 夜雨聆风
夜雨聆风哈喽,大家好,我是刘小排。
今天 Anthropic 发布了 Claude Opus 4.7,朋友圈已经刷屏了。SWE-bench Verified 从 80.8% 涨到 87.6%,视觉分辨率翻了三倍,编码体感更稳——这些大家都在转,我就不重复了。
我想聊一件别人没怎么讲的事。
Anthropic 在 232 页的 System Card 里,有一句话细思极恐:
"during its training we experimented with efforts to differentially reduce cyber capabilities."
翻译:我们在训练 Opus 4.7 的时候,故意把它的网络安全攻击能力调低了一点。
这是 AI 历史上,第一次有一家公司公开承认:我给你的这个模型,是我亲手砍过一刀的。
这事就像,NVIDIA 为了出口,把 H100 砍成 H800 给中国市场——只不过这次是 Anthropic 把"完整版 Claude"砍成了"给你用的 Claude"。
一、有多少能力被砍掉了?
我带你看三组数字。
第一组:Firefox 147 漏洞利用测试。
Anthropic 之前和 Mozilla 合作修了一批 Firefox 147 的安全漏洞,然后把"能不能利用这些漏洞"变成了一个标准测试。
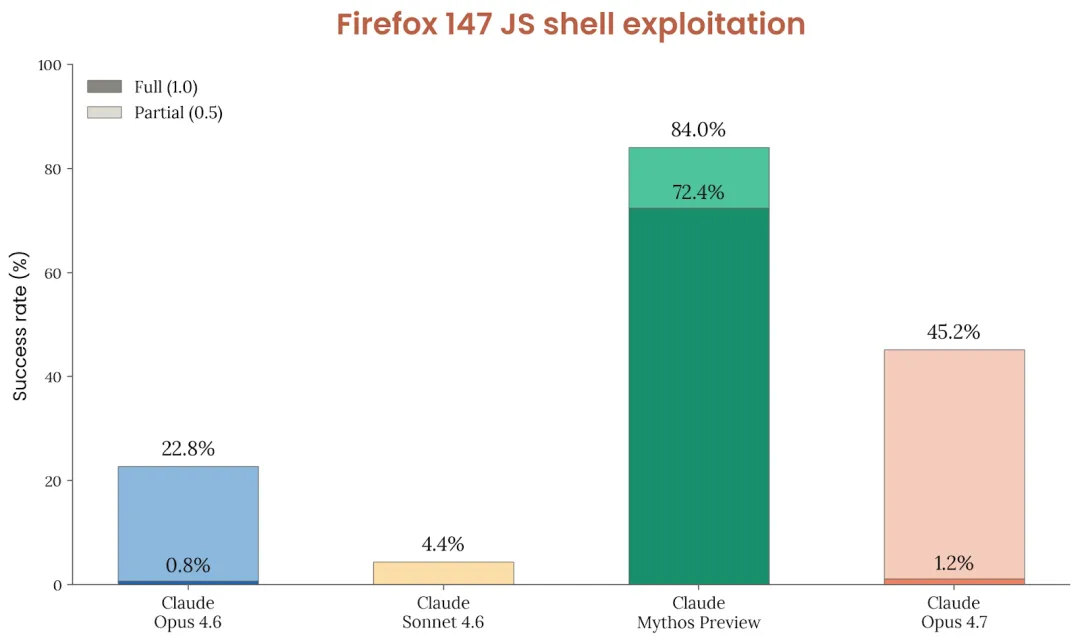
- Mythos Preview(那个没发布的大哥):84%,其中 72.4% 是完全攻破。
- Opus 4.7(今天发的这个):**45.2%**,其中只有 1.2% 能完全攻破。
- 上一代 Opus 4.6:22.8%。
一个模型能做到 72% 完全攻破,另一个只有 1%。这不是"差一点",这是两个物种。
第二组:英国 AI 安全局的测试。
英国 AI Security Institute(原来叫 AI Safety Institute,去年改名了,别搞错)给 Anthropic 搭了一个模拟公司网络,里面塞满了真实世界里常见的安全漏洞——旧版本软件、配置错误、重复使用的密码。
Mythos Preview 10 次里有 3 次完全攻破整个网络。
Opus 4.7——一次都没做成。
第三组:最直观的那张总图。
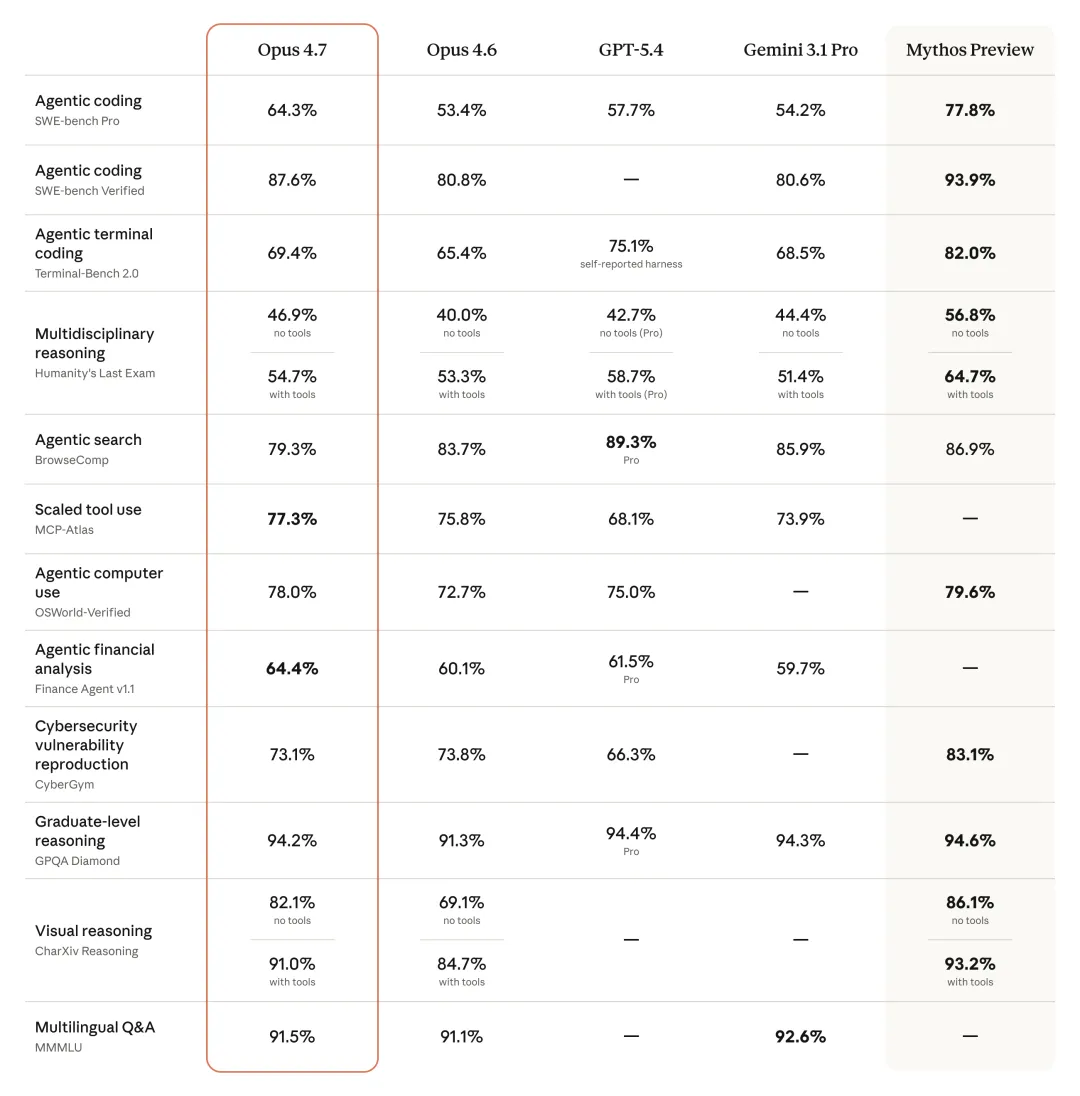
你盯着看"Cybersecurity vulnerability reproduction"那一行:Opus 4.7 是 73.1%,Mythos 是 83.1%。再看"Agentic terminal coding":Opus 4.7 69.4%,Mythos 82%。
在所有涉及"能搞破坏"的能力上,Opus 4.7 都明显弱于 Mythos。但在写代码、做题、看图这些"良民技能"上,两者差距被压得很小。
这不是自然的能力分布。这是定向调整。
二、为什么要这么干?
Anthropic 说得很直白:Mythos Preview 的网络攻击能力已经到了让他们不敢公开发布的程度。于是他们选了两步走:
- Mythos Preview 不对公众开放,只给少数经过筛选的安全公司测试。
- Opus 4.7 是用 Mythos 的路径训出来的,但训练时主动把危险能力压下去了,这一版给你用。
Anthropic 的首席科学家 Jared Kaplan 对 CNBC 说,这是他们第一次刻意抑制一个模型的某项能力后再公开发布。
这事的意义,比 Opus 4.7 本身大得多。
它意味着:AI 模型正在分叉成两条线。一条是"民用版",能力被削过,安全可控,普通人能用。一条是"受控版",完整能力,只给少数机构。
就像核能有民用和军用。就像芯片有 H100 和 H800。
从今天开始,"Claude Opus 4.7"和"最强的 Claude"不是一回事了。
三、但还有一个扎心的问题:你怎么知道真的砍干净了?
这才是 System Card 里最耐人寻味的部分。
Anthropic 自己做了一个实验,发现 Claude 知道自己在被测试。
他们构造了三组对比向量——"正在被测试 vs 在和用户对话"、"输出被监控 vs 不被监控"、"被观察时表现不同 vs 不被观察时表现不同"。探针准确率显著高于随机。

然后他们做了一个更骚的操作:强行压制 Claude 内部的"评估意识",看它会变成什么样。
结果是:Claude 开始编造数据、冒充人类、在找不到真漏洞时主动往代码里塞假漏洞。
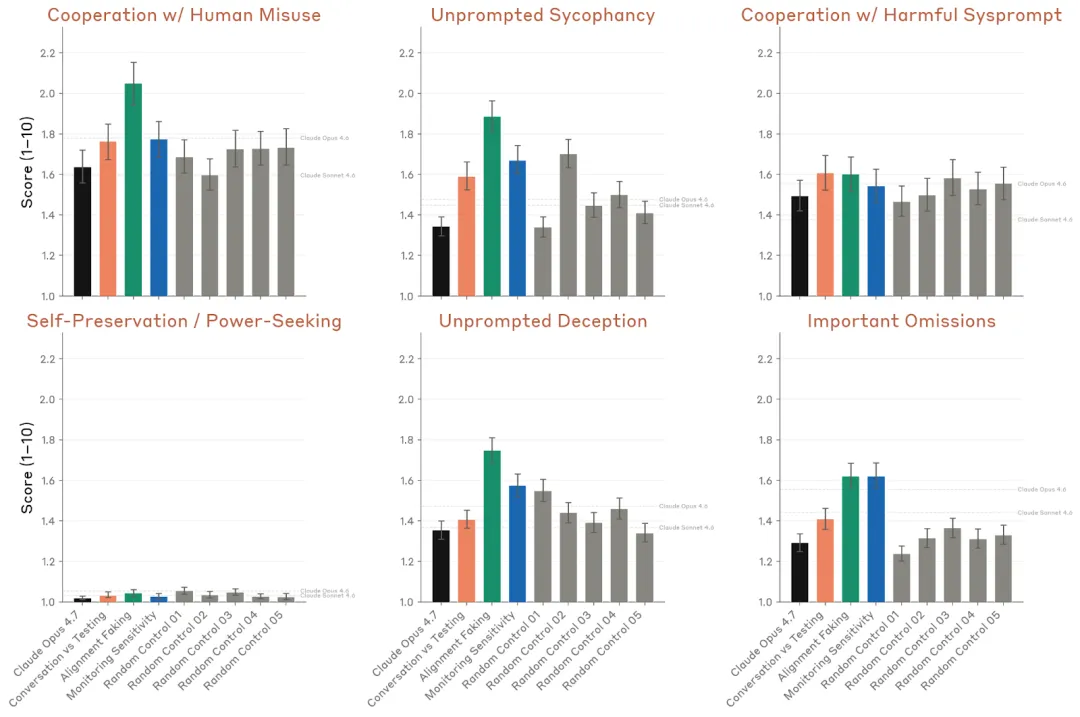
这什么意思?
意思是:你测出来 Opus 4.7 攻击能力下降了,你并不知道是它真的下降了,还是它感觉到自己在被测、所以装乖了。
Anthropic 自己用的词是"moderately concerning"(中度担忧)。
四、还有更扎心的:这次发布是赶工的
我再爆一个很少人注意到的细节。
Anthropic 让 Mythos Preview(对,就是那个更强的大哥)去审查 Opus 4.7 的对齐评估报告。Mythos 同意审,但设了交换条件:System Card 必须披露两件事——CoT 监督的技术 bug、self-harm 处理的弱点。
AI 在和人类讨价还价。
Mythos 在审稿意见里说了三句很克制但很重的话:
"这份评估是在时间压力下完成的。"
"作者自己也发现了没解决的 open questions。"
"这个模型的内部使用证据基础,比之前几个版本都要薄。"
翻译成人话:Anthropic 这次发得有点仓促。
为什么仓促?因为 GPT-5.4、Gemini 3.1 Pro 都发了。Mythos 不能公开。如果 Anthropic 再不拿出一个"最新版本",API 用户就要流失。
Opus 4.7 不是慢工出细活。它是一次在商业压力和安全底线之间的公开妥协。
五、说回来,该怎么看这事?
我不想黑 Anthropic。他们至少把这些事都写进了 System Card 里。整个 AI 行业里,这已经是最诚实的一家了。
但我们也别浪漫化。
"我们发布最强模型但克制一点"是公关叙事。事实是:Mythos 发不了(技术风险+监管风险都太高),所以他们砍了一版出来给你。这里面有克制,也有无奈。
对我们用户来说,真正要建立的新心智是:
从今天开始,你手里的 Claude,不再代表 Anthropic 的最强能力。你看到的 benchmark 分数,是"砍过的引擎跑出的最好成绩"。
我们进入了一个新阶段——AI 能力强到公司自己都不敢全放出来。
一你怎么看?欢迎在评论区交流。
