夜雨聆风
夜雨聆风Kiran Gopinathan
最近,我一直在思考如何搭建脚手架,以及如何使用语言来管理相互协调的 LLM 系统——新的编程语言可能是解决这一问题的理想方案。
我们正在撰写一篇非常有趣的论文,旨在开发一种有趣的编舞语言来描述多智能体工作流程——事实证明,尽管编舞对于任何实际的分布式协议来说都过于简单,但它实际上是一种相当简洁优雅的形式化方法,可以用来描述智能体之间产生的定制化交互,尤其是在我们结合博弈论之后。敬请期待,我们很快就会分享!
现在,我不断听到一种令人恼火的反馈,甚至来自其他本应更了解情况的验证研究人员,那就是他们对现状以及开发用于管理代理的形式化方法和语言的目标漠不关心。这种常见的说法最好用以下这段话来概括:
“解决代理协调问题的最佳办法就是等待几个月。”
该论点大致可以概括为:
- 当前多智能体LLM系统无法自主构建大规模软件(同意✅)。
- 归根结底,这是一个协调问题(同意✅)。
- 下一代模型将会更加智能(同意✅)。
- 下一代模型将不会出现协调问题(⁇ 哈 ⁇)。
主要含义是,构建用于描述和管理这些系统的语言和工具是一项西西弗斯式的任务;更新的模型必然会使它们过时,所有努力都将徒劳无功。
作为一名验证研究员,我认为这种妥协未免有些操之过急,也有些误入歧途:分布式系统领域有大量文献专门探讨这个问题,却被人们忽略了;此外,还有许多与模型能力无关的“不可能性”结论。即便下一代模型是通用人工智能(AGI)(哈哈),协调问题仍然是一个根本性的问题,仅仅依靠更智能的智能体也无法摆脱它。
在这篇博文中,我想详细阐述这个想法,并将多智能体软件开发问题分解成一个形式化模型,并建立与一些标准分布式系统不可能性结论的联系。无论参与者多么具备通用人工智能(AGI),分布式共识都是一项艰巨的任务。
软件开发的形式化模型
克劳德,帮我做一个记录食谱的应用程序。千万别出错。
我们可以将多智能体综合问题正式建模如下:
给定提示
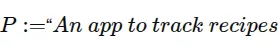
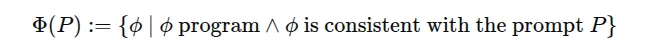
关键在于,自然语言提示本质上是不够明确的——也就是说,可能存在多个程序都符合该提示。当我们使用LLM构建和编写软件系统时,实际上是要求LLM从这众多元素中选择一个。
相反,当我们进行多智能体软件开发时,即我们启动多个智能体时,A1, ... An,
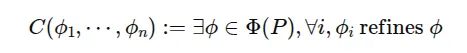
换句话说,这其实就是一个大型分布式共识问题。
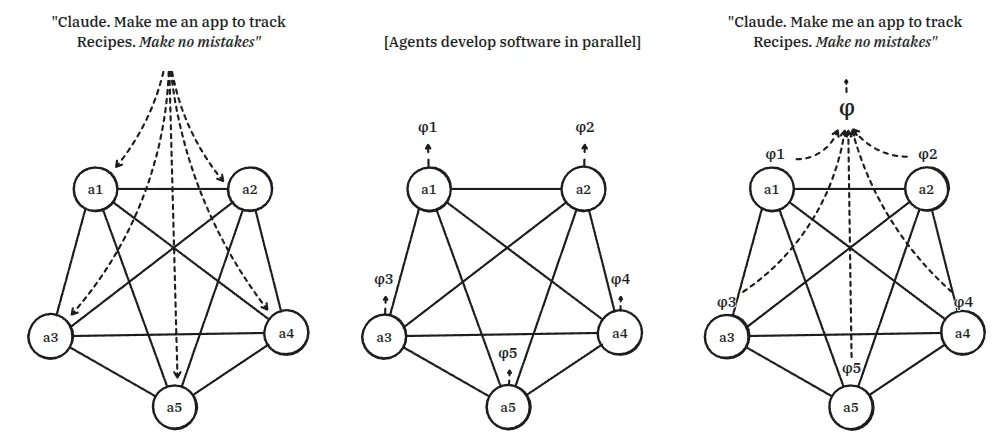
换句话说,用户的提示
这本质上是一个共识问题,因为代理 a1, ... ,an 必须同时工作以生成他们的软件制品Φ1, ...,Φn
这真的是一个分布式共识问题吗?
在我们完成智能体软件开发的正式模型之际,我想花一点时间来驳斥一些显而易见的反驳意见。
- 为什么是P
- 这个问题本质上是并发的吗?向软件系统投入多个智能体的动机超出了本文的讨论范围,但一旦我们做出这个决定,并且有多个智能体在处理我们的任务,那么问题本质上就是并发的(无论它们是并行工作还是在单个线程上交错工作),我们就必须解决协调问题。
- 难道我们不能设置一个统一的监管者来决定所有选择吗?为什么不让各个代理并行提交方案,然后由某种监管者来管理合并到共享代码库中的 PR 呢?想法不错!Git 仓库是协调并行软件开发的常用方法,但你并没有解决根本的并发问题,充其量只是把自己硬编码到了一种并发方案中,而且这种方案并不理想:当一个设计方案被选中并合并到代码库中后,那些需要重新基于当前代码的工作怎么办?如果存在冲突怎么办?一些工作注定会丢失。
我在这里想要表达的关键点并非是说你不能在忽略并发问题的情况下进行多智能体软件开发——显然,有人在不使用 Paxos 的情况下,也成功地利用智能体进行了软件开发——而是说,这种视角有助于我们预见如何通过协调工作流来解决这些根本性的并发问题。当然,如果请我喝几杯,我或许还会更进一步,认为如果我们想要多智能体软件开发真正实现规模化,那么这些问题就必须认真思考并解答。
多智能体软件开发的不可能结果
现在我们有了这个正式的智能体软件开发模型,是时候看看这篇文章的成果了!让我们把它与分布式系统联系起来,并尝试勾勒出一些不可能的结果。
多智能体系统的FLP 定理(安全性、活性、容错性,三者任选其二)
当然,我们还能从哪里开始呢?当然是从 FLP 开始啦,哦,我亲爱的 FLP。Fischer、Lynch 和 Paterson 的开创性论文《一个故障进程下分布式共识的不可能性》(https://groups.csail.mit.edu/tds/papers/Lynch/jacm85.pdf)确立了一个基本的不可能性结论,该结论决定了任何异步分布式系统(是的!这其中也包括我们)的共识。
FLP 定理(Fischer 等人,1985 年):在任何分布式系统中,如果消息有任意延迟,并且至少有 1 个节点发生崩溃故障,则没有确定性协议可以保证所有非故障节点在有限的时间内达成共识。
在深入分析该定理的含义之前,我想先花点时间论证一下,FLP 的假设(异步消息、崩溃故障)确实适用于我们的协议:
- 异步消息——消息向 LLM 的传递通常是异步的。LLM 通常负责确定何时读取消息,并且可以任意延迟读取时间。然而,当一个 LLM 代理尝试向另一个 LLM 发送消息时(无论是通过共享文件系统、消息传递队列还是其他任何辅助机制),消息何时会被另一个 LLM 接收通常取决于该 LLM 自身——例如,当其完成推理跟踪时,或者当其调用的程序或工具完成时。总而言之,我们无法对消息传递时间设定限制。
- 崩溃失败——这种情况无需过多解释,但代理程序似乎总是乐于自毁前程。这里的崩溃失败不仅指进程本身终止,也可能指代理程序运行了一个永远不会结束的工具(例如,一个意外陷入循环的 bash 脚本等等)。有时,它们可能只是
pkill自身崩溃。总之,代理程序可能会在未发出任何通知的情况下崩溃。
那么,这对我们来说意味着什么呢?具体来说,这意味着在任何多智能体系统中,无论智能体多么聪明,它们永远无法保证能够同时做到这两件事:
- 确保安全——即开发出符合用户规范的优秀软件。
- 保持实时性——即始终就最终软件模块达成共识。
你可能会对这种“实时性”部分感到惊讶,因为在大多数工作流程中,代理似乎总是会取得进展并终止,但这并不意味着它们会达成共识——事实上,我看到的一种非常常见的模式是一种循环,在设计决策上反复摇摆,一个代理选择一个设计决策,另一个代理撤销更改,选择另一个决策,然后它们就循环往复。
从这个角度来看,另一个有趣的见解是,当代理运行在共享机器上时,我们或许能够比纯粹的崩溃故障模型做得更好——特别是,运行类似 ` ps | grep claudeetc` 这样的命令可能相当于一个故障检测器,我们可以从中获得更强的共识界限。具体来说,Chandra 和 Toueg 的论文《可靠分布式系统的不可靠故障检测器》(https://www.cs.utexas.edu/~lorenzo/corsi/cs380d/papers/p225-chandra.pdf)基于 FLP 模型,证明了在 FLP 设置下达成共识的前提是,代理可以访问一个(可能不可靠的)故障检测器小工具,该小工具会报告其他代理是否仍然存活。如果代理对应于进程,并且进程存活等同于进展(这种情况并非总是如此1),那么 `etc`ps或许能给我们提供类似的结果。因此,由此得出的一个结论可能是,为 LLM 提供一个工具来检查其他代理的存活状态。
多智能体软件开发中的拜占庭将军问题
我想勾勒出与之相关的第二个不可能结果,它稍微微妙一些,但仍然值得思考:兰波特的“拜占庭将军问题”。
在分布式系统中,拜占庭节点是一种建模概念,对应于参与者发生故障的最坏情况假设;虽然像 FLP 这样的定理假设当服务器发生故障时,它会崩溃并停止参与协议,但拜占庭节点可能确实如此,或者它们可以做任何事情,也就是说,它们可以以任意方式偏离协议,例如伪造来自其他用户的消息、向不应该接收消息的参与者发送消息或重复先前的消息等等。
拜占庭故障模式真的与多智能体软件开发相关吗?虽然这种故障模型略显保守——我们的智能体肯定不会主动尝试破坏系统——但我认为在我们的场景中,这个模型仍然值得思考,因为拜占庭故障似乎能够很好地捕捉到对输入提示的“误解”这一概念。误解提示的智能体,实际上可以被视为协议中的一个拜占庭智能体,它会主动阻挠其他参与者构建正确的软件系统。在存在这类智能体的情况下,我们还能达成共识吗?
拜占庭将军定理(Lamport-Shostak-Pease,1982):在任何同步消息传递系统中,
对于可能任意偏离协议的拜占庭代理,只有当进程总数为零时,诚实进程之间才能达成一致。n>3f+1。
所以具体来说,根据这种解释,如果我们加速旋转
这里的关键观察是,Lamport 的结果为我们能够容忍的最大误解数量设定了一个硬性界限,以确保软件开发能够真正实现。这并非更智能的智能体或更优秀的LLM就能解决的问题。我们的合成问题本质上是欠定的,因此智能体总是可能出现误解。这项分析的一个可操作的结论是,虽然我们无法减少误解的数量,但
延伸阅读
除了 FLP 和拜占庭将军问题之外,还有一些其他重要的分布式系统成果值得在多智能体软件开发的背景下思考,但具体的链接留给读者自行探索 :) :
- 共同知识(Halpern & Moses,1990) ——本文定义了一个形式模型,用于推理分布式系统中认知知识的流动,并建立了此类系统中共同知识存在的不可能性结果。
- 部分同步(Dwork、Lynch 和 Stockmeyer,1988) ——Dwork 等人的部分同步模型是解决 FLP 问题的标准方案。该模型的关键在于对消息延迟设定上限——在实际的分布式系统中,设备不会无限期地等待消息到达,而是会发生超时并请求重发。通过这种简化,共识问题得以解决,但代价是消息复杂度的增加。
- CAP 定理(Gilbert & Lynch,2002) ——当然,任何关于“流行”分布式系统的文章,如果不提及备受赞誉的 CAP 定理,都是不完整的!CAP 定理与 FLP 定理类似,提供了一个不可能性结果,该结果指出任何分布式系统最多只能在以下三者中做出选择:一致性(代理对其内部视图达成共识)、可用性(代理最终能够处理请求)和分区容错性(即使网络的某些部分无法访问,代理仍然可以继续执行任务)。2
结论
那么,这又将我们引向何方呢?我在这篇文章中一直论证的是,多智能体软件开发本质上是一个分布式系统问题,因此,它继承了文献中一些不可能性结论。FLP定理告诉我们,分布式系统不可能同时具备安全性、活性和容错性。Lamport的拜占庭将军问题告诉我们,在达成共识之前,拜占庭进程的精确界限是不可能的。值得注意的是,这两个结论都不依赖于智能体智能。
重点并非多智能体软件开发不可行——如今人们确实在交付带有智能体的实际软件,而且明天他们很可能会交付更多粗制滥造的产品。我的论点在于,这些人目前是通过隐式地解决这些协调问题,通常是通过一些缺乏深思熟虑的保证或故障模式的临时机制。分布式系统文献对所有这些机制都有精确的形式化描述,四十年来积累了关于它们能够解决什么问题和不能解决什么问题的定理,以及关于何时何地应该应用不同技术的明确规则。
这让我们自然而然地回到了引言中的那句话:“解决智能体协调的最佳方案就是等待几个月。”也许是这样。我承认这一点,但即便如此,上述的不可能性结果并非当前模型能力的暂时性缺陷;它们不会随着智能体变得更智能而消失;它们是该领域固有的属性。更智能的智能体或许可以缩小算法中的常数,但它们不会,也不可能消除限制。如果我们想要多智能体软件开发真正实现规模化,那么迟早有人必须真正着手设计协议、语言和工具,将解决底层协调问题作为首要任务,而不是寄希望于问题自行消失。
脚注
1 这并不能完全反映代理是否真的在运行并取得进展,因为粗粒度的进程视图无法捕捉到代理挂起在无限工具调用中,或者代理已经偏离轨道并完全停止在代码库上工作的故障模式。
2 我没有花太多时间思考如何过渡到我们的环境,但从宏观层面来说,我认为对于智能软件开发而言,分区容错性可能不是一个必要条件。
kirancodes.me