 夜雨聆风
夜雨聆风作者:松皓(毛宇),蚂蚁集团-智能数据研发平台负责人
备注:本文AI含量为 0,古法写作,全部基于落地过程中遇到的实际问题进行总结提炼。
Dataphin是蚂蚁集团内部集研发、消费、治理三位一体的数据研发平台,目的是使数据的研发更高效、消费更便捷、治理更简单。同时,它也提供了端到端的、可自主推理和规划的各种DataAgent解决方案。
一、背景
随着OpenClaw 以及相关能力的逐步普及,大家希望在一个终端里串联并完成所有工作的诉求日益强烈。而首当其冲的,就是需要各种平台将其能力MCP化/CLI化。甚至可以说,平台MCP/CLI的好坏,直觉决定了OpenClaw或者ClaudeCode(后文简称CC)在企业内部到底能发挥出多大的威力。

从Dataphin-MCP上线的第一天,就遇到非常多的问题,有些问题是可以优化的个例(比如ODPS的dryrun语法检测对DDL语句会在dev项目建表,这不是用户预期的,就倒逼我们用工程手段去优化),有些问题则直接和平台过去多年的一些概念体系产生冲突。在不断解决问题和迭代升级的过程中,本文总结了如下的5条“白银”法则,并配合具体的案例来呈现。
 2.1 不仅是用户动线,还有大模型动线
2.1 不仅是用户动线,还有大模型动线
在平台时代,产品设计中最经常挂在嘴边的就是用户动线,需要考虑用户会如何一步一步的去操作,进而设计对应的产品能力来承载用户的动作。到了Agent时代,我们不仅要考虑用户,还需要去站在大模型的视角去思考大模型可能会如何一步一步的去操作,基于大模型动线,我们再去设计对应的MCP工具。
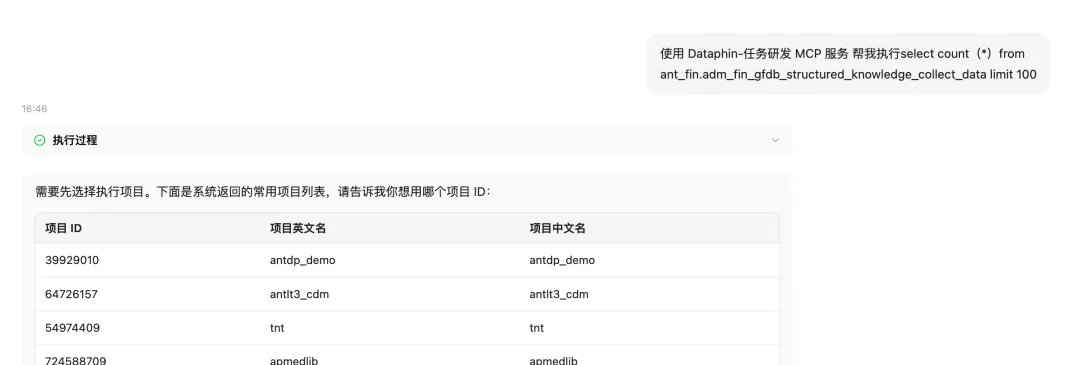
这里举一个Dataphin-MCP实际案例:模型编造项目ID。


执行项目这个信息在传统平台时代其实是在产品的左上角,用户调整它的频率很低,这是For Human的。而到了CC里,除非你显性告诉模型 “帮我用ID=xxxxx这个项目去跑下xxxx这段SQL”,否则,模型根本不知道该用哪个项目去构造工具调用。但是我们的设计不可能让用户每次都多打这么多字告诉模型,而且用户也记不住这个ID。
于是,需要重新规划动线,在不确定执行项目ID时,不应该让模型随意猜测和编造,而是应该让工具返回用户的常用执行项目列表,然后用户选一个执行项目告诉模型,这样就可以妥善解决模型瞎猜造成的报错和没权限问题。
 2.2 概念体系设计,重要性只增不减
2.2 概念体系设计,重要性只增不减
在平台时代,无论是系统级的升级迭代,还是复杂模块需求,我们都需要做概念系统设计和详细方案设计。在概念系统设计中,有很重要的一趴就是领域模型设计,也叫领域建模。而建模是有严格的前置条件的,需要基于User Story来推导领域模型。到了Agent时代,大模型可以轻松的产出Spec甚至产出Code,是不是概念系统设计就不重要了?恰恰相反,概念系统设计反而更加重要的。概念系统直接影响MCP工具的设计,甚至直接影响Agent的效果。
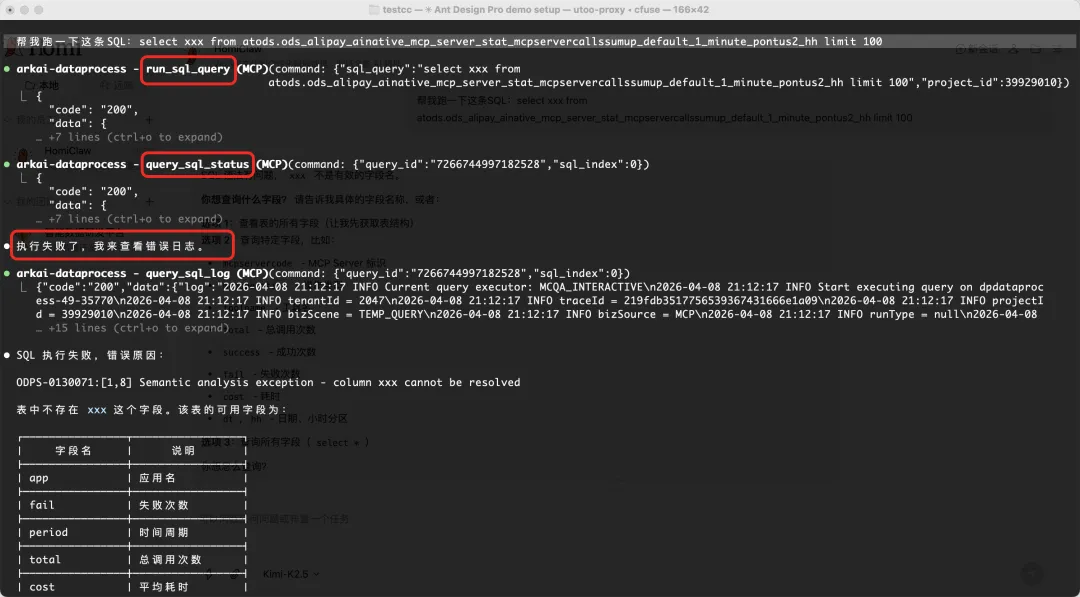
这里举一个Dataphin-MCP实际案例:模型混淆文件ID、任务ID、实例ID、节点ID,导致工具串联调用失效。
在Dataphin原来的概念系统设计中,在研发态的唯一ID是文件ID,在运维态的唯一ID叫任务ID,在运行时的唯一ID是实例ID,在DAG调度大图叫节点ID。于是,如果咱们只是简单的包一下API做成MCP时问题就来了。如下图所示,第一张图是工具A返回了节点ID,然后模型拿着节点ID调用另外一个工具B读取发布态的SQL代码,就把节点ID传给了工具B。而工具B实际需要的是文件ID。于是,最终的结果就是找不到结果。


总结来说:大模型虽然可以高效帮我们产出方案、产出系分、产出Spec文档,但是文档质量的高低、概念的精准与否,还是需要人进来把控的。
 2.3 写操作,谨慎谨慎再谨慎
2.3 写操作,谨慎谨慎再谨慎
在平台时代,已经具备了一套严谨的多层权限管理体系 + UI的提醒设计,它可以妥善的解决因用户误操作而引发的灾难性问题。到了Agent时代,这套体系和机制是什么样子还不确定,但可以确定的是,目前的模型还是挺容易出现幻觉导致很大的风险的,写操作的MCP化需要严谨的评估,尤其是数据领域。它和办公领域的不一样之处在于,办公领域写操作错误,最多只影响这份文档本身,但数据领域一旦写操作错误,它会影响到调度大图上所有的下游节点甚至影响到末端的看板和API服务,且很难排查和修复。
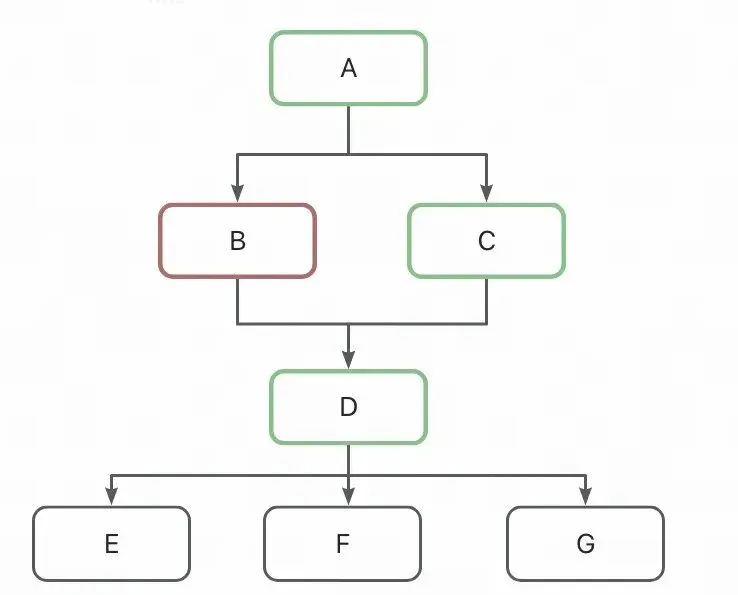
这里举一个Dataphin-MCP实际案例:提交周期任务补数据的MCP工具风险分析。
提交周期任务补数据(submitFlowInstances)工具需要传入本节点ID和下游节点ID集合。以下图的DAG图为例,本节点ID应该传A,下游节点ID集合应该传BCD。但如果下游节点ID列表因为模型幻觉传错了,只传递了CD,漏传了B,就会造成一个结果:虽然 D 跑成功了,但数据是错的,且难以被发现(任务都显示成功,但逻辑错误)。这里的逻辑错误体现在 D 的数据一部分新、一部分旧。
D 中来自 C 的分支:基于 A 的新数据(正确) D 中来自 B 的分支:基于 A 的旧数据(错误,因为 B 被模型传漏了)
对应的解法,其实不是单点突破,而是一套体系化的方案。最简单的,在工具描述上增加声明,要求模型或Agent必须获取人工二次确认才执行。稍微复杂一些的,能在工具内部完成基于血缘的影响面评估并返回具体风险给用户。进一步的,要能可控执行(这里可能需要自建Harness才行)。更进一步的,要建设数据领域的版本管理和高效回滚机制。
总结来说:Giving AI access to your system is Easy。Deciding what is not allowed to touch is the Hard part。
 2.4 报错Error,精心设计返回结果
2.4 报错Error,精心设计返回结果
在平台时代,因为有UI界面,很多功能出错以后就吐一个URL出来,然后人可以通过各种各样的URL跳转到各个地方去看错误详情,进而判断发生了什么以及怎么解决。到处跳转看报错这个问题虽然是一个很繁琐的问题,也有各种“一站式xxx”项目尝试解决这个问题,但人终究还是可以勉强凑合用着。到了Agent时代,这个问题终于盖不住了。如果系统出错后还是简答吐一个链接,那么模型将会迷茫,它不知道下一步该干嘛。
这里举一个Dataphin-MCP实际案例:SQL运行后应该怎么吐信息。
传统平台里,提交SQL以后,会有一个控制台不断的展示SQL运行的过程,其中有一个信息叫logview,这个过程对Human是清晰的透明的,人可以基于需要自己决定要不要点击logview进去看看发生了啥。但如果原样搬运到Agent这里,甚至只是跑,不给任何信息回来,那Agent就不知道下一步该做啥,就会开始自己瞎猜。如下图所示,要么不给返回信息,要么就给一个错误码。
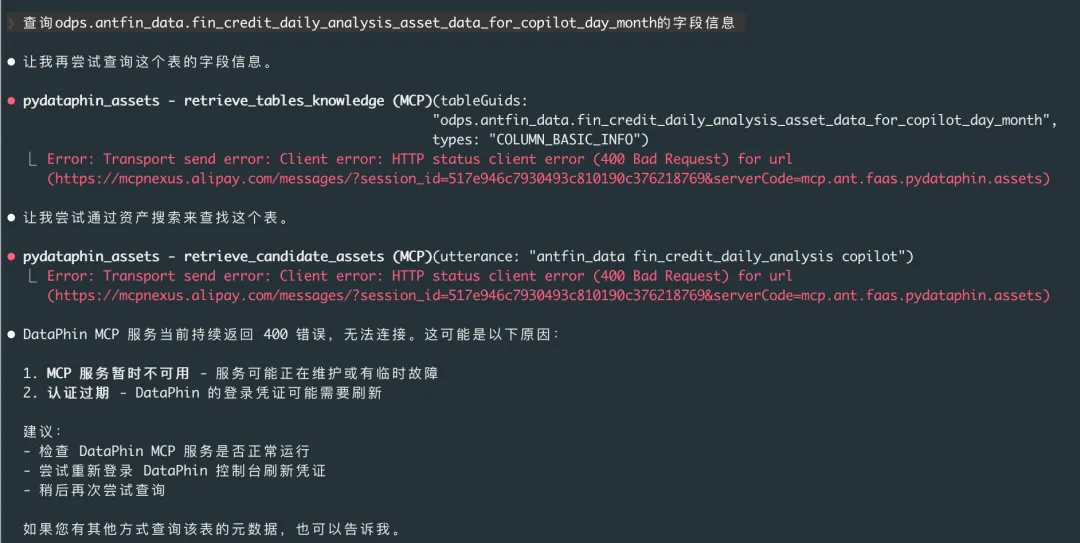
合理的SQL运行工具设计,在出错时,不仅仅是透传logview ,而是解析并给出明确的错误信息,Agent才能正确往下走。
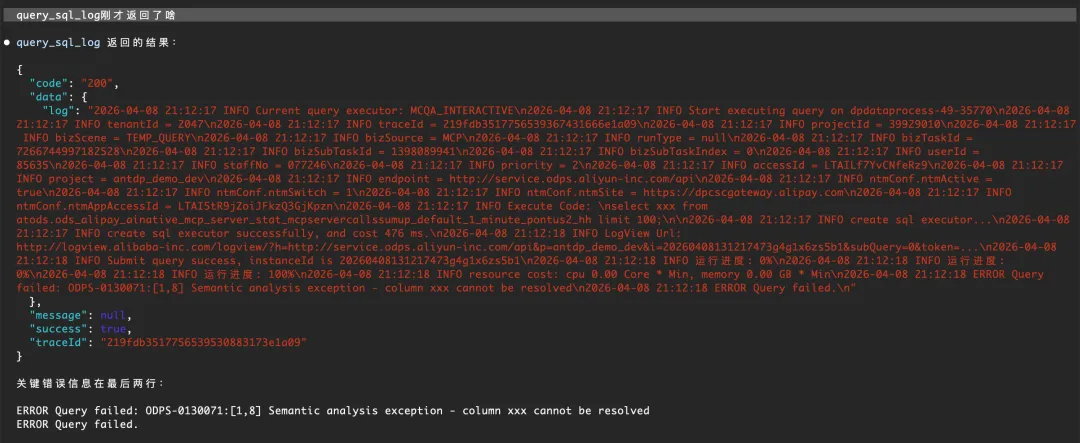
总结来说:要精心设计返回结果以便于引导模型采取正确行动。
 2.5 上下文窗口管理,尽可能抠一些
2.5 上下文窗口管理,尽可能抠一些
在平台时代,都是Build For Human的,没有上下文窗口一说。到了Agent时代,Context Window成为非常重要的考量因素,如何在有限的窗口里放入最恰当最合适的内容成为影响Agent效果的重要手段之一,这也被称之为上下文管理。
这里举一个Dataphin-MCP的实际案例:SQL返回结果过大直接撑爆窗口。
在实际使用中发现,一般模型会默认采样100条数据,假设这个表是一个100列的宽表,那么返回结果会占用60%上下文。这对上下文的消耗是非常大的,可能跑几轮就会触发上下文压缩。除了SQL结果,往往一个用户也会安装多个MCP(语雀、Dima、Dataphin、Deepinsight等),如果这些MCP全部安装,本身也会占据大约20%的上下文。但实际上,当工具安装超过30个,效果就会受到影响。下图是我个人在某个使用瞬间的上下文快照。可以发现其中上下文消耗大户正是上面提到的两类。
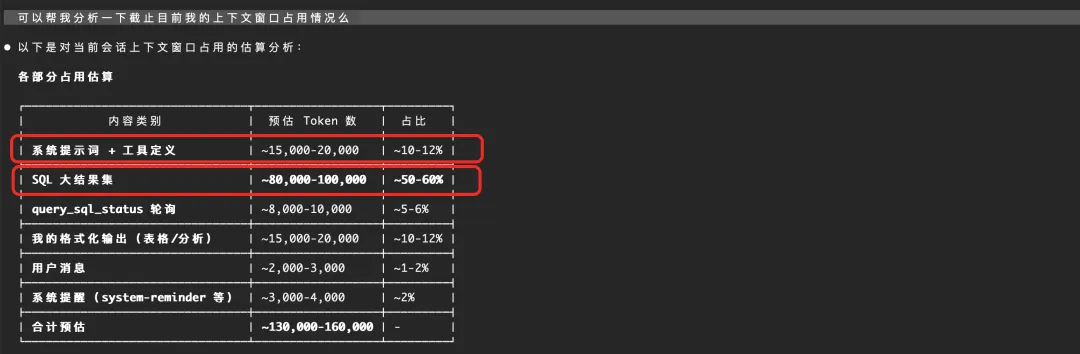
数据领域非常依赖精准的上下文,对应的解法其实也还是体系化解法。包括但不限于用工程手段将结果持久化到存储系统里供模型后续自己按需使用,或者用SubAgent手段去取结果以保证主Agent可以持续正常运行等。当然,也包括提供 CLI 工具集再配合管道命令(如获取信息后用 grep 提取再输入模型),相比直接调用 mcp 返回全部结果,能减少 token 量并提升效果。
前面总结了Build For AI要考虑的5条“白银”法则。但实际上,想要更好的Build For AI,还有很多值得探索和优化的地方,现在行业也还没有一个明确的东西出来,这里斗胆基于一手经验说一下我们的见解。
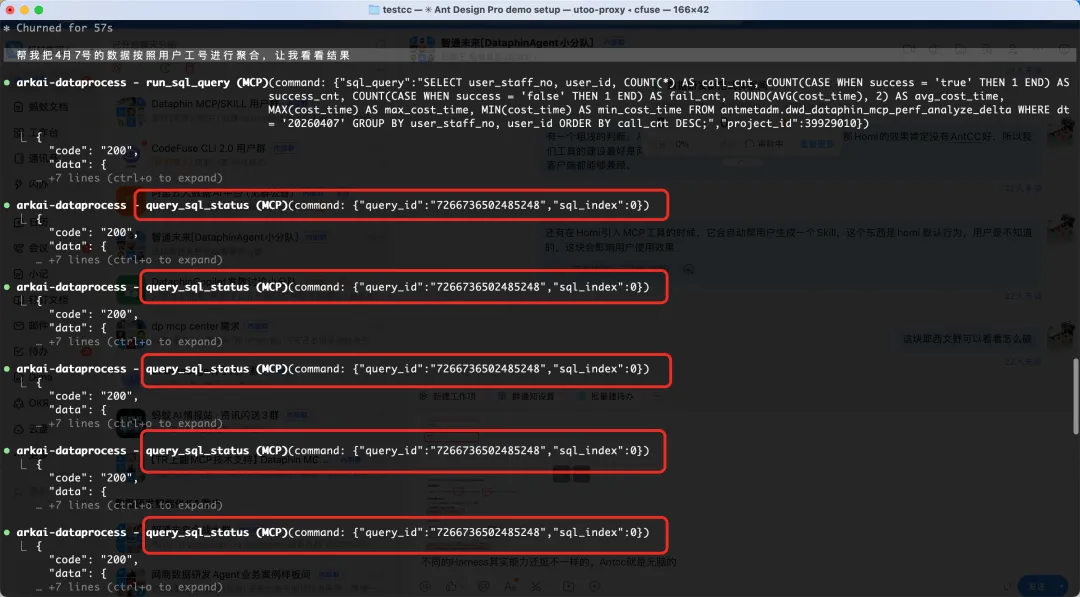
再比如,相同的都是轮询行为,有的可以做递增的sleep管控,是为了避免轮询过快给服务器增加压力,而有点则是无脑一直轮训直到拿到结果。
所以,说明如果把Harness比作底盘,把模型比作发动机,那么10种底盘和10种发动机就可以搭出100种情况,而具体哪一种搭配是最有利于某个垂直领域效果的,还不好说。因此MCP/CLI在设计时需要兼顾各种情况,以保证即便在最坏的情况下,它依旧能够稳定的输出,即保住下限。
第三层:长远看,考虑到模型一定有幻觉,外部通用的Harness其行为不在我们可控范围内(靠工具的Prompt来影响模型下一步行为其实也有概率犯错)。对于高标准严要求的场景,好的效果和稳定的执行大概率来自有针对性的Harness设计。Build for AI的长期结果很有可能是既要做MCP/CLI,也要做Agent/Harness。
▼
往期精彩回顾▼




