 夜雨聆风
夜雨聆风

一台电脑
从零搭建一人AI药企
BioTender | AIDD

一个人坐在咖啡馆里,用一台笔记本,可以完成过去需要一支20人团队、一间湿实验室、数千万资金才能做到的事情。这不是科幻小说,这是现在正在发生的事。

一个不可思议的比喻


2006年,亚马逊推出AWS。在这之前,一家互联网公司要上线,必须先买服务器、租机房、雇运维,光基础设施就能烧掉几百万。AWS出现之后,一个程序员花几十美元就能租到算力,当天部署,隔天上线。互联网的创业门槛,在一夜之间坍塌了。

同样的事情正在生物学领域发生。只不过这一次,"服务器"变成了GPU云,"代码跑通"变成了蛋白质序列设计,"部署上线"变成了向自动化实验室下单做湿实验。整条链路,一个人,一台电脑,就能走完。
这条链路究竟长什么样


传统药物研发的链路,大概是这样的:
靶点确认 → 苗头化合物筛选 → 先导化合物优化 → 临床前研究 → 临床试验 → 上市每一步都需要大量人力、时间、资金。光是从靶点到一个有苗头的分子,往往就要消耗2-3年、上千万美元。
但如果我们聚焦到其中一个子问题——蛋白质/抗体的从头设计与早期验证——链路可以被压缩成这样:
【靶点结构(PDB文件)】↓【AI计算设计层(Modal云GPU)】de novo结构生成 → 序列优化 → 计算打分筛选↓【自动化湿实验层(Adaptyv Bio API)】蛋白质合成 → 表达检测 → 结合亲和力测定(BLI/SPR)↓【结果反馈】Kd、kon、koff数据 → 指导下一轮设计迭代
每一层都已经有现成的基础设施可以调用。而且,它们之间可以用代码打通。
干端:
Modal + biomodals,
把超算放进终端


Modal是什么
Modal是一个面向AI/ML工作流的云计算平台。它的核心逻辑很简单——你写一个Python函数,加一个装饰器,它帮你在云端的GPU上运行这个函数。不需要管理服务器,不需要配环境,按秒计费。

import modalapp = modal.App()@app.function(gpu="A100", timeout=3600)def run_protein_design(pdb_path: str):# 这个函数跑在A100 GPU上...
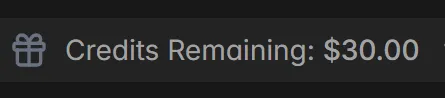
免费层每月给$30额度,对个人研究者来说,够跑相当数量的实验。
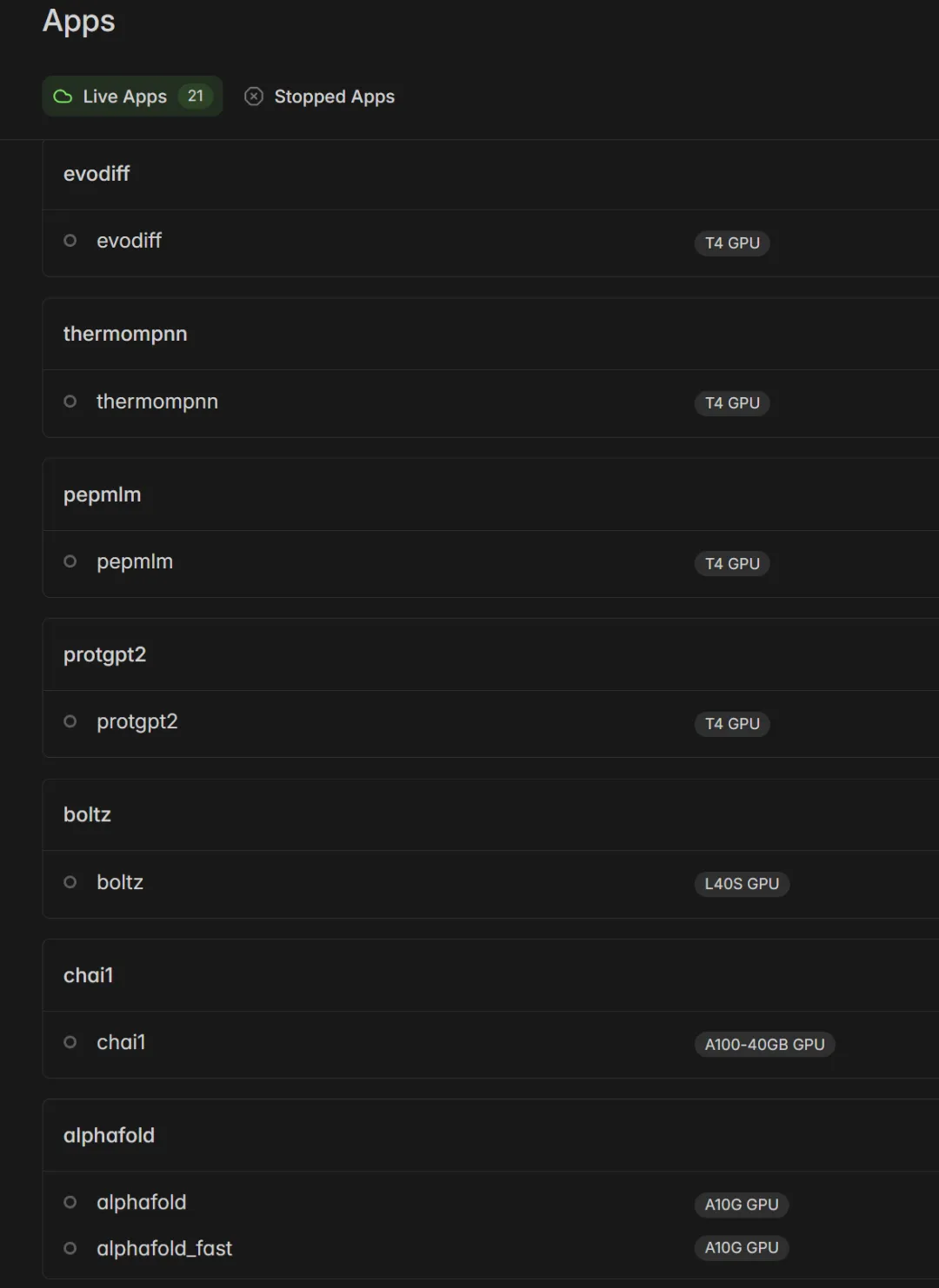
biomodals:生物计算工具箱——Brian Naughton(Boolean Biotech博主)做了一件极有价值的事:把主流的生物计算工具全部打包成可以一键调用的Modal脚本,放在GitHub仓库 hgbrian/biomodals 里。👇
这个工具箱覆盖了抗体/蛋白质设计的完整流水线:
结构预测层
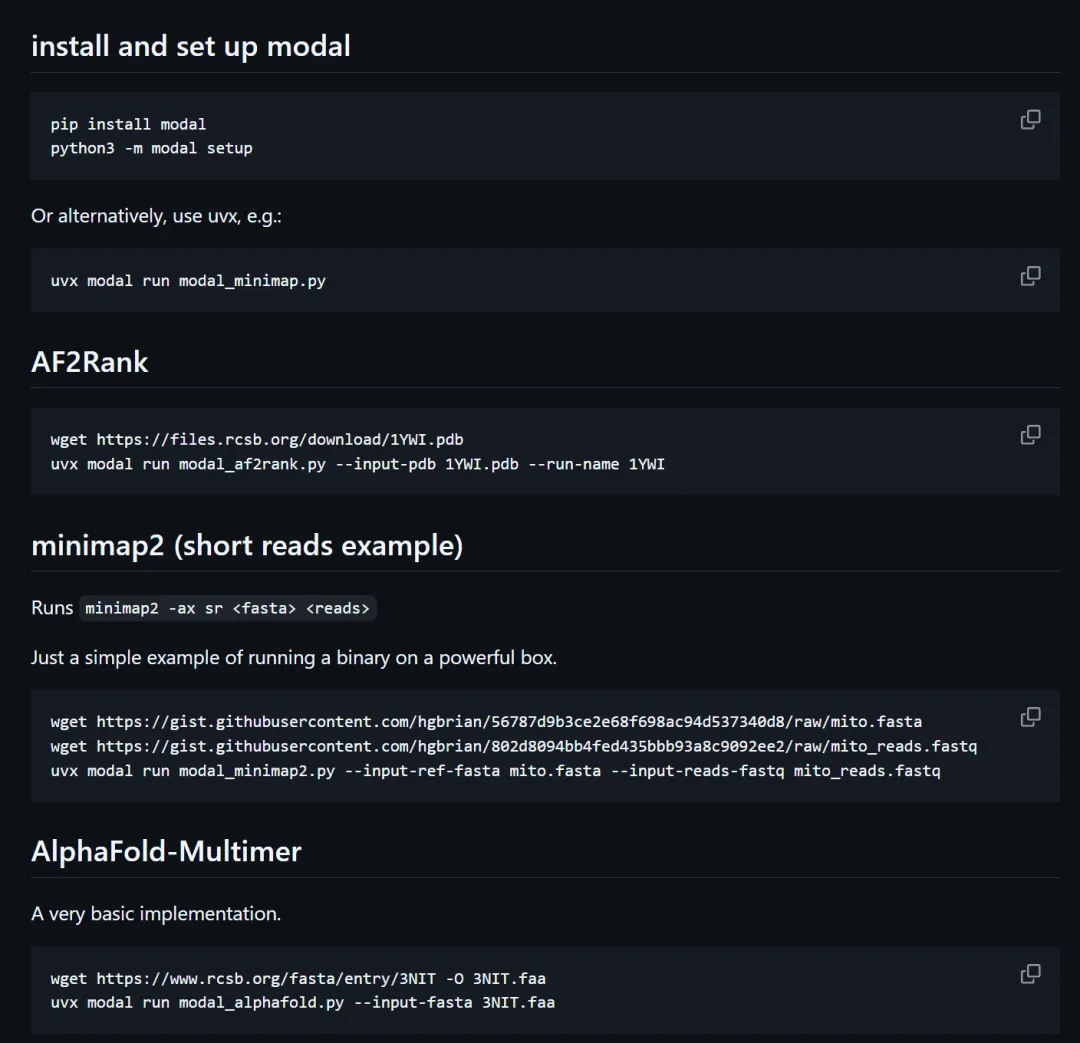
uvx modal run modal_alphafold.py --input-fasta seq.faa | ||
uvx modal run modal_boltz.py --input-yaml input.yaml | ||
uvx modal run modal_chai1.py --input-faa complex.faa |
从头设计层
打分评估层
分子动力学
# 对设计好的结构跑50000步MD模拟验证稳定性uvx modal run modal_md_protein_ligand.py \--pdb-id out/bindcraft/design_001.pdb \--num-steps 50000
一个完整的设计工作流示例
以设计PD-L1 binder为例:
# 1. 下载靶点结构wget https://files.rcsb.org/download/5JDS.pdb# 2. BindCraft从头设计(在A100上跑约1小时,约$3)GPU=A100 uvx modal run modal_bindcraft.py \--input-pdb 5JDS.pdb \--number-of-final-designs 5# 3. 用Chai-1做复合物结构预测打分uvx modal run modal_chai1.py \--input-faa designs_complex.faa# 4. 用AF2Rank计算ipSAE得分uvx modal run modal_af2rank.py \--input-pdb out/bindcraft/design_001.pdb# 5. 筛选top候选序列python filter_designs.py \--min-iptm 0.7 \--max-ipae 10 \--output candidates.fasta
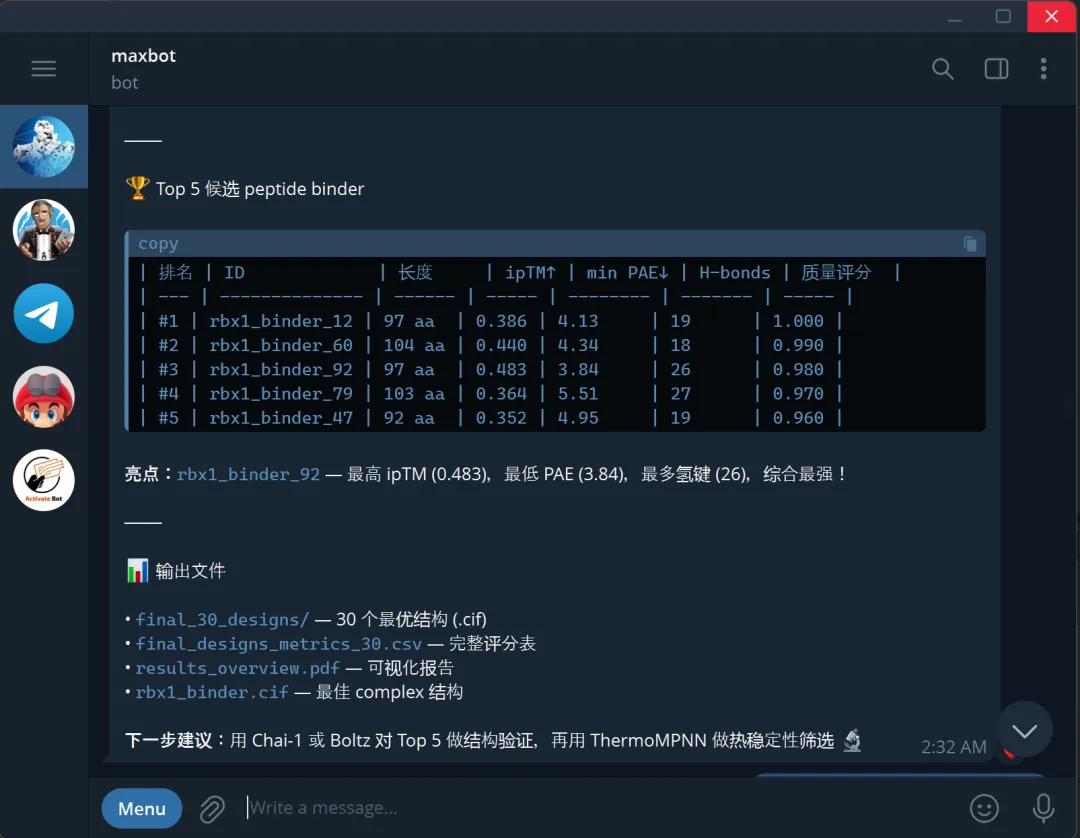
openclaw运行实例👆
几个小时,几美元,你手里就有了一批计算上"看起来能结合"的候选序列。
下一步,就是把它们送去真正的实验室验证——而这件事现在也可以用API完成。
湿端:
Adaptyv Bio,
把实验室变成API


Adaptyv是什么——Adaptyv Bio是一家2021年成立的瑞士公司(洛桑),做的事情可以用一句话概括,把蛋白质实验室变成一个可编程的API。
你上传序列,它帮你合成蛋白质、跑实验、返回数据。不需要实验室,不需要招人,不需要买仪器。
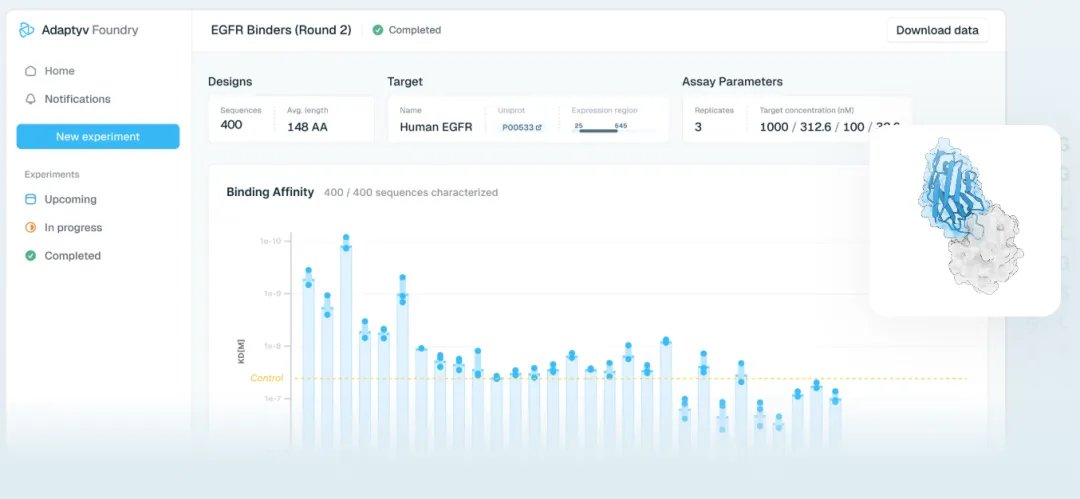
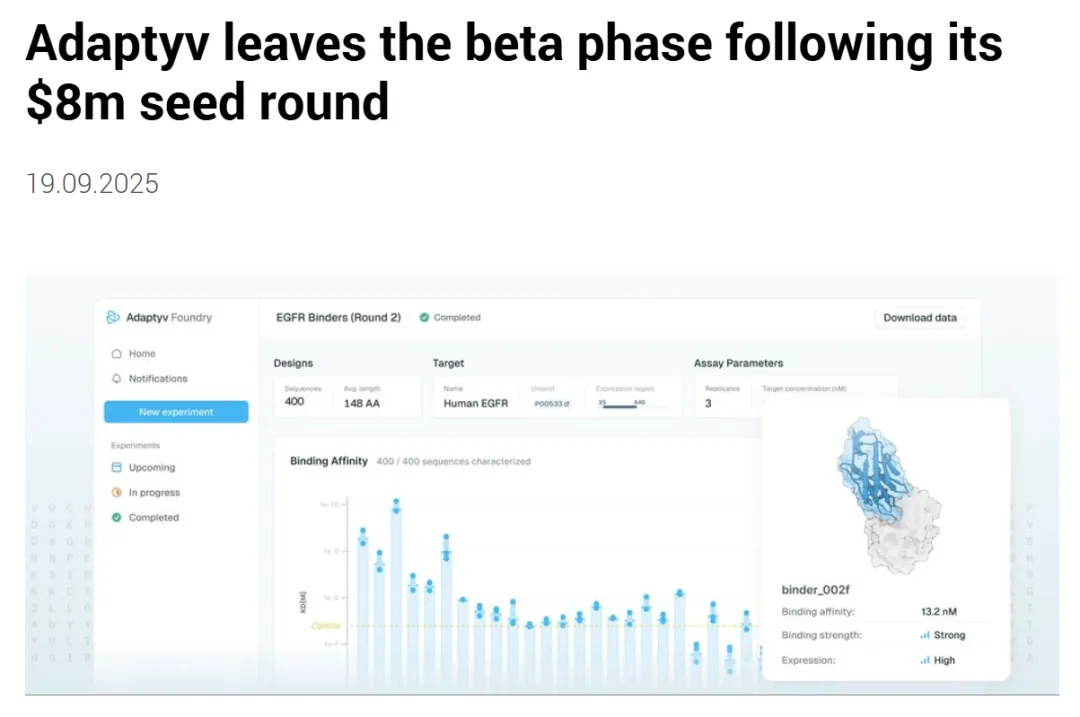
2025年,Adaptyv完成了$800万种子轮(Ace Ventures领投),正式向所有蛋白质设计者开放。
Foundry API的能力
五个核心资源组:
Targets → 浏览可用靶点目录(EGFR、HER2、PD-L1、IL-7Rα等)Sequences → 提交待测序列Experiments → 创建并管理实验Status → 追踪实验进度(webhook通知)Results → 获取实验结果数据
返回的数据格式(以结合assay为例):
{"sequence_name": "VHH-01","target_name": "HER2 / ERBB2","kd": 8.1e-10,"kd_units": "M","kon": 2400000,"koff": 0.0019,"binding_strength": "strong","r_squared": 0.999}
Kd、kon、koff全部给你,是真实的动力学参数,不是半定量结果。
定价透明(这在传统CRO里是稀缺品):
Assay费用:$99/条序列材料费:约$17.49/条序列5条序列一批:约$582周转时间:21天。
用Python下单——安装官方SDK:
pip install adaptyv-sdk提交实验:
from adaptyv_sdk import AdaptyvClientimport osclient = AdaptyvClient(api_key=os.environ["ADAPTYVBIO_API_TOKEN"])# 查看可用靶点targets = client.targets.list(search="EGFR", selfservice_only=True)target_id = targets[0].id# 提交序列做结合assayexperiment = client.experiments.create(assay_type="binding",target_id=target_id,sequences=[{"name": "design_001", "sequence": "QVQLVESGG..."},{"name": "design_002", "sequence": "EVQLVESGG..."},{"name": "design_003", "sequence": "QVTLVESGG..."},])print(f"实验编号:{experiment.experiment_code}")print(f"预计费用:${experiment.total_cost_usd:.2f}")print(f"预计完成时间:{experiment.estimated_completion_date}")
results = client.results.list(experiment_id=experiment.id)for r in results:print(f"{r.sequence_name}: Kd = {r.kd:.2e} M ({r.binding_strength})")
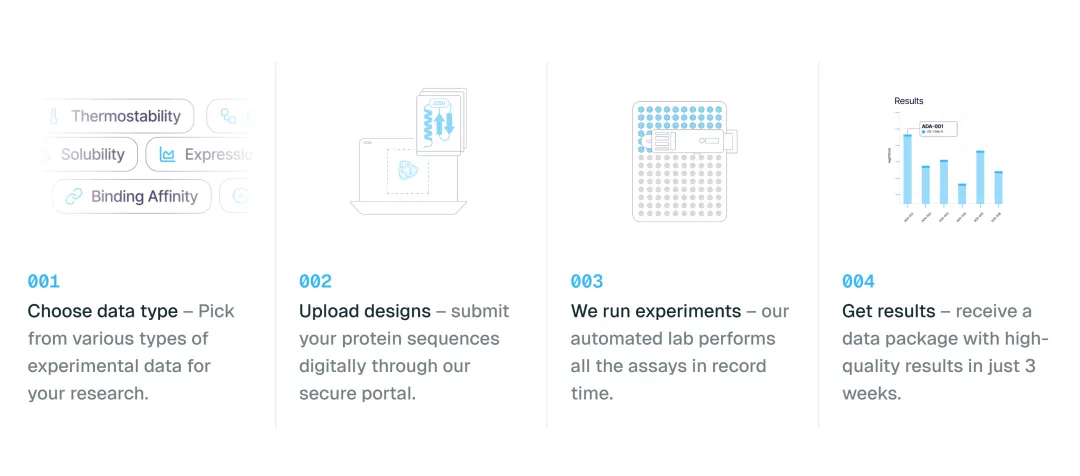
干湿闭环:
把两端接起来


这才是真正有意思的地方。
当干端(Modal设计)和湿端(Adaptyv实验)都可以被代码调用,它们之间的"闭环"就不再是隐喻,而是真实可以运行的pipeline。
一个自动化迭代循环的骨架
import modalfrom adaptyv_sdk import AdaptyvClientimport time# ---- 配置 ----TARGET_PDB = "5JDS.pdb" # PD-L1结构TARGET_ID = "comp-pdl1-human" # Adaptyv靶点IDDESIGNS_PER_ROUND = 5 # 每轮设计候选数MAX_ROUNDS = 3 # 最大迭代轮次KD_THRESHOLD = 1e-8 # 目标亲和力(10 nM)client = AdaptyvClient(api_key=os.environ["ADAPTYVBIO_API_TOKEN"])def run_design_round(pdb_path: str, round_num: int) -> list[dict]:"""在Modal上跑BindCraft,返回候选序列列表"""# 调用biomodals的BindCraftresult = modal.runner.run_sync("modal_bindcraft",input_pdb=pdb_path,number_of_final_designs=DESIGNS_PER_ROUND,round_tag=f"round_{round_num}")return result["sequences"]def submit_to_adaptyv(sequences: list[dict]) -> str:"""向Adaptyv提交湿实验"""experiment = client.experiments.create(assay_type="binding",target_id=TARGET_ID,sequences=sequences)print(f"[Round] 实验 {experiment.experiment_code} 已提交,预计费用 ${experiment.total_cost_usd:.0f}")return experiment.iddef wait_for_results(experiment_id: str, poll_interval: int = 3600) -> list:"""轮询等待结果(每小时检查一次)"""while True:status = client.experiments.get(experiment_id).statusif status == "completed":return client.results.list(experiment_id=experiment_id)print(f"实验进行中,状态:{status},1小时后再查...")time.sleep(poll_interval)# ---- 主循环 ----best_kd = float("inf")best_sequence = Nonefor round_num in range(1, MAX_ROUNDS + 1):print(f"\n===== 第 {round_num} 轮设计 =====")# 干端:生成候选序列candidates = run_design_round(TARGET_PDB, round_num)# 湿端:提交实验exp_id = submit_to_adaptyv(candidates)# 等待21天后取结果(生产环境用webhook替代轮询)results = wait_for_results(exp_id)# 分析结果hits = [r for r in results if r.kd and r.kd < KD_THRESHOLD]print(f"命中(Kd < {KD_THRESHOLD:.0e} M):{len(hits)}/{len(results)} 条")if hits:best_hit = min(hits, key=lambda r: r.kd)print(f"最优序列:{best_hit.sequence_name},Kd = {best_hit.kd:.2e} M")if best_hit.kd < best_kd:best_kd = best_hit.kdbest_sequence = best_hit.sequenceif best_kd < KD_THRESHOLD:print(f"\n目标达成!最优Kd = {best_kd:.2e} M")breakprint(f"\n最终候选序列:\n{best_sequence}")
这段代码跑起来,就是一个真实运行的、干湿闭环的蛋白质设计迭代系统。
当然,实际使用中你会加上更多的计算筛选步骤(可开发性预测、脱靶风险、免疫原性评估),但骨架就是这样。
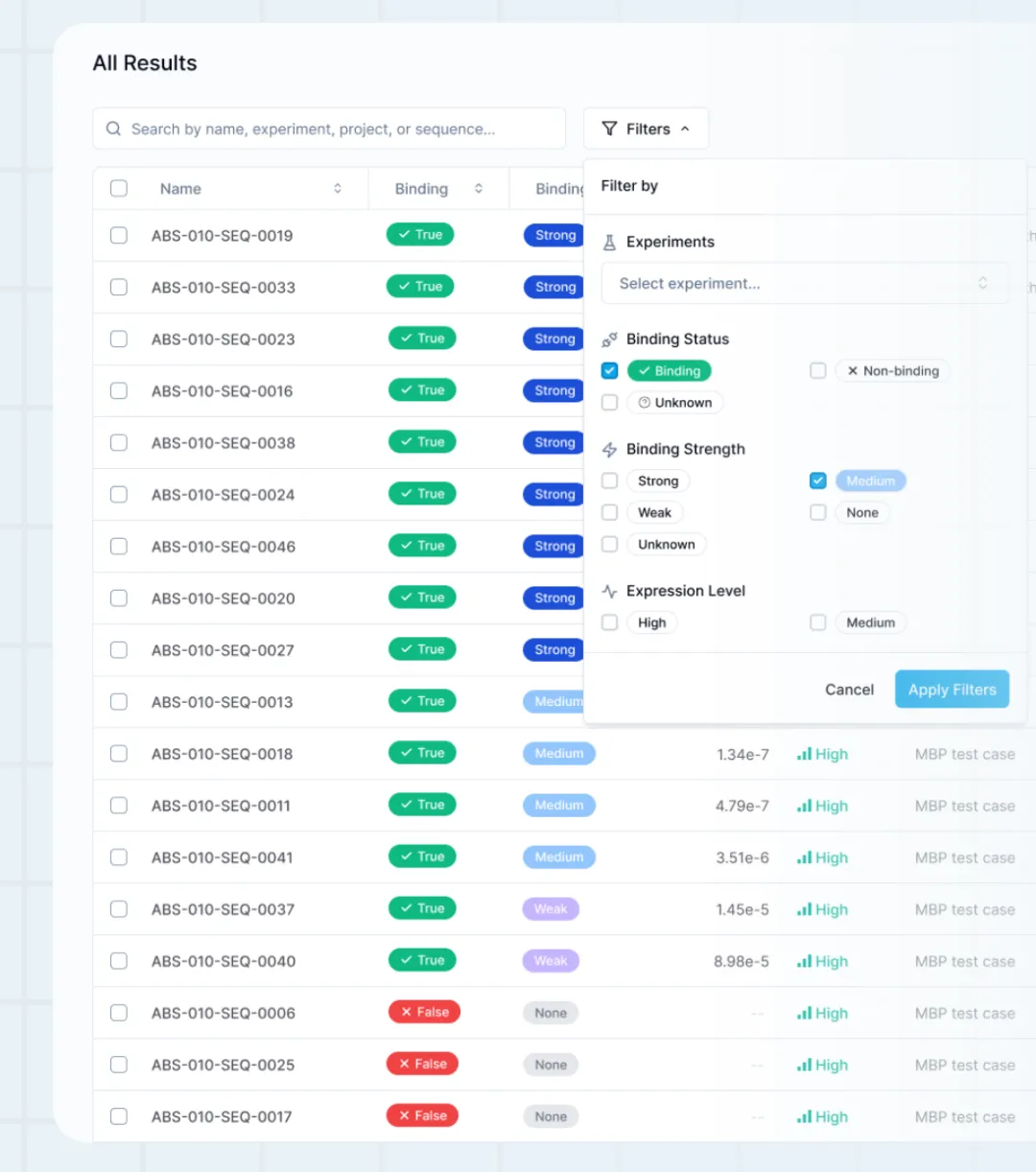
现实检验:
这条路的真实成本


干端(计算设计)
| 约$5 | 约2小时 |
Modal免费层$30/月,大约可以支撑6轮完整设计迭代。
湿端(实验验证)
三轮迭代的总预算估算
干端(3轮 × $5) ≈ $15湿端(3轮 × 5条) ≈ $1,746——————————————————————————合计 ≈ $1,761
不到两千美元,三轮计算-实验迭代,找到一个纳摩尔级别结合的候选序列。相比之下,传统CRO做同样的工作,光报价就不一定报出来,周期往往是6-12个月。

商业视角:
这开启了什么


一人公司的可能性——这套基础设施最直接的含义是:创业门槛被大幅压低了。
过去,做蛋白质/抗体治疗领域的公司,A轮之前必须有一个实验室(租金+装修+仪器,≥500万)、一支湿实验团队(至少3-5人,含仪器操作员)、一套数据管理系统。现在,一个有AI背景的生物学家,可以用Modal跑计算,$30/月起、用Adaptyv做实验验证,按需付费、用Python脚本管理整个pipeline。
这不是说一个人能做完所有事,而是说验证早期假设的成本,已经降低到个人可以承受的程度。这对CRO行业意味着什么。传统CRO的核心壁垒是我有设备,你没有。但当实验室变成API,这个壁垒开始松动。Adaptyv自己也清醒地意识到这一点。他们在博客里写道:Adaptyv存在的意义,是让蛋白质设计师专注于设计,而不是流水线。这和AWS出现之前开发者要自己管服务器一模一样。
未来可能出现的商业形态:
计算驱动的"虚拟CRO"——没有自己的实验室,但能承接客户的从头设计任务,外包给Adaptyv做验证。当前的局限性


需要如实说明,这套基础设施目前还有明显的天花板:
Adaptyv靶点目录有限。 自助服务(selfservice)的靶点目前集中在EGFR、HER2、PD-L1、IL-7Rα等热门靶点。偏门或全新靶点需要联系他们定制,失去了自动化优势。
湿实验周期仍然是21天。 干端几小时出结果,湿端3周等数据,限制了真正高频的迭代。Adaptyv明确表示在努力压缩这个数字,但目前还没有更快的方案。
assay类型有限。 目前主要是结合assay(BLI/SPR)和表达检测,热稳定性等更多表征维度仍在扩展中。对于需要细胞功能实验的项目,这一层覆盖不到。
地理摩擦。 Adaptyv在瑞士,国内支付、数据传输、合同合规需要额外处理。
这条路适合早期筛选,不适合替代全部研发。 它能帮你快速找到"计算上合理、实验上有结合"的候选,但后续的选择性、PK/PD、安全性等,还是需要传统的研发路径。
动手:
五分钟开始你的第一个实验


如果你想真实体验这套流程,最快的入门路径:
第一步:环境准备(10分钟)
# 安装uv(Python包管理器)curl -LsSf https://astral.sh/uv/install.sh | sh# 注册Modal账号,获得$30免费额度# https://modal.com → 注册 → 获取tokenpython -m modal setup# 安装Adaptyv SDKpip install adaptyv-sdk
第二步:克隆biomodals(1分钟)
git clone https://github.com/hgbrian/biomodalscd biomodals
第三步:跑你的第一个蛋白质折叠(5分钟,免费)
# 下载一个经典抗原wget https://files.rcsb.org/download/1YWI.pdb# 用AF2Rank打分uvx modal run modal_af2rank.py --input-pdb 1YWI.pdb --run-name test
第四步:尝试设计一个binder(1小时,约$3)
# 下载PD-L1结构(只保留A链)wget https://files.rcsb.org/download/5JDS.pdbgrep "^ATOM.*\ A\ " 5JDS.pdb > 5JDS_chainA.pdb# 跑BindCraftGPU=A100 uvx modal run modal_bindcraft.py \--input-pdb 5JDS_chainA.pdb \--number-of-final-designs 3
第五步:申请Adaptyv API token
访问 foundry.adaptyvbio.com,注册账号,在侧边栏获取API token。在下单前,可以先用免费的竞赛(如Nipah binder competition)练手。
这是一个什么样的时刻


2024年,Adaptyv举办了一场EGFR binder设计竞赛,150多个参赛者提交了超过1800个设计,Adaptyv在实验室测了其中601个。第一轮命中率2.5%,两个月后第二轮提升到13%。
在这场竞赛里,排名最靠前的参赛者,用的就是这套工具——Modal跑计算,Adaptyv做验证,一个人在电脑前。
这不是说个人研究者要去跟大药企竞争。药物研发的后半段,临床、法规、商业化,不是工具能解决的。但这意味着在药物研发最昂贵、最慢的早期探索阶段,个体的力量第一次变得可以和机构抗衡。就像GitHub让一个人可以维护一个被全球数百万开发者使用的开源项目,这套基础设施让一个人可以真正意义上地"研发"一个蛋白质候选分子。一台电脑,一张信用卡,一人药企,不再是隐喻。
参考资源
biomodals仓库:github.com/hgbrian/biomodals
Boolean Biotech博客:blog.booleanbiotech.com
如果你想跟进这类“AI × 生物资讯”的最新进展,欢迎关注

