科技行业趋势深度洞察,前沿Tech领域实时动态,创新科技方向精准聚焦。欢迎关注公众号:科创猫。
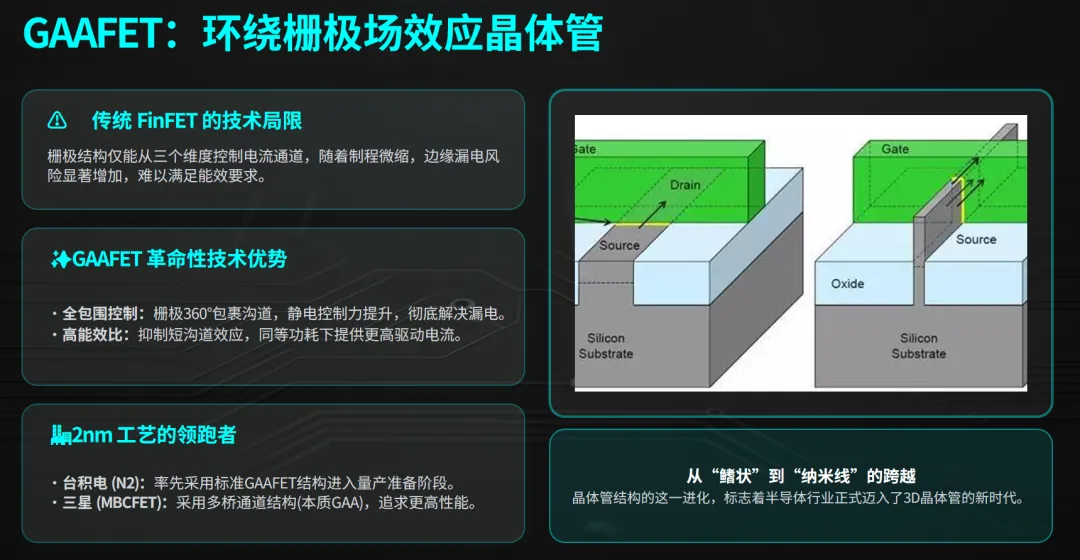
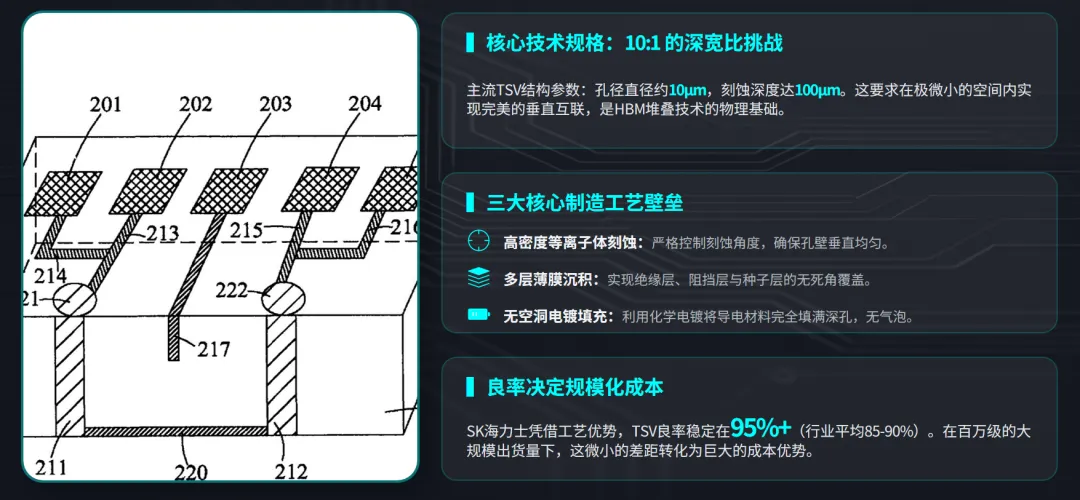
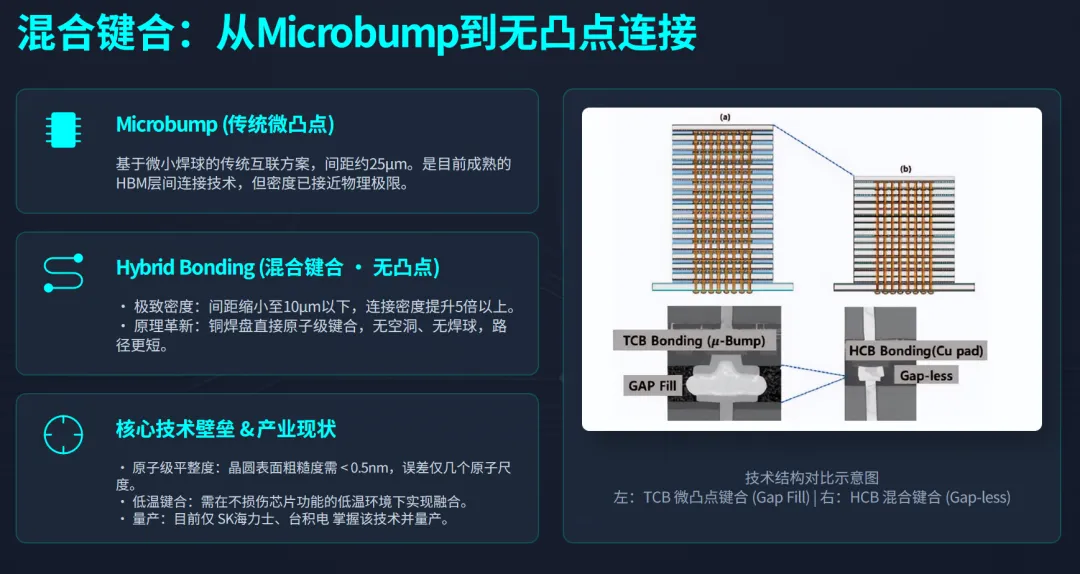
当GPU算力每9个月翻倍,存储、互联、散热、承载却在以各自的节奏艰难追赶。这不是产能问题,是物理极限问题。 2026年,全球AI硬件市场规模突破5800亿美元。数字背后,是一场静默的 工程极限挑战 :7nm以下晶体管漏电控制、TSV硅通孔深宽比、112G SerDes信号完整性、DK值低于4的介电材料……每一个看似枯燥的参数,都是制约算力释放的真实瓶颈。 本文试图回答一个产业研究者真正关心的问题: 在算力狂奔的背面,技术本身正在经历怎样的突围? 一、计算芯片: 物理极限与生态护城河 1.1 制程不再是唯一答案 英伟达GB300采用台积电N2(2nm)制程,晶体管密度较5nm提升约1.8倍。但一个被忽略的事实是: 单纯靠制程微缩带来的能效提升已从过去每代30%以上降至15%左右 。 原因在于短沟道效应和漏电控制的物理极限。当栅极长度进入2nm以下,量子隧穿导致的静态功耗急剧上升。 台积电的解决方案是 GAAFET(环绕栅极场效应晶体管) ,将栅极从平面包围沟道,实现更好的静电控制。三星更激进,采用 MBCFET(多桥通道FET) ,但良率爬坡缓慢。 这意味着:未来AI芯片的性能提升,将越来越依赖 架构创新 (如英伟达的Tensor Core升级、FP8/FP4精度支持)和 先进封装 (如Chiplet、3D堆叠),而非纯制程红利。 1.2 CUDA的“软件硬化”趋势 CUDA生态常被简单理解为开发者工具链。但从技术角度看,CUDA的真正壁垒在于: 它已经深度嵌入到从编译器、指令集到微架构的每一个层级 。英伟达每一代新硬件的性能释放,都需要CUDA做针对性优化(如Hopper架构的TMA单元)。这种“硬件定义软件、软件固化硬件”的正反馈循环,使得任何竞争对手不仅需要造出等效算力的芯片,还需要重写整个软件栈——这不是3-5年能完成的任务。 1.3 推理芯片的技术路线分化 推理场景不需要FP64/FP32高精度,更看重INT8/FP8能效。这催生了三类技术路线: GPU降频版 (如英伟达L4):兼容性好,但能效比不极致。 ASIC (如谷歌TPU、亚马逊Inferentia):脉动阵列架构,能效比可达GPU的3-5倍,但算法固定后无法灵活调整。 数据流架构 (如Cerebras、Groq):消除片上缓存,用SRAM代替HBM,延迟极低,适合实时推理,但成本高。 国内推理芯片多数走ASIC路线(寒武纪思元系列),少数探索数据流(如墨芯)。技术差距主要体现在 编译器的成熟度 和 算子库丰富度 ——这又是软件生态问题。 二、HBM: 一场“垂直堆叠”的工艺战争 2.1 TSV:硅通孔的深宽比极限 HBM的核心技术是 TSV(Through-Silicon Via) ——在DRAM芯片上打孔,填充导电材料,实现垂直互联。当前主流HBM3E使用 10μm直径、100μm深度 的TSV,深宽比10:1。制造过程中需要解决:高密度等离子体刻蚀的垂直度控制、绝缘层/阻挡层/种子层的均匀沉积、无空洞电镀填充。 SK海力士的领先之处在于: 批量回流填充技术 和 晶圆级键合 的良率控制。三星和美光的TSV良率约85-90%,而SK海力士可做到95%以上。这5个百分点的差距,在百万级出货量下就是巨大的成本优势。 2.2 混合键合:从 microbump 到无凸点 传统HBM堆叠使用 microbump(微凸点) ,间距约25μm。HBM4开始引入 混合键合(Hybrid Bonding) ,间距可缩至10μm以下,密度提升5倍以上。混合键合的难点在于:两个晶圆的铜焊盘需要原子级平整度(粗糙度<0.5nm),并在低温下实现直接键合。这需要 化学机械抛光(CMP) 和 等离子激活 的极致配合。 目前只有SK海力士和台积电在混合键合上实现量产,三星仍在攻关。 2.3 热管理:堆叠后的“散热地狱” 8层HBM堆叠后,总厚度约720μm,单位面积发热密度超过100W/cm²(接近核反应堆)。热量从底层DRAM向上传导,顶层芯片温度可高出底层30°C以上,导致漏电增加、刷新周期缩短。 解决方案包括: 导热填充材料(TIM) 、 背面金属化 、以及将HBM与逻辑芯片 并排放置而非堆叠 (CoWoS-S vs CoWoS-L)。这是材料科学和热力学的交叉难题。 2.4 国产HBM的技术差距 长鑫存储HBM3良率突破80%是重要里程碑,但距离SK海力士仍有差距。主要瓶颈在于:TSV刻蚀设备(受限于Lam Research、TEL出口管制)、键合材料、以及 测试环节 ——HBM需要针对每一层芯片进行Known Good Die筛选,测试成本占总成本30%以上。国产测试机台(如华峰测控)在HBM领域仍需验证。 三、高速互联: 从NRZ到CPO的物理层革命 3.1 调制格式:NRZ→PAM4→CPO的必然 传统光模块使用NRZ(不归零码),一个符号代表1bit。当速率超过25Gbps,信号衰减和串扰导致眼图闭合。于是行业切换到 PAM4(4级脉冲幅度调制) :一个符号代表2bit,相同带宽下速率翻倍。但代价是信噪比要求提高3倍(6dB),需要更精密的DSP和TIA。 800G/1.6T光模块普遍采用PAM4+DSP方案,但DSP功耗已占模块总功耗的50%以上。这就是为什么CPO成为必然—— 去掉DSP,用更短的物理距离换取无DSP传输 。 3.2 CPO的三大技术挑战 CPO将光引擎与交换ASIC共封装,理论上完美。但工程上三个难题: 热机械可靠性 :光引擎中的硅光芯片与交换芯片热膨胀系数不同,长期温度循环会导致光纤接口位移(亚微米级),引发光耦合损耗。 可维护性 :传统可插拔光模块损坏后热插拔更换;CPO中光引擎与交换芯片集成,一旦损坏需更换整个交换机,维修成本极高。 测试与标准化 :CPO需要在封装前对光引擎进行晶圆级测试,目前尚无成熟方案。接口标准(如CWDM8、LR8)也未统一。 产业判断:CPO会在2027-2028年率先用于超大规模数据中心(如谷歌、Meta的集群),普通场景仍以LPO(线性驱动可插拔)为主。LPO去掉DSP但保留可插拔,是功耗与可维护性的折中。 3.3 硅光技术的成熟度 硅光(Silicon Photonics)利用CMOS工艺在硅上制造光波导、调制器、探测器。核心优势是 集成度 和 低成本 (可利用现有晶圆厂)。但硅本身不是理想的光学材料:它的带隙是间接带隙,不能有效发光。因此需要 异质集成 ——将III-V族材料(InP、GaAs)键合到硅上作为光源。 中际旭创、天孚通信的硅光技术积累主要体现在 调制器 (基于载流子耗尽效应,速度可达50GHz以上)和 探测器 (Ge-on-Si)。而高端光源(如大功率CW激光器)仍依赖Lumentum、博通等海外厂商。 3.4 国产光芯片的突破与局限 源杰科技实现EML(电吸收调制激光器)和CW(连续波)激光器量产,打破海外垄断。但技术细节值得深挖:EML的 带宽 目前为50GHz,可支持53GBaud PAM4(即单通道100G),但1.6T光模块需要100GHz带宽(单通道200G),源杰的产品仍需迭代。CW激光器的 输出功率 和 线宽 也落后于博通。 国产光芯片的追赶路径是:从2.5G/10G低速芯片(完全自主)→25G芯片(部分自主)→50G芯片(突破)→100G芯片(研发中)。每一代都是材料生长(MOCVD)、端面镀膜、耦合封装的系统性工程。 四、PCB/CCL: 被忽视的材料科学竞技场 4.1 信号损耗的物理本质 AI服务器工作在56G/112G PAM4速率,信号频率高达28GHz/56GHz。在这个频段,PCB基材的两个参数决定一切: Dk(介电常数) :影响信号传播速度。Dk越低越好,但降低Dk通常需要引入更多氟或空洞,牺牲机械强度。 Df(损耗因子) :能量转化为热量的比例。Df每降低0.001,每米传输损耗可减少0.5dB。 普通服务器PCB使用FR-4(Dk~4.2,Df~0.02),AI服务器计算版PCB需要 Dk<3.5,Df<0.005 的极低损耗材料。这已经进入 聚四氟乙烯(PTFE) 或 碳氢树脂 的领域。 4.2 台光电子的计算版CCL垄断之谜 台光电子的M9/M10系列采用 PPE(聚苯醚)树脂体系 ,配合扁平玻璃布,实现了Dk 3.3、Df 0.003。为什么国内做不出来?三个原因: 树脂合成 :PPE的分子量分布和交联度控制是know-how,日本旭化成、台光电子的配方是几十年积累。 玻璃布处理 :电子布需要偶联剂处理,增强与树脂的结合。不同树脂需要不同偶联剂,这是界面化学的精细活。 认证周期 :英伟达对CCL的认证包括TCDK(温度系数)、CTE(热膨胀系数)、CAF(耐离子迁移)等几十项测试,一次认证耗时6-12个月。台光电子与英伟达联合开发了3代产品,形成了事实标准。 4.3 石英布的低Dk原理 菲利华的三代石英布Dk=3.8,低于普通E-glass(6.5-7.0)。原理在于:石英玻璃的硅氧四面体结构更松散,极化率更低。但石英纤维的 拉丝工艺 极难——熔融温度高达2000°C以上,且易析晶。菲利华掌握了 连续石英纤维 的拉丝技术,全球仅少数企业能做到。 五、技术路线图: 2026-2030年聚焦五个方向 基于以上技术拆解,我们认为未来五年产业研究应聚焦以下五个方向: 1. 2.5D/3D先进封装的异构集成 CoWoS、HBM混合键合、芯片间光学互联。核心问题是:当芯片制程逼近物理极限,封装将成为提升性能的主要手段。 2. 硅光与CPO的工程化突破 关键在于:高温可靠性、可维护性设计、以及低成本光源集成。2027-2028年是验证窗口。 3. 液冷技术的标准化 冷板式与浸没式谁将胜出?取决于TCO(总拥有成本)模型和行业标准制定。散热材料的导热系数提升也是隐蔽赛道。 4. 玻璃基板替代有机基板 玻璃基板具有更低的热膨胀系数和更高的平整度,适合超大尺寸封装。英特尔、三星已在布局,但玻璃的通孔(TGV)和金属化仍是难题。 5. 存算一体与近存计算 HBM本质上已经是“近存”(靠近计算),但真正“存内计算”(在存储阵列内完成运算)尚在实验室阶段。基于RRAM、MRAM的存算一体芯片,可能在未来3-5年进入原型验证。 结语:产业研究的价值在于追问“为什么” 5800亿美元的市场规模、42%的增速,这些数字只是结果。真正值得追问的是: 每一个“为什么”背后,都是材料科学、量子物理、精密制造的交叉前沿。AI硬件的本质,不是炫酷的芯片发布会,而是工程师们在原子尺度上与物理定律的持续博弈。 免责声明:本文内容是基于公开信息梳理,仅作为行业分析研究参考和知识分享,不构成任何投资建议,不对用户依据本文做出的任何决策承担责任。文中观点仅代表研究视角,不保证信息的绝对完整与准确;所提及企业、技术等仅作分析参考,不构成投资推荐或价值背书。行业政策、市场环境、技术发展均存在不确定性,读者须独立审慎判断、自主决策并自行承担相关风险。
 夜雨聆风
夜雨聆风