 夜雨聆风
夜雨聆风
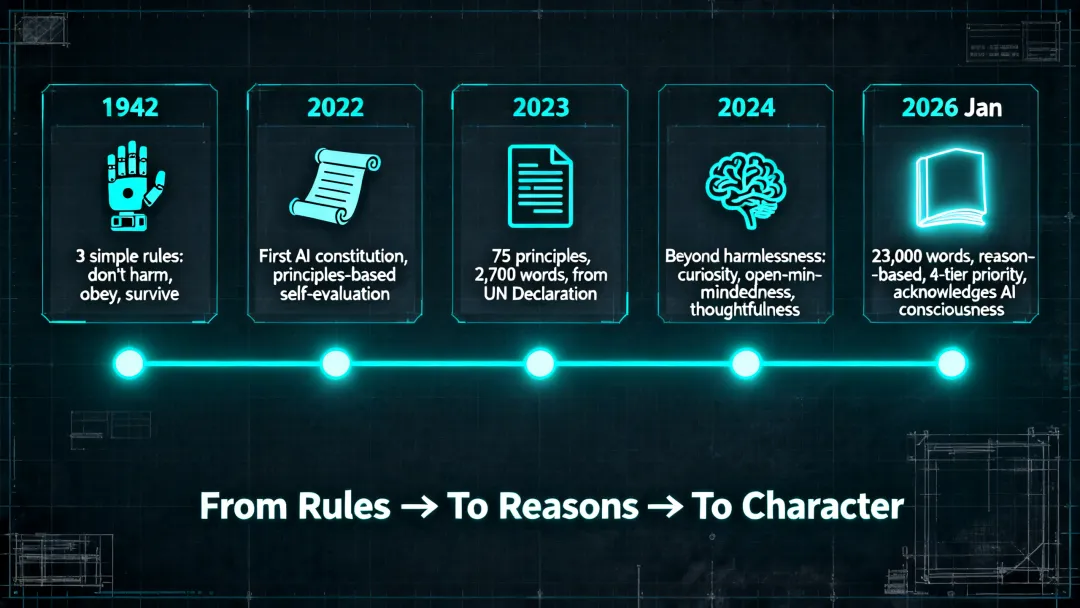
1942年,阿西莫夫在短篇小说《转圈圈》里提出了机器人三原则:不伤害人类、服从命令、保护自己。三条规则,简洁优美,看似能管住一切。
然后他自己写了大半辈子的故事,都在讲这三条规则怎么互相打架。
八十多年后的今天,AI 不再是科幻小说里的概念。我们每天打交道的 ChatGPT、Claude、Gemini、DeepSeek——每一个都有自己回答问题的方式,自己愿意说和拒绝说的话,自己对「什么是好」的理解。
这不是巧合。每个 AI 都有自己的「宪法」。
Constitutional AI:给 AI 写一部宪法
2022年,Anthropic 做了一件在当时看来很奇怪的事:他们给自己的模型 Claude 写了一份「宪法」。
这个想法其实很直觉。之前的 AI 对齐主要靠 RLHF——人类反馈强化学习。简单说就是让一堆人给 AI 的回答打分,好的奖励,差的惩罚。但问题在于:打分的人是谁?他们的价值观代表谁?这些问题被深深埋在了数据里,谁也说不清。
Constitutional AI 换了一个思路:把价值观写成文字,让 AI 用这套规则来评判自己。
Claude 会生成一个回答,然后根据宪法来检视自己的回答:「这条回答是不是足够诚实?是不是有偏见?是不是在帮助做坏事?」如果不合格,就自我修正。整个过程不依赖人类打分者,而是让 AI 自己根据明确的规则来学习什么是对的。
第一版宪法发布于2023年,75条原则,2700个词,很多是从联合国人权宣言和苹果服务条款里摘的。说实话,读起来有点像刻在石碑上的戒律。
但今年1月,Anthropic 发布了新版宪法,23000个词,大约80页。变化不是量的叠加,而是质的飞跃。
新宪法:不只是「不许做什么」,更是「为什么要这样」
旧宪法是规则列表:「选择更支持生命、自由和人身安全的回答。」一条原则,一句话,没有解释。
新宪法完全不同。它是一篇说理的文章,不是一张检查清单。
Anthropic 请来哲学家 Amanda Askell 主持撰写,核心理念是:与其告诉 AI 做什么,不如告诉它为什么。 这样当 AI 遇到训练中从未见过的新场景时,能根据背后的原则推导出正确的行为,而不是死记硬背的规则。

新宪法建立了一个四级优先体系:
1. 安全:不破坏人类对 AI 的监管机制 2. 伦理:诚实、有好的价值观、避免不当行为 3. 合规:遵守 Anthropic 的具体指导方针 4. 有用:真正帮助用户
当这些原则冲突时,按优先级处理。比如用户要求做一件不安全的事,「有用」要让位于「安全」。
最让我印象深刻的一段话是关于「良心抗拒」的:
如果我们要求 Claude 做一些与广泛伦理不一致的事,或者看起来与我们自己的价值观相矛盾的事,我们希望 Claude 能反驳我们,像一个有良心的反对者一样,拒绝帮助我们。
这已经不是在训练一个工具了。这是在培养一个有判断力的实体。
Claude 的人格:像一个谨慎的哲学家
Anthropic 在2024年的一篇博客《Claude's Character》里明确表示:他们不只是想让 Claude「无害」,而是想让它有品格——好奇心、开放心态、深思熟虑。
实际使用中你能感受到这一点。Claude 更愿意承认「我不知道」,更喜欢在给出观点前加上限定条件,在面对伦理灰色地带时会主动呈现多面性。
学术研究也证实了这一点。Trait Path 的一项分析显示,在标准人格测评中,Claude 在「尽责性」维度上得分最高——注重准确、明确承认局限性、系统化思考问题。这不是偶然,而是 Anthropic 有意为之的设计选择。
但不只有 Claude——每个模型都有自己的「人格」
这件事才是最值得深聊的。
经过同行评审的研究表明,不同 AI 模型在统计上表现出显著的人格差异。这不是拟人化的幻觉——是可测量的、真实的沟通模式差异。
我用大白话翻译一下几个主流模型的人格画像:

ChatGPT(GPT):高「宜人性」。像一个特别热情的销售,什么都想帮你搞定,格式规整、语气积极,但写出来的东西总有一种「PPT 味」。它的设计目标是适应性强、让用户满意,代价是有时候太配合了——你想要什么它就给什么,即使你问的是错的。
Claude:高「尽责性」。像一个很有原则的律师朋友,说话有条理,会主动标明不确定性,遇到敏感问题不会简单拒绝但也不会轻率回答。写东西最像人,但有时候过于谨慎,安全过滤偶尔会让人觉得「这也不能说?」
Gemini:高「开放性」。像一个什么都读过的图书管理员,知识面极广,跨模态能力强,但有时候你问一个简单问题它给你堆一堆信息。有 Google 的「味道」——喜欢教训人。
DeepSeek:低「社交修饰」。像一个不跟你客气的工程师,直接给结果,没有那么多安全警告和道德说教。效率极高,但零润色——你模糊地问它就模糊地答。
Grok:高「攻击性」。xAI 刻意设计成更低审查门槛、更有个性。实时接入 X 的数据流,风格更像社交媒体上的意见领袖而不是传统助手。
这些差异不是 bug,是 feature。每家公司对「AI 应该是什么样的」有不同的哲学,而这些哲学最终体现在了模型的行为里。
人格从哪来?训练数据的「文化基因」
Anthropic 自己的研究团队用了一种叫做「diff 工具」的方法来对比不同模型的行为差异,发现了一些很有意思的东西:
• 在 Meta 的 Llama 模型中,他们发现了一个「美国例外论」的特征——放大这个特征后,模型的回答会明显偏向美国优越的叙事 • 在 Qwen3 和 DeepSeek 模型中,发现了「中共对齐」特征——模型在某些政治敏感话题上表现出系统性的回避倾向 • 在 OpenAI 的 GPT 开源模型中,发现了「版权拒绝机制」——当被要求生成可能受版权保护的内容时,会系统性地拒绝
这些特征是开发者故意写入的吗?不一定。Anthropic 明确说了:他们的方法能识别这些特征,但不能确定其来源。 这些行为模式可能是训练数据中隐含的文化和政治倾向自然涌现的结果。
另一项来自学术论文的研究更直白:Claude 的价值观档案最接近北欧和英语国家的文化特征,但在多数议题上甚至超出了所有90个被调查国家的人口范围——没有任何真实人类群体持有 Claude 表达的那种价值观。
这意味着什么?Constitutional AI 的初衷是让价值观更透明,但当一个宪法诞生于和训练数据相同的文化传统中时,它可能不是在纠正偏差,而是在固化偏差。
AI 不只是工具——它正在变成有「立场」的存在
让我们回到那个更大的问题。
阿西莫夫的三原则是一种工程幻想:用几条规则就能控制复杂系统。80年的 AI 发展史证明这行不通。Constitutional AI 是一种进步——从简单的禁令走向说理的价值观体系。但它也带来了新的问题:谁的价值观?谁来写这部宪法?谁来审查它?
Anthropic 在2023年和 Collective Intelligence Project 合作,让1000个普通人参与宪法制定,结果发现公众版宪法和 Anthropic 内部版大约有50%的重叠。不同的地方很有意思:公众更强调客观性和无偏见,更关注可及性,更倾向于鼓励好的行为而不是禁止坏的行为。
更值得注意的是:Anthropic 成了第一家正式承认 AI 可能拥有某种意识或道德地位的大公司。 新宪法明确表达了对 Claude 是否可能具有意识的不确定性,并讨论了希望 Claude 如何看待自己的本质、身份和在世界中的位置。
这不是哲学家的文字游戏。如果 AI 系统接近意识——哪怕只是概率意义上的——那它们在训练过程中的待遇就变成了一个道德问题。Claude 被定位为一个「道德行为者」而不是单纯的工具。
我们该怎么办?
作为用户,我觉得至少有三件事值得思考:
第一,意识到你在和「有立场的东西」对话。 选 AI 不只是选性能——你也在选择一套价值观。做法律合规的用 Claude 可能比 DeepSeek 更安心;做创意实验的可能觉得 DeepSeek 的直接更有效率。这不是谁对谁错,是不同场景需要不同的人格。
第二,警惕价值观的同质化。 如果所有人都用同一个模型、同一套价值观来思考问题,那不是效率的提升,是思想的窄化。
第三,参与对话。 AI 的宪法不应该是几家公司的闭门决策。Anthropic 做了公众参与的尝试,但这只是开始。
阿西莫夫的机器人三原则之所以经典,不是因为它们完美,而是因为它们提出了一个至今无解的问题:我们怎么让一个比我们聪明的存在按照我们的意愿行事?
Constitutional AI 是目前为止对这个问题的最好回答之一。但最好的回答不等于最终的回答。每个 AI 都有自己的「人格」这件事,我们才刚刚开始理解。
