 夜雨聆风
夜雨聆风科学计算神器-Numpy的使用 科学计算神器-Pytorch的使用 基本统计量和数据预处理 内容小结
矩阵的基本操作 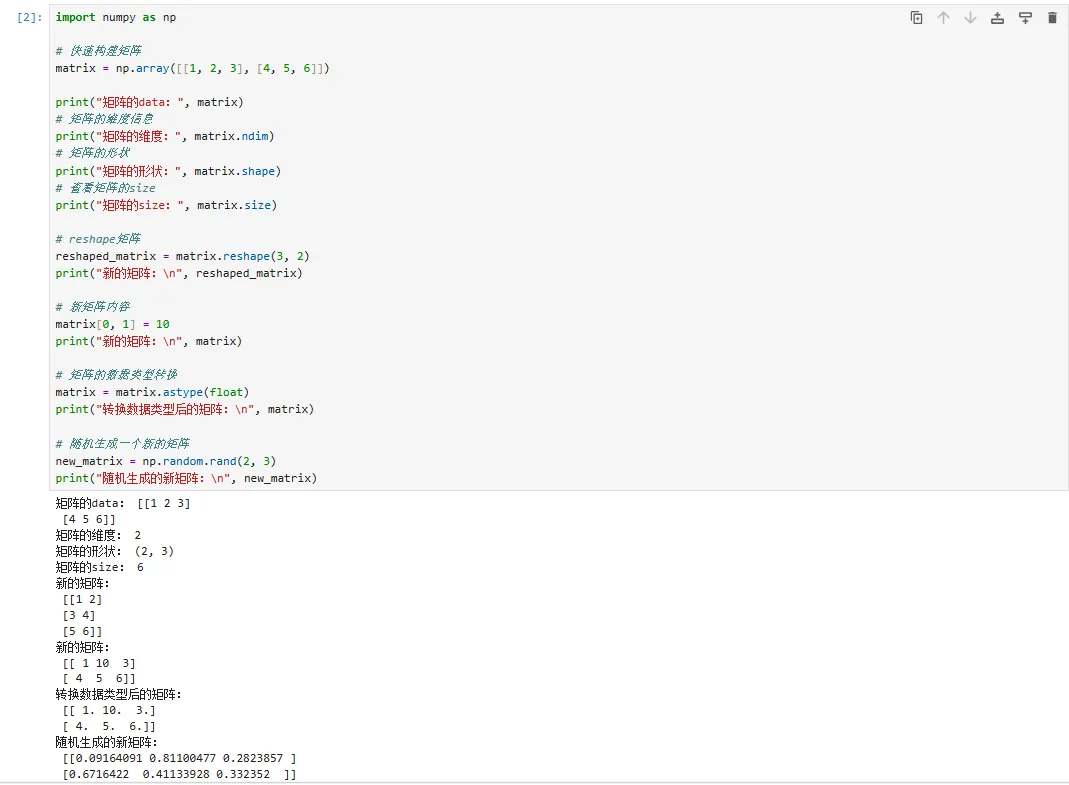
使用Numpy生成矩阵 
打印输出: 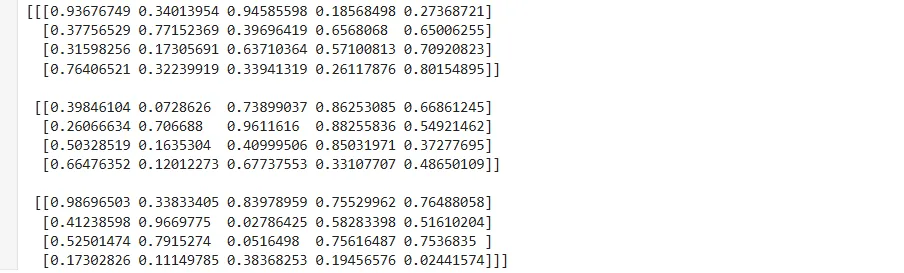
三D图形如下: 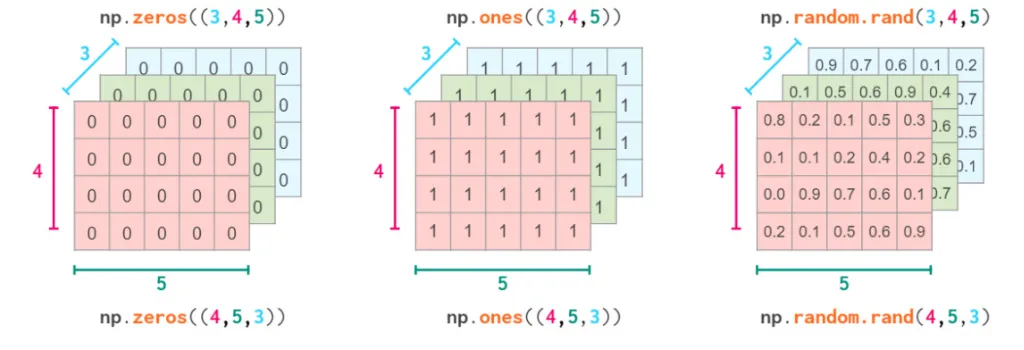
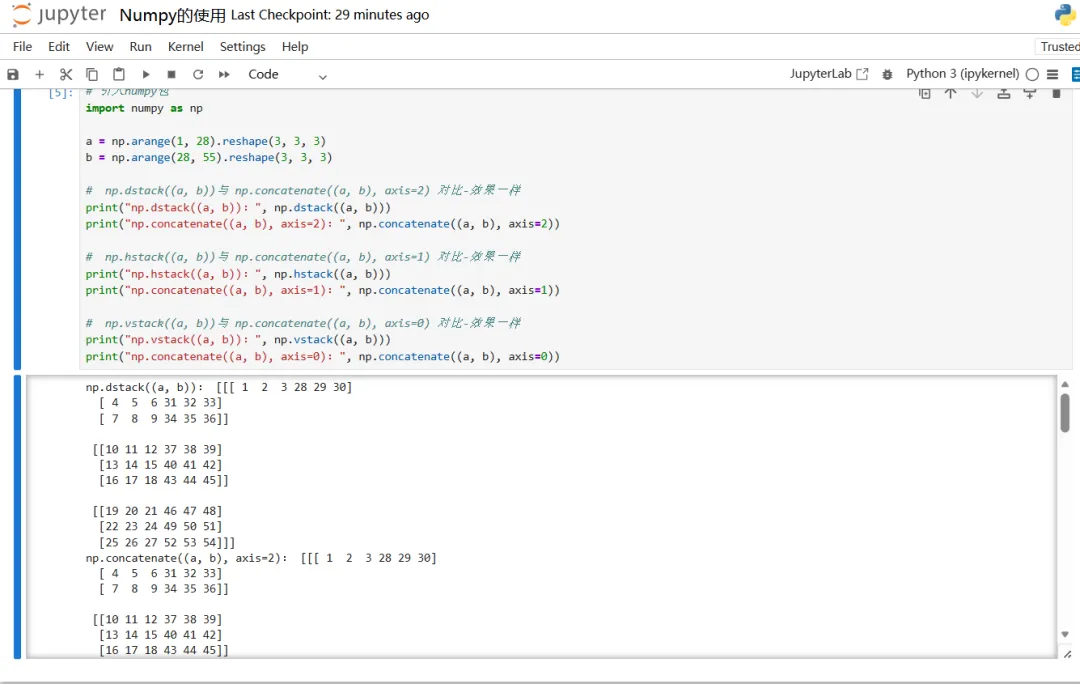
矩阵的堆叠和拼接
numpy.concatenate:
- concatenate是一个通用的函数,用于沿指定轴连接数组。
- 可以在指定的轴(axis)上连接两个或多个数组。
- 可以控制连接的方向,例如沿行(axis=0)或列(axis=1)进行连接。
numpy.stack:
- stack 是用于沿新轴(堆叠轴)堆叠数组的函数。
- 创建一个新轴来堆叠数组,改变数组的维度。
- 可以通过 axis 参数控制在哪个位置添加新轴。
numpy.vstack:
- np.vstack 是用于垂直(沿着行方向)堆叠数组的函数。
- 将两个或多个数组按行堆叠在一起。
numpy.hstack:
- np.hstack 是用于水平(沿着列方向)堆叠数组的函数。
- 将两个或多个数组按列堆叠在一起
numpy.dstack:
- np.dstack 是用于深度(沿着第三维)堆叠数组的函数。
- 将两个或多个数组按深度方向堆叠在一起
代码如下:
三维图形展示:
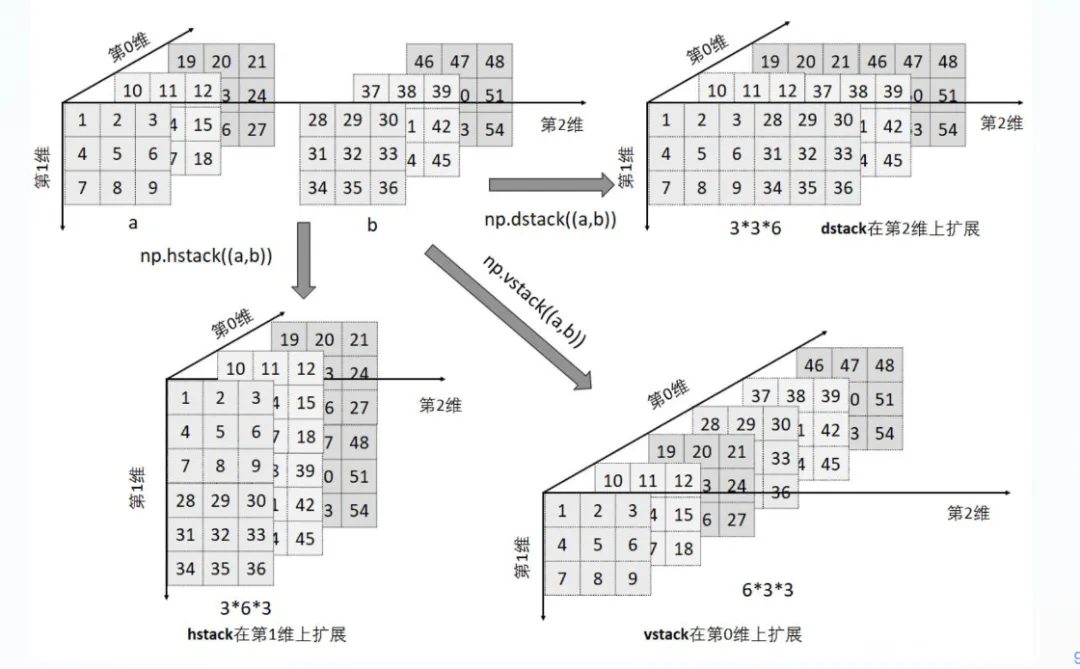
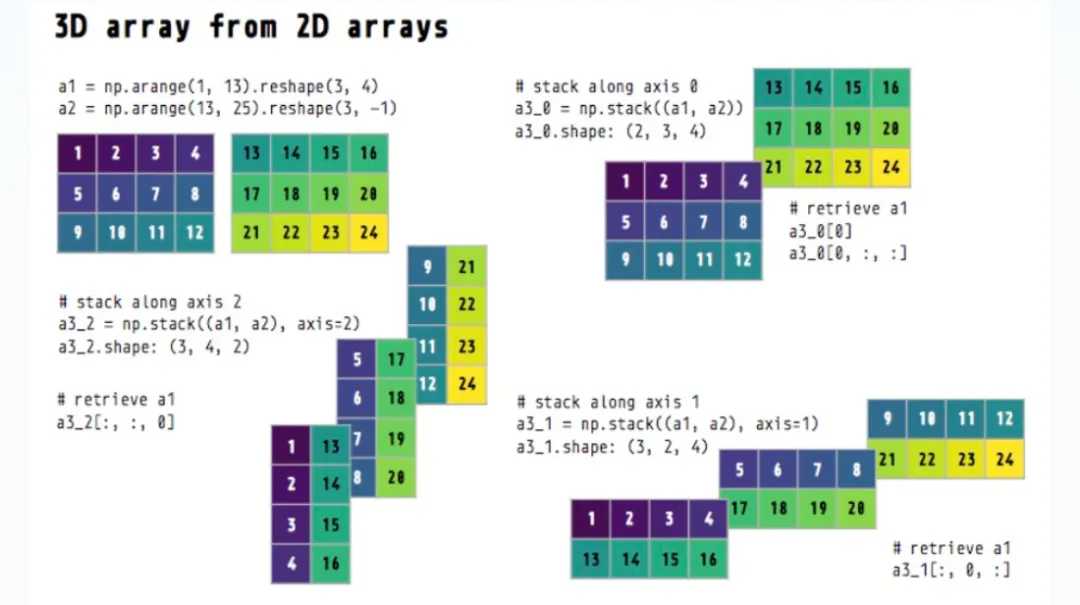
numpy.stack的使用:
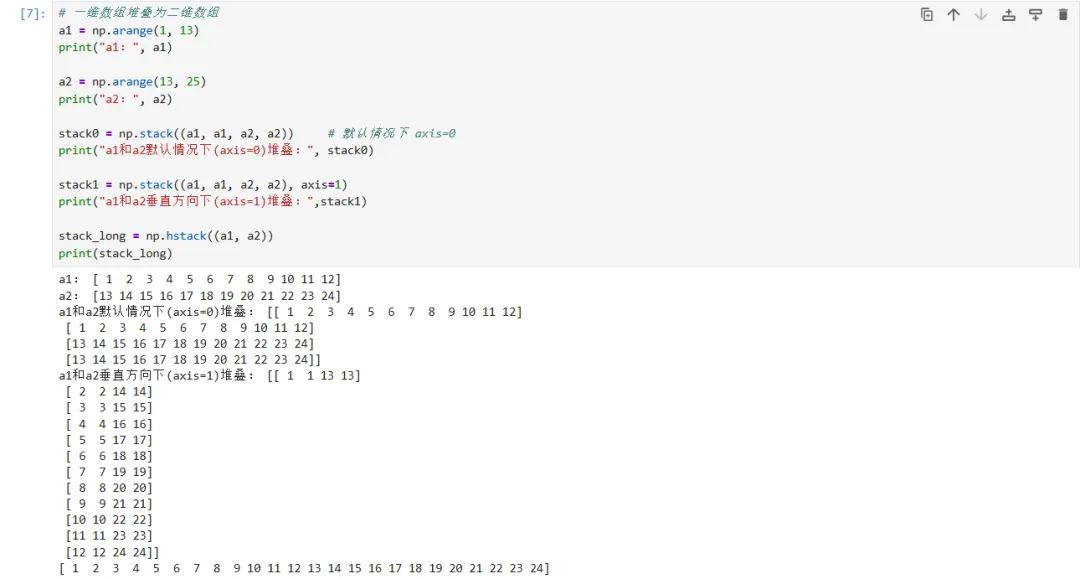
一维数组堆叠二维数组代码如下:
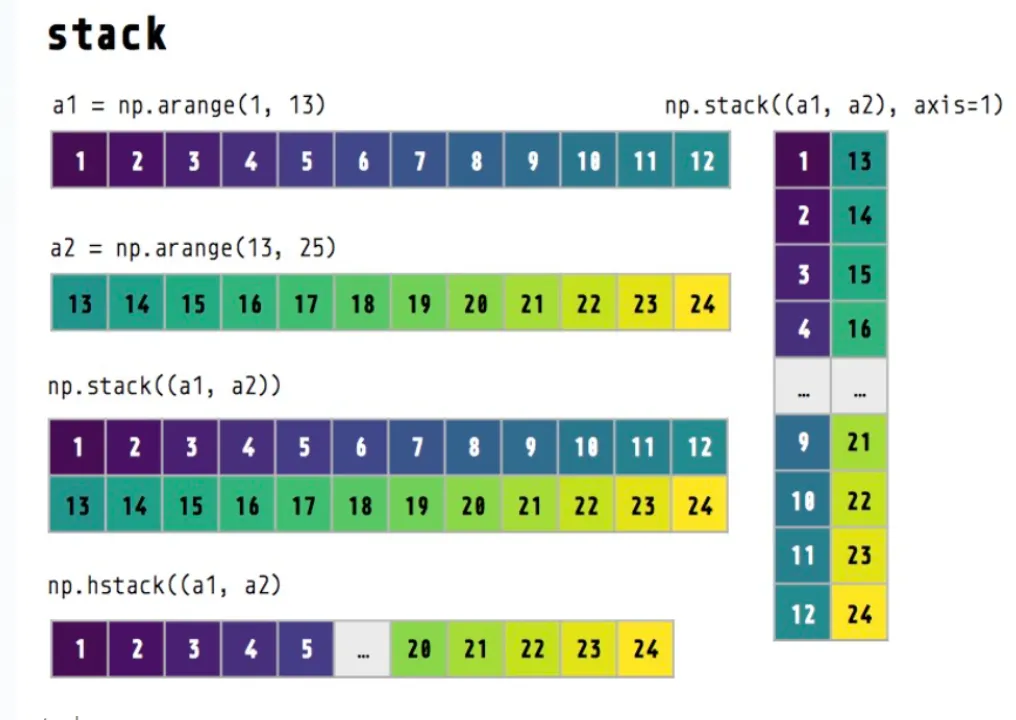
图形展示:
二维数组堆叠三位数组代码如下: 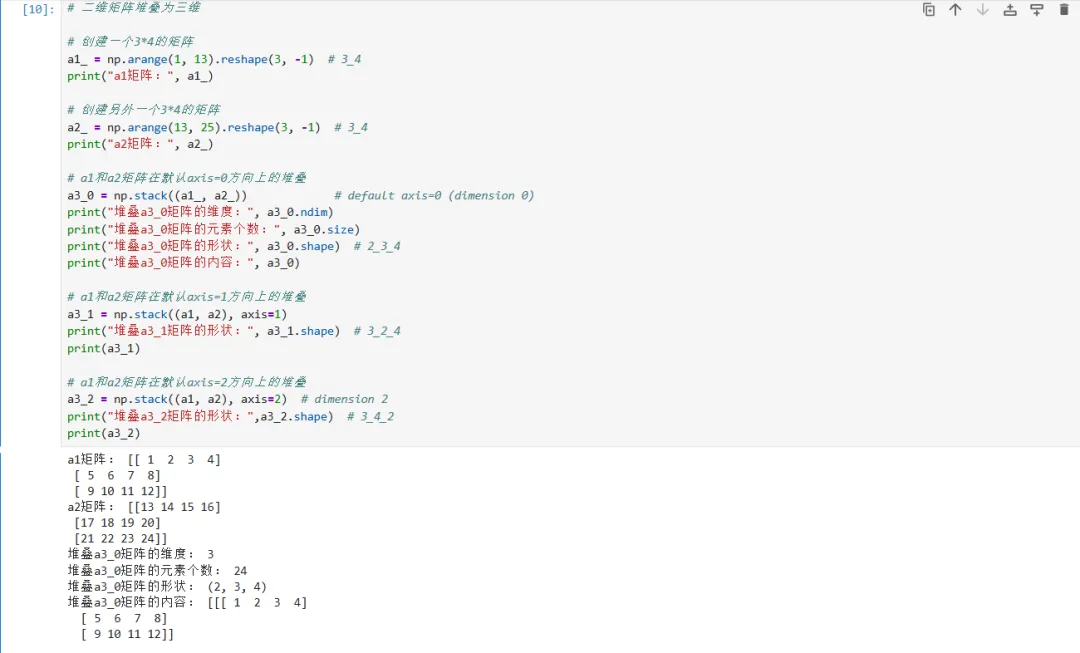
PyTorch也是一个常用的科学计算库,相比Numpy,Numpy只能运行在CPU,PyTorch可以运行在GPU上运行,加快计算。
Pytorch安装
第一步:# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
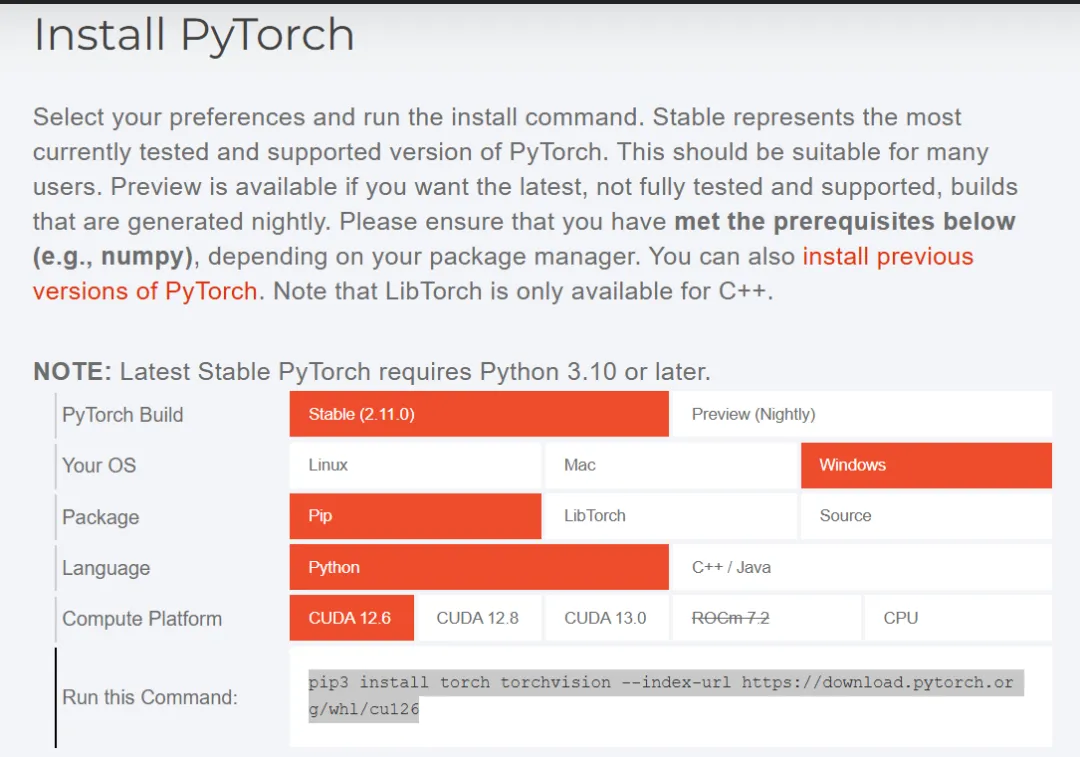
第二步:访问https://pytorch.org/ ,根据自己机器的环境选择对应的pytorch安装命令
复制命令执行,耐心等待下载安装:
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu126
第三步:启动命令行,运行对应的安装命令
注意:如果使用的是jupyter,建议通过开始菜单启动anaconda prompt的方式运行命令行
# 如果操作系统=window、显卡有英伟达显卡、显存>4G,则可以运行如下命令:pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 如果操作系统=window、无英伟达显卡、显存不够只能使用CPU,则可以运行如下安装命令:pip3 install torch torchvision torchaudio
# 如果操作系统=Mac,则可以运行如下安装命令:pip3 install torch torchvision torchaudio
# 如果操作系统=Linux,则可以运行如下安装命令:pip3 install torch torchvision torchaudio
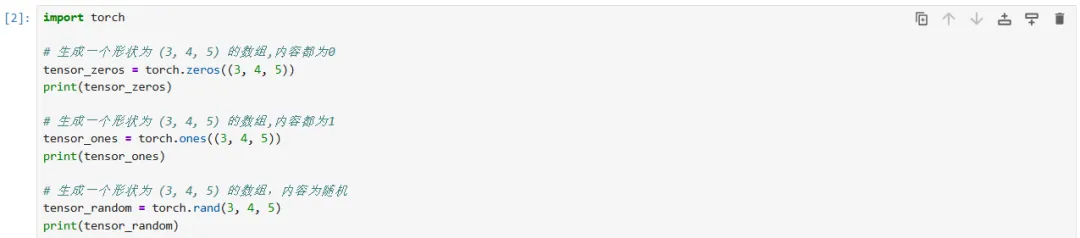
矩阵的基本操作(使用torch)

矩阵的生成(使用torch)
矩阵的堆叠和拼接(使用torch)

通过以上对比可以发现
numpy和torch的使用方法基本一致,numpy支持的计算方法torch也支持 两者都提供了类似的数组/(torch里叫张量)操作,如索引、切片、广播、数学运算等 numpy也可以与torch进行互转,例如:

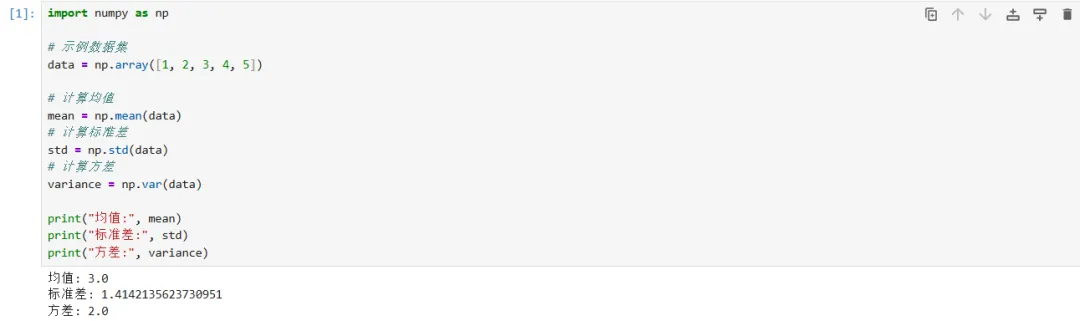
基本统计量
均值-Mean
定义:均值是一组数据中所有数据值的总和除以数据值的个数。
作用:表示一组数据的平均值。
计算方法:均值 \mu = \frac{\sum_{i=1}^{n} x_i}{n},其中 x_i 是数据集中的每个数据值,n 是数据值的个数。
标准差-(Standard Deviation)
定义:标准差是方差的平方根,用于衡量数据值的离散程度。
作用:表示数据的离散程度。
计算方法:标准差 \sigma = \sqrt{\frac{\sum_{i=1}^{n} (x_i - \mu)^2}{n}},其中 x_i 是数据集中的每个数据值,\mu 是均值,n 是数据值的个数。
方差(Variance)
定义:方差是每个数据值与均值之差的平方的平均值。
作用:表示数据与均值之间的差异程度。(如果比较离散的话,方差越大;如果比较集中的话,方差越小)
计算方法:方差 \sigma^2 = \frac{\sum_{i=1}^{n} (x_i - \mu)^2}{n},其中 x_i 是数据集中的每个数据值,\mu 是均值,n 是数据值的个数。
代码如下:
数据预处理
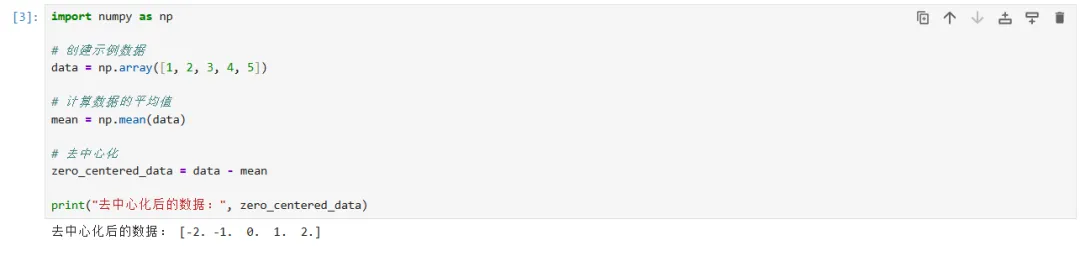
1.归一化(Normalization)-线性映射:
备注:这里的归一化容易与上篇课程皮尔逊系数:协方差的归一化搞混,仔细查看皮尔逊系数是将两列数据变化趋势归一化到[-1,1]之间;此处的归一化是将一组数据归一化到[-1,1]之间。

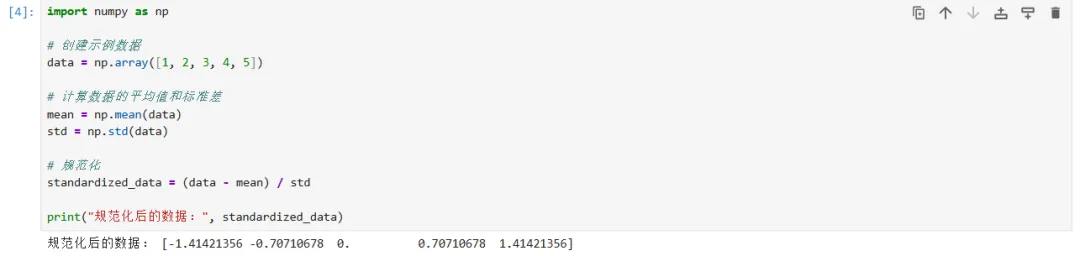
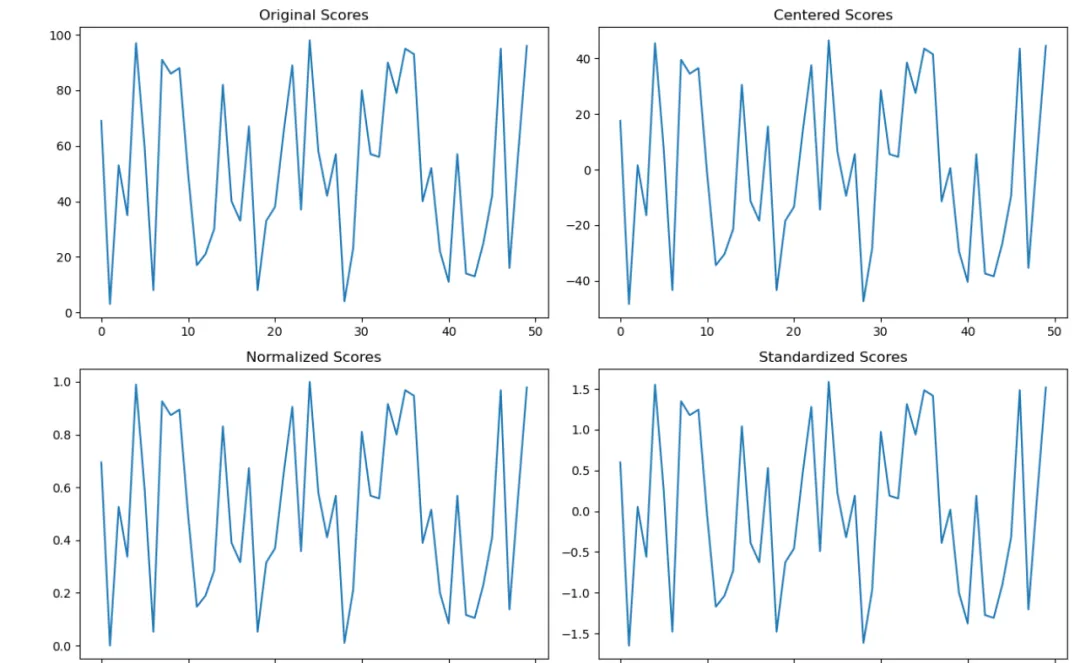
通过以上的对比可以看到,中心化Scores、归一化Scores、标准化Scores的数据虽然被修改了,与原始Scores不一样,但是数据中所表达的信息(曲线)仍然没有丢失,这即是信息蕴含在数据的相对大小。
数据预处理的应用
在机器学习当中,我们往往要对数据进行预处理,以提升数据质量,使得不同特征具有相似的尺度,有助于模型的收敛和性能提升。以下仍然使用鸢尾花的示例,来实际验证下数据预处理是否会对准确率有影响。
代码如下:
# 加载鸢尾花数据集:
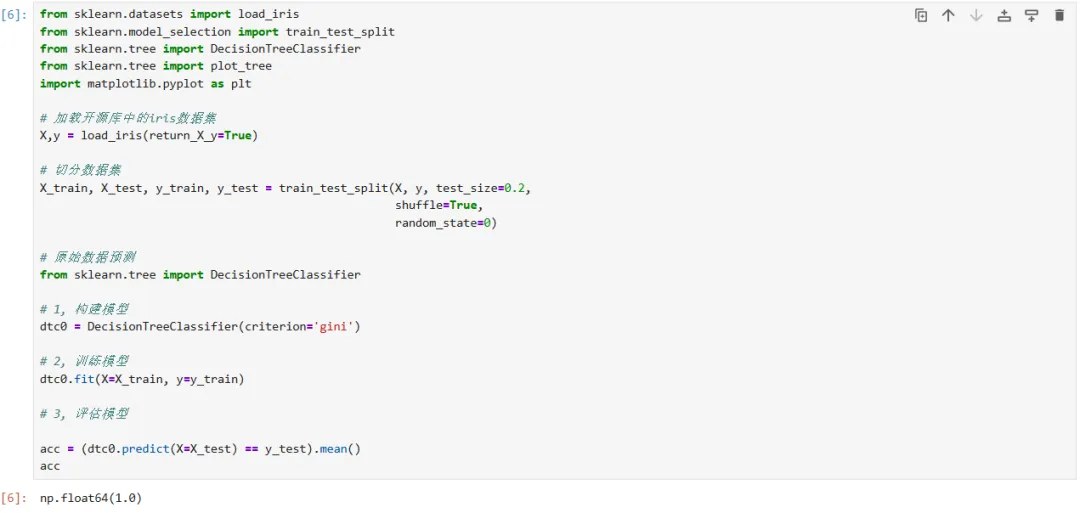
# 减均值(中心化):


执行以上代码,可以看到原始数据、归一化数据、去中心化数据、规范化数据在训练之后,预测结果都为1.0
四、内容小结
