 夜雨聆风
夜雨聆风6款开源AI知识库横评:18G内存的DS224+,到底该装哪个?
在正式搭建前,对比了6款主流开源知识库,最终选出最适合NAS入门玩家的方案。前排提醒:本文为个人实践记录,所有资源数据均来自官方文档与实测,不代表任何商业立场。
写在前面
上一篇我分享了DS224+的装机和基础配置,有朋友问:
"知识库这么多,到底装哪个?"
这个问题我也问过自己。
网上的教程要么直接给你一个答案,要么列一堆参数让你自己看。我想做的是:把我选型时的思考过程完整还原,让你看完之后能做出自己的判断。
我的硬件背景:
• 群晖 DS224+,J4125 四核 CPU • 内存扩容至 18GB(实际显示约 17.4GB) • 2 × 4TB 希捷酷狼
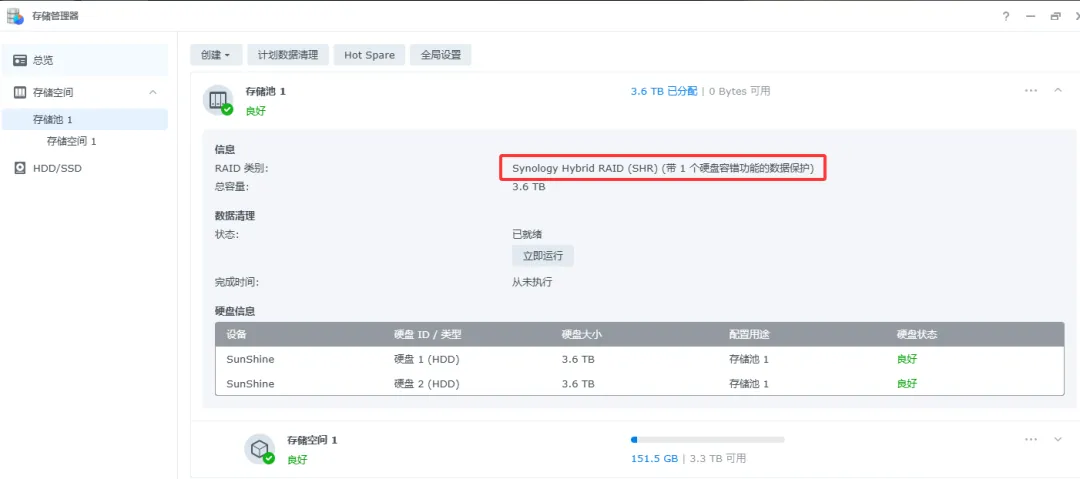
💡 补充上篇文章信息差:当你插入双盘的时候,DS224+ 默认会组建 RAID SHR 模式。
SHR 是群晖的智能存储池,带 1 块硬盘容错的数据保护机制。也就是说,两块 3.6T 的硬盘,实际可用容量只有 3.6T(约 7.2T 减去 1 块冗余),而非 3.6T + 3.6T = 7.2T。
查看路径:存储管理器 → 存储池 1
一、候选名单:6款主流开源知识库
以下项目均满足三个基本条件:
1. ✅ 支持 Docker 部署 2. ✅ 支持 Ollama / 本地模型集成 3. ✅ 在 NAS 社区有实际部署案例
1. AnythingLLM
一句话定位:个人知识库的最简方案,开箱即用。
Mintplex-Labs 开发的"all-in-one" AI 生产力工具,强调极简部署、无代码 Agent 和隐私优先的文档聊天。
核心亮点:
• 约 3 个主要容器(frontend + server + collector),单体化设计 • 支持 PDF、DOCX、TXT 等多格式,拖拽上传 + 来源引用 • 无代码 AI Agent 构建器 • 向量数据库默认 LanceDB,支持 PGVector、Pinecone 等切换 • 多用户权限 + 嵌入式聊天 Widget
资源需求:
DS224+ 适配评分:⭐⭐⭐⭐⭐18GB 内存完全够用,J4125 跑起来不费力,是 NAS 玩家的首选。(有坑请看下文)
License:MIT,完全免费,无任何商业限制。
2. Dify
一句话定位:AnythingLLM 的企业级扩展版,功能最全但最重。
LangGenius 开发的低代码 LLM 应用开发平台,集成完整 RAG 管道 + Agent 工作流 + LLMOps。
核心亮点:
• 多服务架构,核心约 6-8 个容器(api、worker、web、db、redis + 向量DB) • 可视化 Workflow 画布 + Prompt IDE • 完整 RAG 管道(文档摄入、检索、多格式支持) • LLMOps(日志监控、性能分析、数据集优化) • 50+ 内置工具的 Agent
资源需求:
DS224+ 适配评分:⭐⭐⭐⭐能跑,但多服务架构吃内存,建议给各容器设置内存上限,避免 NAS 卡死。
License:自托管完全免费(Apache 2.0 衍生协议)。
3. RAGFlow
一句话定位:文档解析能力最强,但资源门槛最高。
Infiniflow 开发,专注"深度文档理解",对扫描件、表格、图片的解析能力碾压其他方案。
核心亮点:
• 单容器高度集成,部署反而简单 • 深度文档解析(PDF/DOCX/Excel/图片/扫描件) • 带引用 + 可追溯的 grounded 回答,极大减少幻觉 • 支持 Confluence/S3/Notion/Google Drive 等数据源同步
资源需求:
| 16GB |
DS224+ 适配评分:⭐⭐⭐18GB 内存刚好踩线,但 J4125 的 CPU 会成为瓶颈,文档解析会很慢。不推荐在 DS224+ 上跑 RAGFlow,除非你的知识库以复杂文档(扫描件、表格)为主。
License:Apache-2.0,完全免费。
4. FastGPT
一句话定位:企业知识库 Q&A 场景的强力选手。
Labring 开发,开箱即用的数据处理 + 可视化 AI 工作流,特别适合企业级知识库问答。
核心亮点:
• 至少 3 个主要容器(fastgpt + sandbox + mcp_server) • 多知识库复用 + Chunk 编辑 + 混合检索 + 重排序 • 可视化 Flow 工作流(Agent/插件/RPA 节点) • 完整调用链日志 + 引用反馈
资源需求:
DS224+ 适配评分:⭐⭐⭐⭐能跑,但注意 License:商业 SaaS 使用受限,需要联系获取商业许可。个人使用没问题。
5. Flowise
一句话定位:最轻量的可视化 Agent 构建器,拖拽即用。
基于 LangChain 的低代码工具,单容器,Node.js 基础,资源占用极低。
核心亮点:
• 1 个主容器,部署最简单 • 可视化拖拽构建 Agent/工作流 • 100+ LangChain 节点集成 • API 端点 + 可嵌入 UI 组件
资源需求:
DS224+ 适配评分:⭐⭐⭐⭐⭐最轻量,DS224+ 跑起来毫无压力。但 RAG 能力相对基础,适合构建 Agent 而非知识库。
License:Apache-2.0,完全免费。
6. Langflow
一句话定位:开发者向的可视化工作流构建器,可导出为代码。
Python-based,适合有 LangChain 经验的开发者自定义 RAG/Agent。
核心亮点:
• 1 个主容器,Python 运行 • 可视化构建 + 导出为 API/JSON/Python 代码 • MCP Server 部署 + 可观测性(LangSmith/LangFuse) • 支持所有主流 LLM + 向量 DB
资源需求:
DS224+ 适配评分:⭐⭐⭐⭐适合有开发背景的玩家,纯知识库场景不如 AnythingLLM 直接。
License:MIT,完全免费。
二、横向对比一览
| 容器数量 | ||||||
| RAG深度 | 最强 | |||||
| 最低内存 | 16GB | |||||
| 部署难度 | ||||||
| 最佳场景 | ||||||
| License限制 | ||||||
| DS224+推荐度 |
三、我的选择:AnythingLLM
综合以下几点,我选择了 AnythingLLM:
① 资源最友好DS224+ 的 J4125 CPU 不是性能怪兽,AnythingLLM 的 3 容器架构对 CPU 和内存的压力最小,18GB 内存有充足余量留给 Embedding 模型和 LLM 推理。
② 部署最简单对于"验证 NAS 能否跑 AI 知识库"这个目标,AnythingLLM 是最快的路径。不需要配置复杂的微服务,不需要调试多个容器之间的依赖关系。
③ 功能够用个人知识库场景:文档上传 → 向量化 → 语义检索 → 对话,AnythingLLM 全部覆盖,而且支持接入本地 Ollama 和云端 API(火山引擎 DeepSeek、OpenAI 等)。
④ 完全免费,无后顾之忧MIT 协议,个人和商业使用均无限制。
如果你的需求不同:
• 文档以扫描件/表格为主 → 选 RAGFlow(但建议升级内存到 32GB) • 需要可视化工作流 → 选 Dify 或 Flowise • 有 LangChain 开发经验 → 选 Langflow
四、关于 18GB 内存的决定性作用
很多人问:DS224+ 原装 2GB 内存能不能跑?
不能。
跑 AI 知识库,内存是核心瓶颈,不是 CPU,不是硬盘。
| 合计 | ~10-19GB |
18GB 内存是这套方案能跑起来的最低可行配置。
如果你只接云端 API(不跑本地模型),内存需求会大幅降低,8GB 就够用。
五、注意事项
⚠️ SSD 缓存:DS224+ 支持 SSD 缓存,但 AnythingLLM 的向量数据库(LanceDB)是随机读写密集型,如果你有 M.2 SSD,强烈建议开启读写缓存,能明显提升检索速度。
⚠️ 数据备份:知识库的向量数据存储在 Docker Volume 中,NAS 重装或 Docker 重置会导致数据丢失。建议定期将
/volume1/docker/anythingllm/目录备份到另一块硬盘或云端。
⚠️ 内网穿透安全性:如果你计划通过外网访问知识库,请务必开启 AnythingLLM 的用户认证功能,不要将服务直接暴露在公网。
📌 免责声明
本文仅为作者个人实践记录与技术交流,不代表任何官方立场。
• 所有资源数据来自官方文档与个人实测,可能随版本更新而变化 • 折腾有风险,操作需谨慎,作者不对任何因参考本文操作导致的损失承担责任 • 本文不构成任何商业建议或产品推荐
系列文章:
• 上一篇:入坑第一步!群晖DS224+开箱、装机与基础配置全攻略 • 下一篇:异地也能访问!DS224+配置Tailscale组网+AnythingLLM部署实战
