 夜雨聆风
夜雨聆风本篇讲解 OpenClaw 的记忆系统。没有记忆的 Agent 只能记住当前会话的上下文——一旦会话结束,之前的交互信息全部丢失。记忆系统通过持久化存储和语义检索,让 Agent 拥有跨会话的长期记忆能力。
01
—
记忆系统架构
OpenClaw 的记忆系统由四个相互配合的组件构成。在进入细节之前,先理解它们各自的分工——如果你只需要改变记忆的「展示方式」,只需替换第一个组件;如果你想换一个向量数据库,只需替换Embedding Provider组件。这种分离设计让记忆系统的各个部分可以独立定制:
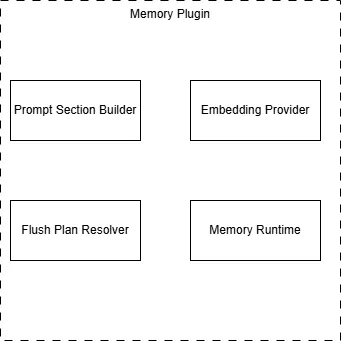
这四个组件通过四个注册方法暴露给插件开发者——这些方法都在 register(api) 回调中通过 api 对象调用:
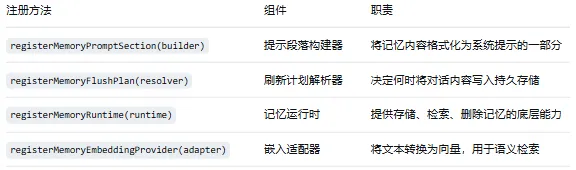
—
独占插槽
与上下文引擎一样,记忆系统采用独占插槽机制:{"plugins": {"slots": {"memory": "memory-lancedb"}}}
系统提供两个内置的记忆插件:

也可以设为 "none" 禁用记忆系统。
切换后需要重启 Gateway:
openclaw gateway restart03
—
记忆的工作流程
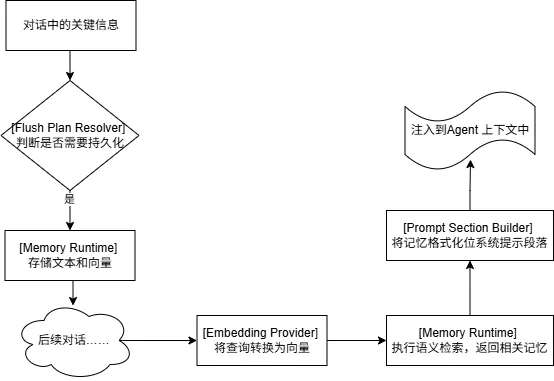
04
—
组件详解
1. Memory Prompt Section Builder
记忆被检索出来后,需要以某种格式插入到 Agent 的系统提示中。registerMemoryPromptSection 定义了这个格式——它决定了 Agent 「看到」的记忆长什么样。
这个组件最容易定制。即使你使用内置的记忆存储(memory-lancedb),也可以只替换这个组件来改变记忆的展示风格:
api.registerMemoryPromptSection({// 构建记忆提示段落async build(memoryResults, context) {if (!memoryResults.length) return null;const sections = memoryResults.map((result, index) => {return `[记忆 ${index + 1}] (${result.metadata.source})\n${result.content}`;});return ["以下是用户的相关历史记忆:","",...sections,"","请在回复中自然地利用这些记忆信息,不要直接提及「记忆」这个词。",].join("\n");},// 提示段落的优先级(用于上下文引擎排序)priority: 75,});
build 方法返回 null 时表示不需要注入任何记忆内容(如没有相关记忆被检索到)。
2. Memory Flush Plan Resolver
不是对话中的每一句话都需要持久化。registerMemoryFlushPlan 决定「哪些内容值得记住」——它是记忆写入的「守门人」。只有当 shouldFlush 返回 { flush: true } 时,内容才会被写入存储:
api.registerMemoryFlushPlan({async shouldFlush(context) {const { message, history } = context;// 规则 1:用户明确说了「记住」if(/记住|记得|以后.*记得|帮我记/i.test(message.text)) {return {flush: true,content: extractMemoryContent(message.text),metadata: {source: "explicit",timestamp: Date.now(),},};}// 规则 2:包含偏好或个人信息if(isPreferenceOrPersonalInfo(message.text)) {return {flush: true,content: message.text,metadata: {source: "preference",timestamp: Date.now(),},};}// 规则 3:累积了一定量的对话后,提取关键信息if(history.length > 10) {return {flush: true,content: summarizeHistory(history),metadata: {source: "auto-summary",timestamp: Date.now(),},};}return { flush: false };},});
shouldFlush 的返回值:

3. Memory Runtime
Memory Runtime 是记忆系统的存储引擎,负责实际的读写操作。它是四个组件中最「底层」的一个——直接与数据库交互:
api.registerMemoryRuntime({// 存储一条记忆async store(entry) {// entry 包含 content、embedding、metadataawait myVectorDB.insert({id: generateId(),content: entry.content,embedding: entry.embedding,metadata: entry.metadata,});},// 语义检索async search(query, options) {// query 是查询文本// options 包含 limit、threshold 等参数const queryEmbedding = await getEmbedding(query);const results = await myVectorDB.search({vector: queryEmbedding,topK: options.limit ?? 5,threshold: options.threshold ?? 0.7,});return results.map(r => ({content: r.payload.content,score: r.score,metadata: r.payload.metadata,}));},// 删除记忆async delete(filter) {await myVectorDB.delete(filter);},// 更新记忆async update(id, updates) {await myVectorDB.update(id, updates);},});
Memory Runtime 不直接处理向量化——它接收已经生成好的 embedding。向量化由 Embedding Provider 负责。
4. Memory Embedding Provider
Embedding Provider 将文本转换为向量(高维数字数组),是语义检索的基础。所谓「语义检索」,就是根据含义而不是关键词来搜索——即使搜索词和记忆内容用词不同,只要含义相近就能匹配上。
例如,用户之前说过「我喜欢 Python」,现在问「我最擅长什么语言」,通过向量相似度也能匹配上。
api.registerMemoryEmbeddingProvider({id: "my-embedding",async embed(texts) {// texts 是字符串数组// 返回对应的向量数组const response = await fetch("https://api.example.com/embed", {method: "POST",headers: { "Authorization": `Bearer ${apiKey}` },body: JSON.stringify({ texts }),});const data = await response.json();return data.embeddings; // number[][]},});
一个记忆插件可以注册多个 Embedding Provider 适配器。这样做的好处是:你可以同时注册 OpenAI 的 embedding 和本地模型的 embedding,用户在配置中选择使用哪个,甚至设置回退策略(第一个不可用时自动切换到第二个):
// 注册多个 embedding 适配器api.registerMemoryEmbeddingProvider({id: "openai", // 适配器 ID: "openai"async embed(texts) { /* ... */ },});api.registerMemoryEmbeddingProvider({id: "gemini", // 适配器 ID: "gemini"async embed(texts) { /* ... */ },});api.registerMemoryEmbeddingProvider({id: "custom-local", // 自定义适配器 IDasync embed(texts) { /* ... */ },});
用户通过配置选择使用哪个适配器:
{"agents": {"defaults": {"memorySearch": {"provider": "openai","fallback": "gemini"}}}}
provider:首选的 embedding 适配器 IDfallback:首选不可用时的回退适配器 ID
用户配置中引用的 ID 必须与插件注册的 ID 匹配。如果引用了不存在的 ID,系统会报错。
05
—
记忆系统的配置
完整的记忆系统配置示例:
{"plugins": {"slots": {"memory": "memory-lancedb"}},"agents": {"defaults": {"memorySearch": {"provider": "openai","fallback": "gemini","topK": 5,"threshold": 0.7}}}}
06
—
记忆与上下文引擎的协作
记忆系统是上下文引擎的「数据提供方」:
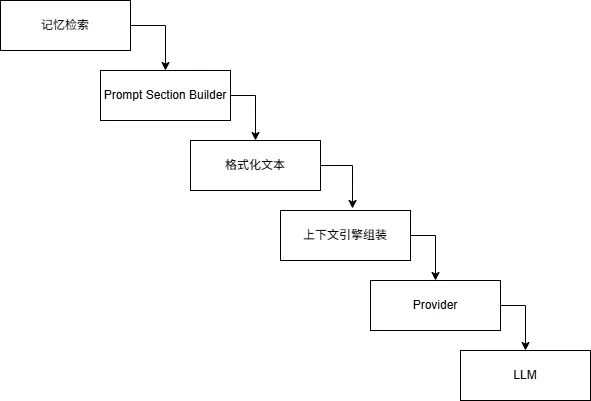
上下文引擎在构建上下文时,会调用记忆系统的检索能力,获取相关记忆,然后通过 Prompt Section Builder 将其格式化为系统提示的一部分。
这就是为什么记忆系统的四个注册方法都是独立的——你可以只替换 Prompt Section Builder(改变记忆的展示方式),而不影响底层存储;也可以只替换 Embedding Provider(改变向量化模型),而不影响存储和展示。
07
—
实战:自定义记忆格式化插件
import { definePluginEntry } from "openclaw/plugin-sdk/plugin-entry";export default definePluginEntry({id: "structured-memory-formatter",name: "Structured Memory Formatter",version: "1.0.0",register(api) {api.registerMemoryPromptSection({async build(memoryResults, context) {if (!memoryResults.length) return null;// 按来源分组const bySource = new Map<string, typeof memoryResults>();for (const result of memoryResults) {const source = result.metadata.source ?? "general";if (!bySource.has(source)) bySource.set(source, []);bySource.get(source)!.push(result);}const lines: string[] = ["## 用户背景信息"];for (const [source, results] of bySource) {const sourceLabels: Record<string, string> = {explicit: "用户明确要求记住的",preference: "用户偏好","auto-summary": "历史对话摘要",general: "其他相关信息",};lines.push(`\n### ${sourceLabels[source] ?? source}`);for (const r of results) {const confidence = Math.round(r.score * 100);lines.push(`- ${r.content} (相关度: ${confidence}%)`);}}lines.push("\n请自然地利用以上信息,不要直接提及「记忆」。");return lines.join("\n");},priority: 75,});},});
08
—
小结
本篇覆盖了 OpenClaw 记忆系统的完整架构:
四个组件:Prompt Section Builder、Flush Plan Resolver、Memory Runtime、Embedding Provider
独占插槽机制,同一时间只有一个记忆插件活跃
memory-core(基础)vsmemory-lancedb(增强)两个内置选项记忆的工作流程:产生 → 判断 → 向量化 → 存储 → 检索 → 格式化 → 注入
Embedding Provider 支持多适配器注册和回退配置
下一篇:运行时 API — 深入 api.runtime。我们将学习插件运行时可用的辅助能力:存储、配置、审批、HTTP 请求等。
