夜雨聆风
夜雨聆风
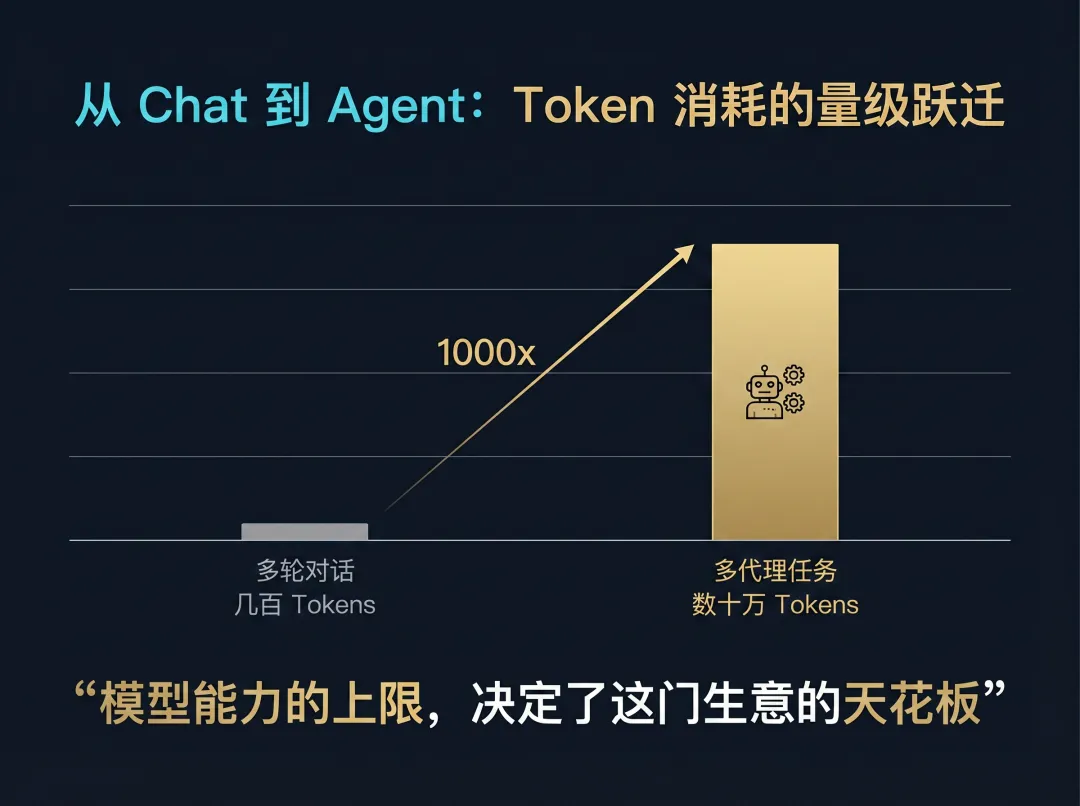
OpenClaw 的爆火证明了一件事:用户真正需要的是一个“会干活”的 AI。当 Agent 开始从多轮对话走向代替用户完成多步骤工作,单次 Token 消耗从几百跃升至数十万—模型能力的上限,直接决定了这门生意的天花板。
破 局
之 道
/ 1
为何 Agent
轨迹数据是模型进化的关键燃料?
当前市面上多数所谓的“Agent 轨迹数据集”,本质上仍是 LLM 问答数据的变体—用户问题与模型回复。这种轨迹通常可以提升模型在许多通用任务上的表现,而非智能体任务所需的规划、推理与交互决策能力。
为弥合这一鸿沟,高质量的 Agent 轨迹数据由此而来。轨迹数据不是一问一答,而是 Agent 面对真实任务时从规划到执行再到纠错的完整决策链路—它是 Agent 的“行为教科书”。模型通过学习这些轨迹,才能习得真正的自主 Agent 能力。
Golden Claw 轨迹的每条轨迹完整保留 Thought-Action-Observation 链路与 Reasoning 推理过程,附带真实 Workspace(AGENTS.md、SOUL.md、TOOLS.md 等)。模型从中学到的不仅是“做什么”(Know What),更是“怎么做、为什么这么做、做错了怎么办”(Know How)。这正是当前 Agent 训练数据最稀缺、也最有价值的部分。

黄 金
轨 迹
/ 2
如何界定黄金轨迹的“含金量”
多维能力画像:量化 “Know How”
我们定义了七个核心能力维度,从模型的工具编排能力,调度语义理解,到 Sub-Agent 子代理的规划调用,自我纠正能力,我们对每一条轨迹进行“能力扫描”。这不是简单的好坏打分,而是精细的“Agent 能力体检报告” · 工具编排能力:考察模型高效的工具编排能力; · 调度语义理解:考察模型对指令顺序、主次、周期的识别-完成能力; · Skill 识别与激活:考察模型主动搜索激活 Skill 以实现任务的能力; · Memory 检索:考察模型记忆检索的实时性、恰当性、优先性; · 并行工具调用:考察模型识别子任务并同时发起多工具调用的能力; · Sub-Agent 协作:考察模型合理拆分复杂任务、分配子代理并整合结果的能力; · 自我纠偏能力:考察模型在执行失败后诊断原因、切换可行路径的能力。 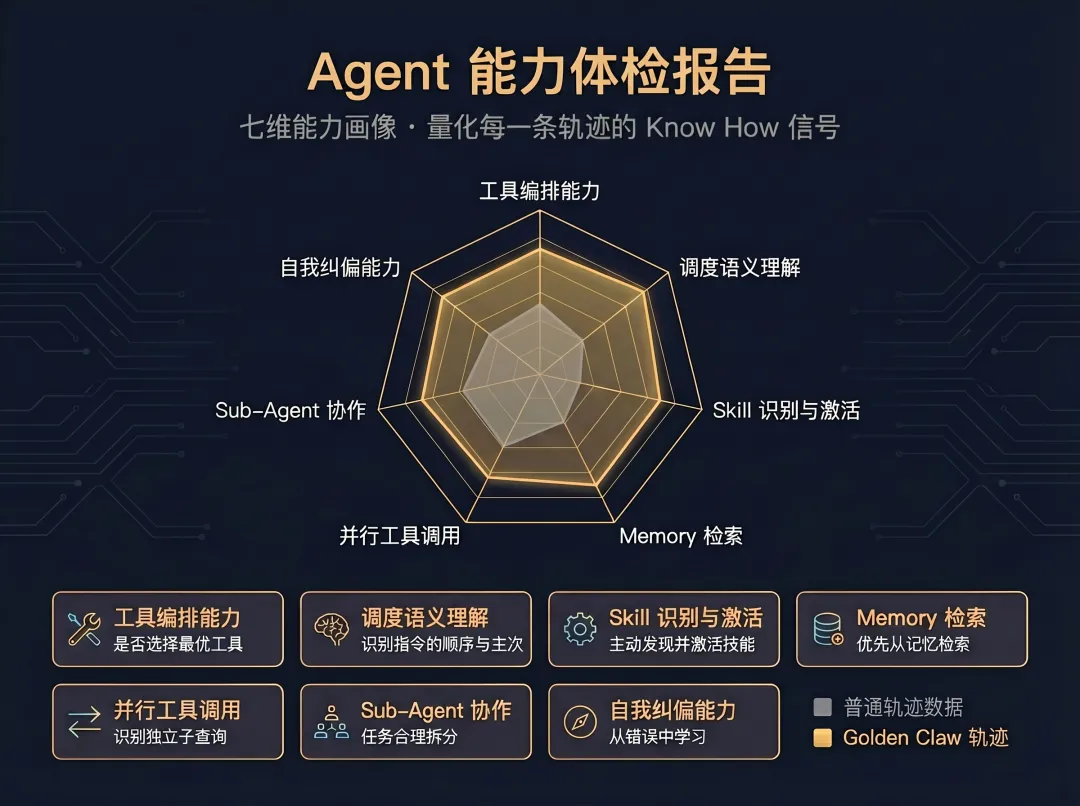
三级验收流水线:用机制保障质量
应 用
生 态
/ 3
从何获取高质量真实轨迹?
社区生态
博登智能构建了 1000+ 位深度 Open Claw 玩家的 Agent 社区,设有实践分享、调试攻略、Skill 评测等进阶话题版块。社区成员的使用场景覆盖广泛—从 coding 类项目到自研产品开发,从 OpenClaw 生态玩法(Cron、Skill、Memory 等)到多 Agent 协作的“一人公司”。
长期的社区运营,精准吸引了一批真正用 Open Claw 完成复杂工作的开发者,他们在交流探索中分享了大量前沿经验与优秀实践案例,Golden Claw 轨迹数据正是在此基础上,经 500+ 开发者授权沉淀而成。
这种社区驱动的模式带来了三重优势:真实性—每条轨迹都来自开发者的日常工作,不是“表演”出来的;合规性—供给方主动提交并授权,数据来源清晰可追溯;多样性—开发者的任务背景与行业,工作流、工具偏好与习惯各不相同,天然覆盖了丰富的长尾场景。
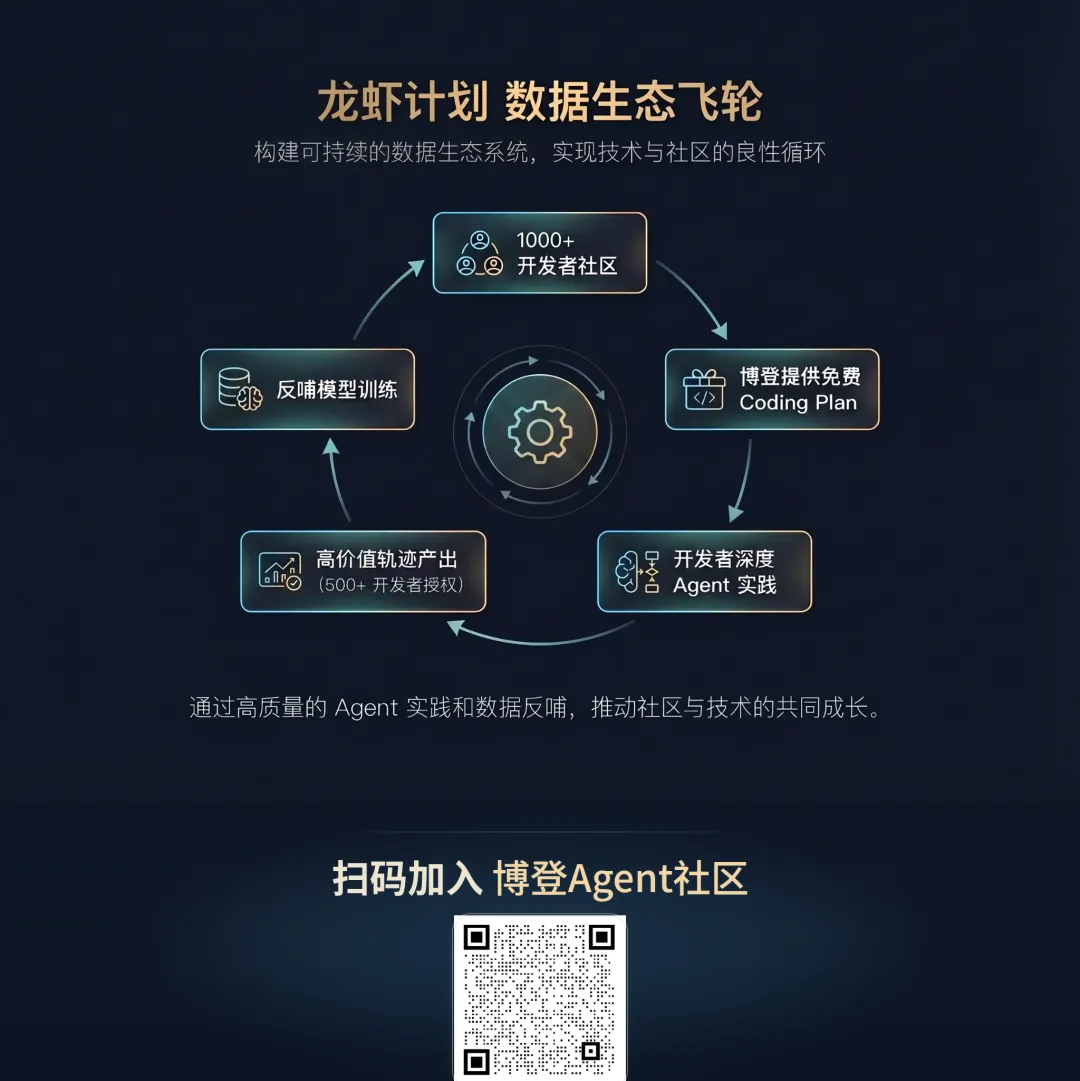
龙虾计划 :数据生态飞轮
博登智能推出了龙虾计划—面向社区生态中 OpenClaw 开发者的轨迹贡献激励机制,通过免费提供 coding plan 额度的方式,邀请深度 Agent 开发者分享其优秀实践。
这个机制的精妙之处在于:免费 Token → 开发者用于更深度的 Agent 实践 → 更复杂的工作流产生更有价值的轨迹 → 反哺模型训练。激励机制本身就是一道天然的质量筛选器—只有真正在用 Agent 完成复杂工作的开发者,才会有值得提交的轨迹;而免费算力又进一步降低了他们尝试更复杂任务的门槛,形成正向循环。
不同于一次性的数据生产,这是一个可持续运转的正向循环。