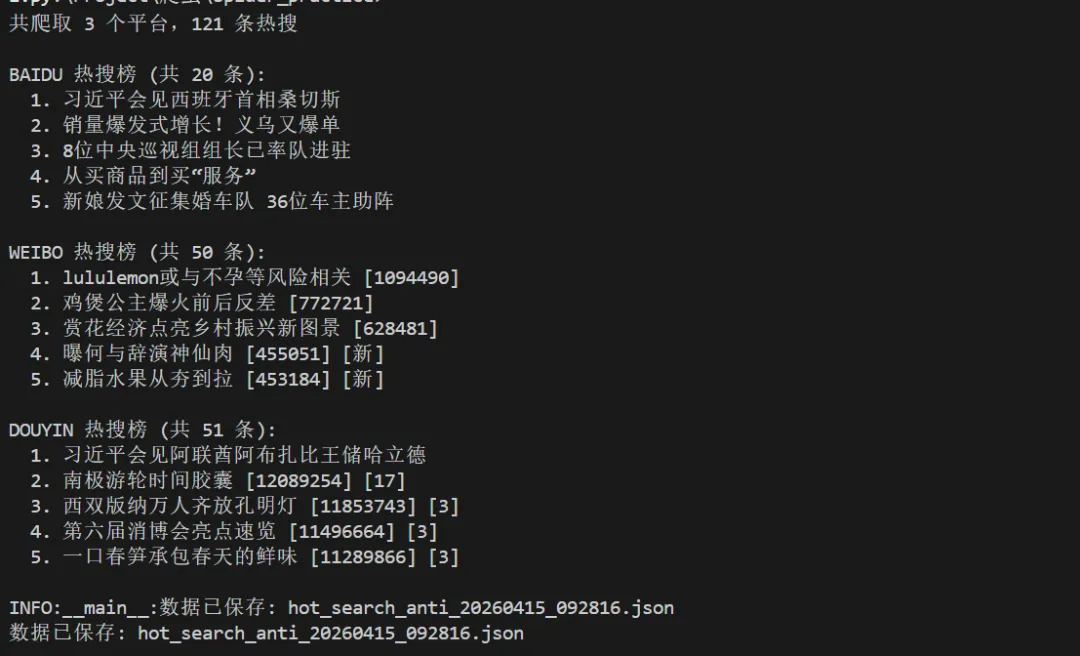
一个请求周期内,三平台热搜全部到手,速度飞快。
六、总结
整个爬虫从构思到稳定运行只花了一个下午,核心思路就是 API 优先 + 浏览器兜底。对于大多数动态站点,能用接口绝不去碰 DOM,既快又稳。
当然,无论是微博、抖音的接口调用,还是后续的数据分析、自动摘要,都离不开稳定的 LLM 能力支撑。如果你也像我一样重度依赖 Claude、GPT 等大模型做数据处理或内容生成,可能会遇到两个问题:
官方 API 价格不菲,调用量大了心疼预算; 网络环境不稳定,直连困难。
这里推荐一个我自己在用的 Claude Code 中转 API Token 服务:
✅ 支持 Claude 全系列模型(包括 Opus、Sonnet、Haiku)
✅ 价格约为官方的 十分之一,按量计费,无月费
✅ 国内直连,延迟极低,兼容 OpenAI 格式,一行代码切换
✅ 并发不限,适用于爬虫批量处理、数据清洗、自动打标等场景
网站地址::https://zbenru.cn/
我将完整代码整理在了Gitee[1],欢迎自取。
参考资料
[1]
Giteehttps://gitee.com/fengde_jijie/python_spider/tree/main/crawl4ai/Media_hot_search
