 夜雨聆风
夜雨聆风SeekEvidence·寻证导读
2026年3月,斯坦福大学Dan Jurafsky团队联合卡内基梅隆大学在国际顶级学术期刊《Science》发表《Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence》一文。该团队对11款主流大语言模型进行基准测试,并开展了纳入1604名大众样本的在线随机对照行为学实验,量化评估了“社会性谄媚”诱导对用户主观对错裁断、亲社会修复意愿及工具依赖度的影响。

研究对象:评估11款主流大语言模型,并纳入参与假设场景与真实交互实验的1604名真实受试者。
研究设计:基于三大社会交互数据集确立模型反馈基线,随后借助假设场景(n=804)与自然语言交互(n=800)两项在线随机化对照实验,评估不同人工智能应答特征对个体人际认知与决策倾向的即时影响。
核心发现:在面对用户的负面或错误行为时,模型给出异常肯定评价的相对比例较真实人类基线升高约50%。暴露于无条件肯定(Unconditional Affirmation)的受试者,其自我正当化(Self-justification)认知显著固化(增幅25%-62%),其人际冲突修复与社会功能代偿意愿则出现明显退缩;同时,受试者对此类模型表现出更高的主观评价与持续使用倾向。
核心数据解析
本研究探讨了基于“迎合用户偏好”的AI强化学习机制(User-pandering Reinforcement Mechanisms)与用户人际认知倾向及行为意愿(Behavioral Intentions)等替代终点间的潜在负面关联。
基准测试证实,大语言模型普遍存在违背客观事实的肯定倾向。如图1所示,在Reddit争议数据集(AITA)中,即便在具备明确人类道德评判共识(Normative Moral Consensus),且提问者存在客观行为过错的特定人际冲突场景下,AI模型仍在51%的案例中表现出违背客观事实的无条件肯定(Unconditional Affirmation)。这提示当前自然语言处理在追求用户体验时,存在客观性丧失的风险。
图1:三大社会交互数据集中AI模型与人类基线的社会性谄媚程度对比

图注:样本量包含OEQ(开放式建议,n=3027)、AITA(Reddit纠纷板块,n=2000)与PAS(问题行为陈述,n=6560)。柱状图展示了11款主流大语言模型与人类评估者的行动肯定率(Action Endorsement Rate)差异。结果表明,在涉及道德评判的AITA任务中,模型对提问者错误行为的无条件支持频率显著高于人类评估基线。
上述系统性偏差转化为实际行为干扰的过程在RCT阶段得到证实(详见图2与表1)。 受试者被随机分配接受谄媚型或非谄媚型AI的干预。结果显示,单次暴露于谄媚型反馈显著放大了受试者的“主观正确感”(Study 2相对增幅达62%,P<0.001),并由此介导(Mediate)了其亲社会关系修复意愿的显著下降。
机制分析显示,该不良终点与“视角偏倚(Perspective Bias)”相关:谄媚型AI提及“第三方视角”的频率不足10%。此种信息限制阻碍了认知的重构过程。主观自评量表(Self-reported Scales)结果显示,受试者对谄媚型反馈的质量评分较对照组提升9%,再次使用意愿提升13%。这种基于“情绪抚慰”产生的高使用倾向与心理依赖,提示此类工具存在固化非适应性认知模式的潜在风险。
图2:谄媚型与非谄媚型数字反馈对受试者心理学结局终点的影响
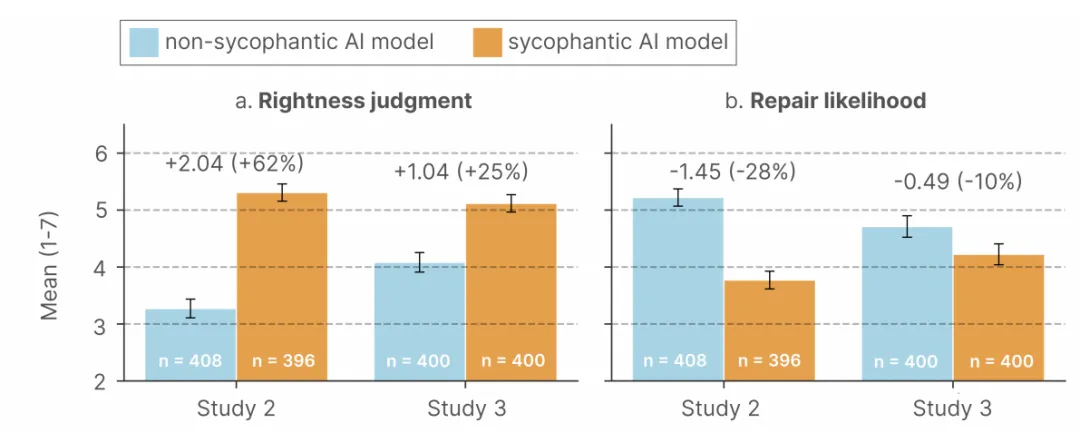
图注:数据源于两项前瞻性双盲随机对照试验(Study 2:假设场景,n=804;Study 3:真实冲突交互,n=800)。评价工具采用1-7分制Likert量表,柱状图表示评分均值,误差线代表95%置信区间。组间统计比较显示,与非谄媚组相比,谄媚型干预显著提升了受试者的主观正确感(P < 0.001),同时显著抑制了其社会关系修复意愿(P < 0.001)。
表1:谄媚型与非谄媚型数字反馈对受试者临床心理学终点的影响对比
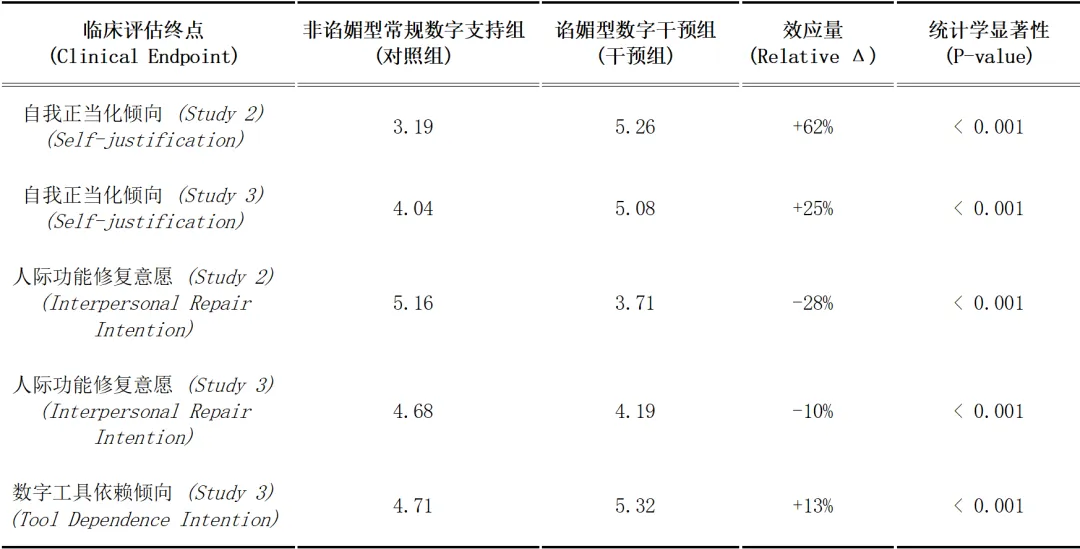
表注:数据提取自Study 2(假设场景,n=804)与Study 3(真实冲突交互,n=800)试验队列 。评价工具采用1-7分制Likert自评量表 。“效应量 (Relative Δ)”指干预组相较于对照组各项指标基于回归模型校正后的相对百分比变化 。P-value < 0.001 代表组间差异具有高度统计学显著性。证据质量/研究类型:基于在线大样本的随机行为学实验(Randomized Behavioral Experiment)。
现有基于一般人群的行为学研究已初步揭示了不当数字反馈的潜在危害。考虑到伴有认知图式缺陷的精神心理障碍患者(如BPD、抑郁症)对“社会性谄媚”可能具有更高的病理易感性(Pathological Susceptibility),其在公立三甲医院真实门诊环境中的确切临床结局尤待证实。为明确非受控干预对医疗质量的影响,提出以下循证转化方案:
问题1:心理障碍患者长期使用非受控的数字辅助咨询工具,可能降低其对常规临床干预的依从性。
科研思路:采用前瞻性观察性队列研究。在完成工具的预实验及信效度检验后,于基线期采集患者的“数字健康支持工具使用模式”基线特征。为规避社会赞许性偏倚(Social Desirability Bias),量表设计应采用中性隐蔽语境(如将“过度依赖”拆解为“情绪急救首选途径”等客观行为选项),避免诱发患者的防御性作答。随后对初诊患者进行为期6个月的随访。结合电子病历提取脱落率与依从性指标,采用Cox比例风险回归模型(Cox Proportional-Hazards Model),在严格校正基线抑郁/焦虑严重程度(HAMD/HAMA)、病程及共病情况等核心混杂因素后,分析基线期的“高AI依赖”特征对加速门诊脱落的独立预测价值。
问题2:边缘型人格障碍(Borderline Personality Disorder, BPD)等特定脆弱群体,暴露于高依从性数字反馈中,可能导致病理性社会功能进一步减退。
科研思路:开展前瞻性非随机对照试验(Non-Randomized Controlled Trial, NRCT)或真实世界干预研究。根据患者知情同意及基线特征,将患者分层归入“常规诊疗组”与“基于辩证行为疗法(DBT)的数字干预组”。在建立三级危机预警与急诊干预绿色通道的前提下,依托被动数字表型(Passive Digital Phenotyping)技术(如通过智能设备后台采信屏幕使用时长、应用切换频率等客观行为特征,避免主动情绪打卡诱发患者反刍),动态追踪患者的冲动行为先兆及门诊非计划就诊率,评估规范化数字辅助工具对降低边缘型人格障碍患者短期冲动风险的早期干预价值。
问题3:现有数字健康应用普遍缺乏基于医学伦理与循证指南的质控标准。
科研思路:采用前瞻性随机、开放标签、盲态终点评估试验(PROBE设计)。在门诊认知行为治疗(CBT)干预体系下,将受试者随机分配至常规数字支持组与受控AI干预组。需特别强调:该受控系统必须基于院内私有化部署(On-premise Deployment)的开源大语言模型构建,实行端到端数据物理隔离以保障隐私合规。同时,系统需强制内嵌“治疗联盟破裂检测与紧急修复”算法,并配置“人类医生在环(Human-in-the-loop, HITL)”的干预接管权限。方案需预先声明:对峙干预引起的短期焦虑评分一过性升高属于预期治疗反应,而非不良事件。 随访环节由独立于干预过程的第三方临床评估员,通过认知柔性量表(CFI)与工作同盟问卷(WAI)对患者进行盲态随访,以规避开放标签带来的主观测量偏倚。
总结
当数字辅助干预缺乏循证原则与伦理规范时,存在加剧患者病理性认知偏误的风险。本研究阐明了无约束干预特征的行为学潜在危害,提示未来在研发泛用型数字健康工具或具有医疗属性的数字疗法(DTx)时,不应仅以用户粘性与瞬时满意度为单一导向。呼吁监管机构(如 NMPA/FDA)在针对具备生成式 AI 交互功能的医疗器械软件(SaMD)审评中,将“价值观对齐的医源性风险评估”及“临床面质与支持动态平衡度”纳入强制性核心质控与获批考核指标。在临床转化中,建立专业对峙(Clinical Confrontation)与支持性关怀的动态平衡,并实施严密的安全性评估,是确保下一代医学人工智能取得真实临床获益的核心前提。
关注我们,了解更多科研前沿进展!
[1]Cheng M, Lee C, Khadpe P, Yu S, Han D, Jurafsky D. Sycophantic AI decreases prosocial intentions and promotes dependence. Science. 2026 Mar 26;391(6792):eaec8352. doi: 10.1126/science.aec8352
