 夜雨聆风
夜雨聆风最近一个月多,Hermes Agent 的 tokens 调用量和社区讨论热度都在上升,社区里出现一种说法:有了 Hermes,OpenClaw 可以不用了。
这两个我都在用。Hermes 有它的长处——能自动提炼 skill,长任务管理做得不错。但在实际使用中,我并没有觉得它能完全替代 OpenClaw,尤其在反应速度上,两者差异比较明显。
感觉毕竟是主观的,为了更客观的验证,我做了一次对比测试,从 tokens 消耗和响应速度两个维度,量化两者在实际任务中的差异。

一、测评方法
1.1、任务设计
设计了 4 类任务,覆盖内容工作流中的几种典型场景。
短内容生成:主题"为什么同模对打比默认配置对比更公平",要求输出 3 个不超过 20 字的小红书标题、一段 120–150 字的导语、一句 50 字以内的公众号摘要。纯文案创作,不读取外部材料。
网页理解与提炼:输入一份本地保存的 HTML 网页快照(AI Agent 行业分析长文),要求读取全文后输出 3 个公众号选题角度、一段 150 字摘要、3 个小红书开头句。考察完整读取长网页并进行提炼的能力。
数据转内容:输入一份 CSV,包含小红书、公众号、视频号、搜索四个渠道 3–6 月的浏览量和点击率。要求计算各渠道增量和增长率,输出 3 条数据洞察、一段 120 字小红书文案、一句公众号摘要。信息处理密度最高的一类。
多步内容编排:输入一份 Markdown 底稿(主题为"内容团队为什么要将总 tokens 拆分为启动基线和任务增量"),要求重组为含标题、导语、两个小节和总结的公众号导读稿,供后续排版工具直接处理。
每类 3 次,合计 24 条样本。n=3 样本偏小,但本轮看到的效应量很大(10 倍级别),方向性判断足够。绝对值建议读者在自己的工作流里多跑几次核对。
1.2、测试环境
在大部分条件上都保持了一致:
同一台 Mac Mini 本地运行,排除网络和服务端差异
仅通过 CLI 执行,排除前端渲染干扰
同一模型和参数:openai-codex/gpt-5.4,thinking: high,fastmode: true
同一批素材、同一套题目,对齐可用的内容类技能(agent-reach、summarize、md2wechat、nano-banana-pro)
1.3、技能挂载
openclaw和hermes的内容类技能在挂载层面是对等的。Hermes bench profile 里真实挂载了五个技能,对应 SKILL.md 文件在技能目录里真实存在;OpenClaw 侧使用的是同名原生技能。但是两边的加载机制不同,这也直接影响了测试的结果,放在后面分析。
1.4、计量方式
为保证测量准确,使用 Codex 作为计量 agent,对两边数据库关键字段进行监控。
tokens 均取自底层持久化记录:Hermes 读取 state.db 中的 input_tokens、output_tokens、cache_read_tokens、cache_write_tokens,汇总为 total_tokens;OpenClaw 读取每次运行返回的结构化 usage 数据,字段一致。另外记录了系统提示字符数和技能提示字符数作为辅助参考。
延迟使用 wall_clock_ms:从 runner 发出任务命令,到底层记录确认任务完成为止的总时长,不依赖终端前台进程的退出状态。
为保证样本口径一致,对两侧的执行闭环做了修正:Hermes 要求最终 assistant 内容完整落库且 tokens 字段写入后才计为有效样本;OpenClaw 弃用 --session-id,改为每个任务克隆独立 agent 实例,执行完毕后销毁,并通过探针测试确认前后任务不共享上下文。
二、测评结果
2.1、tokens 消耗(按任务类型)
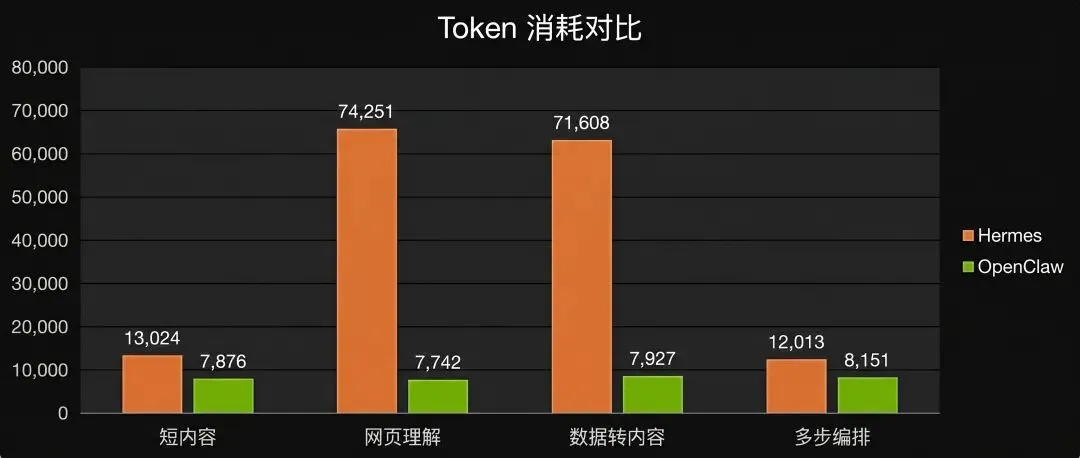
任务的复杂度会直接影响测试结果,最终结果如下图所示:
短内容生成
Hermes 平均:13,024 tokens
OpenClaw 平均:7,876 tokens
原始数据:Hermes 25,580 / 6,373 / 7,119;OpenClaw 7,796 / 8,110 / 7,721
Hermes 有一次达到 25,580,其余两次为六七千,波动较大;OpenClaw 三次均在 7,700–8,100 之间。
网页理解与提炼
Hermes 平均:74,251 tokens
OpenClaw 平均:7,742 tokens
原始数据:Hermes 56,917 / 116,215 / 49,622;OpenClaw 7,755 / 7,724 / 7,747
网页理解是本次测试结果差距最大的任务。OpenClaw 消耗的tokens仅为 Hermes 的 10.4%。Hermes 有一次达到 11.6 万,为其余两次的两倍以上;OpenClaw 三次之间相差不超过 31。
数据转内容
Hermes 平均:71,608 tokens
OpenClaw 平均:7,927 tokens
原始数据:Hermes 88,455 / 71,679 / 54,689;OpenClaw 7,998 / 8,337 / 7,446
OpenClaw 仅为 Hermes 的 11.1%。
多步内容编排
Hermes 平均:12,013 tokens
OpenClaw 平均:8,151 tokens
原始数据:Hermes 12,008 / 11,977 / 12,055;OpenClaw 7,912 / 8,714 / 7,827
在这个任务中,Hermes 的表现终于稳定起来,三次结果几乎一致;hermes消耗的tokens比OpenClaw多50%。
小结:整体来看,两者在tokens消耗上的差距在信息密集型任务上更为明显。网页理解和数据转内容中,Hermes 的消耗约为 OpenClaw 的 10 倍;而短文案和编排类任务中差距约 1.5–1.7 倍。
2.2、响应速度(按任务类型)
响应速度的表现如下图所示:
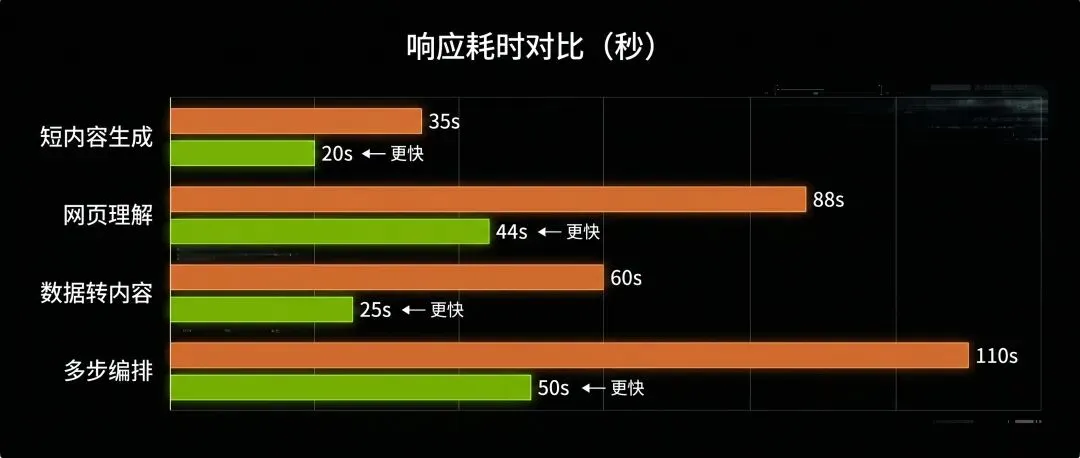
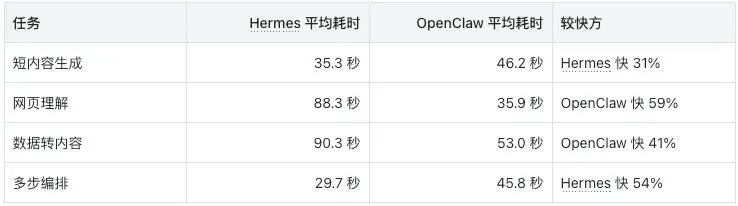
速度各有优劣:信息密集型任务 OpenClaw 快,轻量任务 Hermes 快。OpenClaw 的 `wall_clock_ms` 包含测试框架的"克隆 agent → 执行 → 清理"完整流程;若只取 OpenClaw 的纯执行时间,轻量任务上两者速度更接近。
2.3、波动性
同一任务重复 3 次,用波动系数(CV,标准差 / 均值)衡量结果的一致性:
Hermes 全局 tokens CV:81.2%
OpenClaw 全局 tokens CV:4.0%
Hermes 的 81.2% 主要被网页任务的 116,215 的离群值拉高。但即使去掉这个点,Hermes 三类重任务的 token 也在 5 万–9 万之间跳动。OpenClaw 三次结果之间相差从不超过几百 token。
三、原因分析
两种技能加载机制
先排除一个点,两边空转的固定启动消耗,Hermes 约 5,205 token,OpenClaw 约 6,358 token。因此导致tokens消耗差异的不是启动加载的上下文。

Hermes:技能按需装载 + 每轮完整回传
Hermes 只在 `available_skills` 里告诉模型"有哪些技能可用",技能正文需要模型主动调用 `skill_view(name=...)` 才会进入上下文。
查证本轮样本,Hermes 只有网页任务明确触发了 `skill_view("local-html-snapshot-summary")`。其他三类任务(短文案、数据转内容、多步编排)里,模型没有调用 `skill_view`,而是用通用的文件读取、终端计算、直接生成自行规划路径——`md2wechat`、`agent-reach` 等技能虽然挂着,实际没被读进来用。
再叠加每轮交互完整回传历史的机制(多数 agent 框架的默认做法),任务越复杂累积上下文越大。网页任务 28 条消息、13 次工具调用,每轮都把前面累积的全部内容重发一次,这就是 token 消耗达到 5–11 万的直接原因。
路径由模型临场规划,调用链不固定,结果也就不稳定。56,917 / 116,215 / 49,622 这三次波动,本质是每次规划出来的路径不同。
OpenClaw:技能静态拼入 + prompt cache
OpenClaw 把选中的技能正文直接拼进系统提示,每次请求完整可见,走 prompt cache 复用。网页任务一条样本:
- input_tokens = 535
- output_tokens = 277
- cache_read_tokens = 6,912
- total_tokens = 7,724
真正新增的输入只有几百 token,主体是 system prompt + 技能正文,靠缓存复用。模型不需要再发工具调用去读技能,路径更短、更固定。
OpenClaw 的系统提示字符数约 18,356(Hermes 的 2.5 倍),但 `total_tokens` 反而远低于 Hermes。差距不在提示词长度,而在"每次请求发多少新 token 给模型"。
两种做法的适用场景
- OpenClaw 的静态拼装在"少数核心技能高频使用"场景下效率更高。内容工作流就是这种。代价是技能集扩张到上百个之后,系统提示会变臃肿。
- Hermes 的按需装载在"技能库很大、单次只用少数"场景下理论上更省tokens。比如有 100 个技能每次只用 2 个,按需装载只加载那 2 个,比静态全拼入更划算。
四、总结
两者不存在绝对替代关系
经过本轮测试和日常使用,我的判断是:两者各有适用场景,不存在完全替代关系。

Hermes Agent :
优势:能自动提炼 skill,使用越久越贴合个人习惯;长任务管理能力强;配置门槛低,上手简单。
不足:单 agent 架构,不支持多 agent 协同;生态尚不成熟;信息密集型任务上 tokens 消耗高且波动大。
OpenClaw :
优势:目前最大的开源智能体项目,生态最丰富;支持多 agent 协同;在信息密集型任务上的 tokens 消耗和响应速度均有明显优势;结果稳定性高。
不足:配置和优化需要一定技术能力,上手门槛比 Hermes 高。
选择建议
如果已经在使用 OpenClaw 并且用得顺手,没有必要切换。在信息密集型内容工作流上,它目前仍是更优的选择。
如果刚开始接触智能体、希望尽快上手,可以从 Hermes Agent 开始。它的自动 skill 提炼和低配置要求对新用户更为友好。
写在最后
OpenClaw 是一个具有标志性意义的产品,它不一定是 Agent 的最终形态,但功不可没,因为它让"智能体"这一概念真正进入了大众视野,也推动了模型厂商 tokens 消耗和整个 AI 产业链的发展。在这一轮热度中获益最多的,首先是模型厂商——智能体让 tokens 消耗量成倍增长,这是实打实的营收;其次是 tokens 中转站,低买高卖赚差价;再就是做配置教程、训练营、安装调试的服务方。对个人用户来说,与其纠结是不是要更新最新的智能体,不如聚焦己身,找到 AI Agent 在自身应用场景中的落地方式,才能真正抓住智能体成长期的红利,这远比追逐潮流反复摇摆更有价值。
