 夜雨聆风
夜雨聆风上一篇我讲的是 Superpowers。
它解决的是一个问题:
怎么让 AI 不要乱做事,而是按工程流程一步一步来。
但当你真的用起来一段时间之后,很快会遇到另一个问题:
这些过程,最后都去哪了?
需求讨论、设计取舍、任务拆解、验证结果……
很多时候,还是只活在聊天记录里。
于是你会进入一个很熟悉的循环:
每次继续推进,都要重新把背景再讲一遍。
OpenSpec,其实就是在补这一层。
简单说,OpenSpec 是一套把 AI 编码从“聊天推进”改成“工程推进”的中间流程。
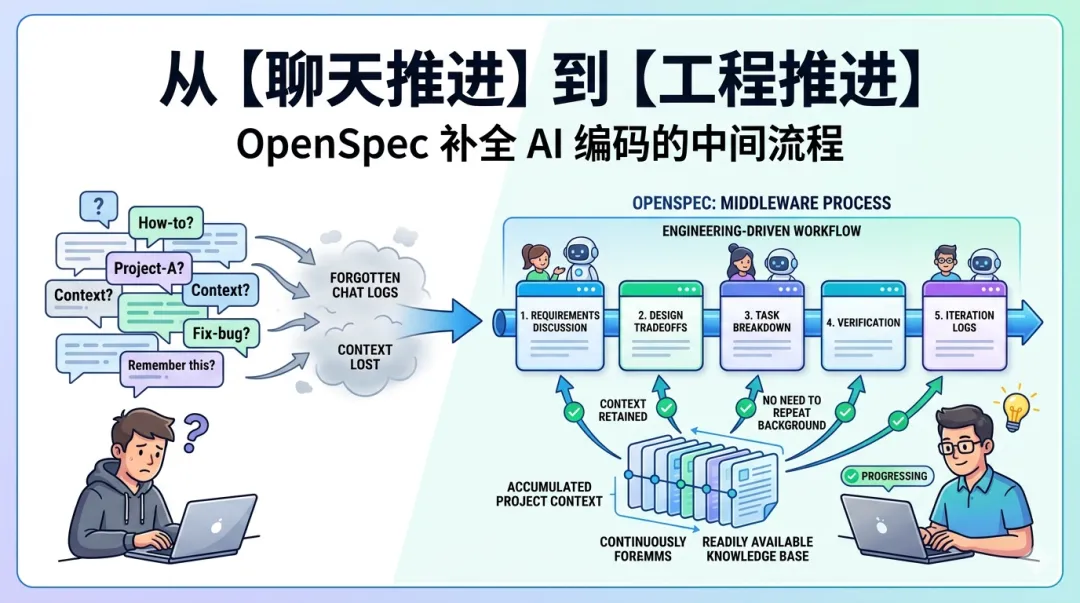
它真正要解决的,是让 AI 不要只沿着对话往前冲,而是沿着一组可以被讨论、被审阅、被归档的产物往前走。
如果没有 OpenSpec,很多 AI 编码其实是这样发生的:
1. 你在聊天窗口里描述一个需求。 2. AI 根据当前上下文猜它应该做什么。 3. 它开始改代码、补文件、跑测试。 4. 后面如果方向变了,就继续在聊天里修修补补。
这种方式最大的问题,不是它完全不能用。
而是它太依赖“当前上下文还记得多少”。
需求、边界、非目标、技术取舍、任务拆解,全都混在一条不断滚动的消息流里。对人来说难复盘,对 AI 来说也难保持稳定。
OpenSpec 的切入点很直接:
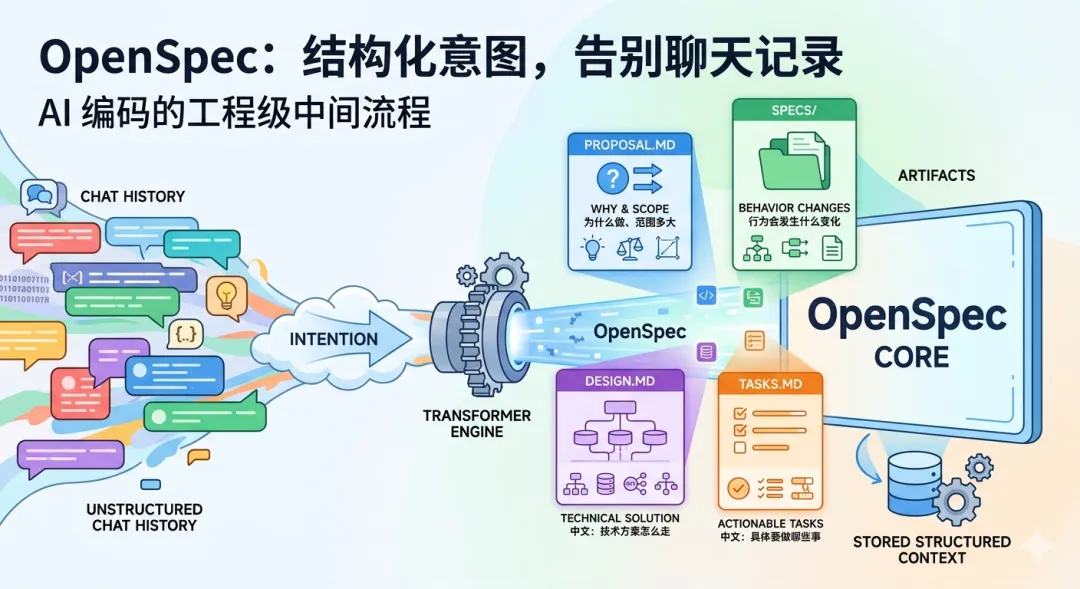
不要让意图只留在聊天记录里,要把意图落进一组有结构的 artifact。
它给的是一套中间层,让一次改动至少有这些东西:
• proposal.md:为什么做、范围多大• specs/:行为会发生什么变化• design.md:技术方案怎么走• tasks.md:具体要做哪些事
这层中间结构,才是 OpenSpec 的核心产品。
如果你看过 Superpower,会更容易理解 OpenSpec
如果你看过我前面写的 Superpower,那理解 OpenSpec 会快很多。
因为这两个东西,解决的其实不是同一层问题。
Superpower 更像是在约束 Agent 的行为顺序。
它关心的是:
• 先不要急着改代码; • 先复现问题; • 先验证假设; • 没证据别宣布完成; • 先澄清需求,再进入执行。
也就是说,Superpower 更像一套“工作纪律”。
它要解决的是:AI 明明很聪明,但太容易过早行动。
OpenSpec 补的则是另一层。
它不是主要去约束“你现在先做哪一步动作”,而是去约束“这次改动必须留下哪些中间产物”。
它关心的是:
• 这次到底为什么改; • 范围多大,哪些不做; • 行为会发生什么变化; • 技术方案是什么; • 任务清单怎么拆; • 最后怎么把变更归档回主规范。
如果把它们放在一起看,可以这样理解:
所以如果用一句话概括它们的差异,我会写成:
Superpower 是在教 AI 怎么做事,OpenSpec 是在规定这件事做完之后必须留下什么。
这也是为什么我会觉得 OpenSpec 的重点不是“让 AI 更聪明”,而是“让一次改动更像工程对象,而不是一次聊天结果”。
OpenSpec 到底长什么样
一个典型的 OpenSpec 项目,核心是这样一个目录:
openspec/├── specs/│ └── <domain>/spec.md└── changes/ └── <change-name>/ ├── proposal.md ├── design.md ├── tasks.md └── specs/这个结构本身,就已经把它的心智模型说得很清楚了。
它把世界分成两层:
1. specs/:系统当前行为的 source of truth2. changes/:每一次拟议中的改动
也就是说,它默认承认一件现实:
大部分软件开发不是从零开始写系统,而是在已有系统上做增量修改。
这也是它为什么一直强调自己是 brownfield-first。
它更适合那种“项目已经存在,现在要把改动讲清楚”的场景。
而且它不是要求你每次重写一整份完整 spec。
它更强调 delta spec,也就是只写“这次改了什么”。
比如:
• ADDED Requirements• MODIFIED Requirements• REMOVED Requirements
这不是格式洁癖。
这是它为增量开发专门设计的表达方式。
OpenSpec 的实现,其实比表面上的命令更值得看
如果你只看 README 里的命令,很容易把 OpenSpec 理解成一个“会生成 Markdown 的 CLI”。
但它真正有意思的地方,其实在实现骨架。
从公开文档能看出来,OpenSpec 至少有这么几层:
1. 目录层 • openspec/specs/保存当前行为的 source of truth• openspec/changes/保存每一次独立 change2. artifact 层 • proposal.md• specs/**/*.md• design.md• tasks.md3. schema 层 • 默认是 spec-driven• schema 会定义 artifact 的类型、生成路径、依赖关系 4. workflow 层 • coreprofile 给默认 quick path• OPSX 给 expanded workflow 5. config 注入层 • openspec/config.yaml可以把项目 context 和 rules 注入到 artifact 指令中
把它翻译成人话,就是:
OpenSpec 不是只靠一段 prompt 工作。
它是靠一组目录约定 + artifact 约定 + schema 依赖图 + 配置注入共同工作的。
它不是把一句 prompt 写得更长。
它是把 workflow 本身拆成了几个稳定部件。
OpenSpec 最聪明的地方,是它先给你一条很短的默认路径
很多流程类工具的问题,是一上来就太重。
OpenSpec 在这点上反而比较克制。
它的默认 quick path 很短:
/opsx:propose -> /opsx:apply -> /opsx:archive截至 2026 年 4 月 19 日,文档把这条链路称为默认 core profile。
对应的关键命令是:
/opsx:propose | |
/opsx:explore | |
/opsx:apply | tasks.md 实施并更新任务状态 |
/opsx:archive |
这条路径的好处,是用户第一次就能跑通一个完整闭环。
新手最适合怎么开始用 OpenSpec
如果你从来没碰过 OpenSpec,别一上来就想着全团队上流程。
更稳的路径是:
1. 选一个你最近肯定会改的小功能或小 bug。 2. 在项目里执行 openspec init。3. 用 /opsx:propose开一个真实 change。4. 看看它生成的 proposal/specs/design/tasks,是不是比聊天记录更清楚。5. 再用 /opsx:apply往下推进一次真实实现。6. 最后用 /opsx:archive走完归档。
最适合新手的场景,通常有三类:
• 功能增量:加 dark mode、补 loading state、加表单校验。 • 行为修复:修登录 bug、补边界条件、收敛错误处理。 • 现有项目改造:把旧流程、旧模块、旧规范改成更可描述的 change。
这些任务有一个共同点:都不是从零开始写新系统,而是在已有系统上做可验证的变更。
这恰好就是 OpenSpec 最舒服的区间。
如果你准备自己用好它,记住一个原则
如果你准备认真把 OpenSpec 放进团队流程,记住一个原则:
不是文档越多越好,而是意图越清楚越好。
至少要盯住四件事:
更稳的做法通常是:
1. 先把 proposal 写清楚; 2. 再用 specs 讲行为变化; 3. 再用 design 讲技术路径; 4. 最后用 tasks 把工作拆成可执行动作。
这样 AI 的实现过程,才不容易回到“边猜边写”的老路上。
最后
OpenSpec 最值得保留的优势,是它没有把自己做成一个完全封闭的平台。
它更像一个可以长在现有 AI coding assistant 外面的结构层。
它最大的代价,则是你必须接受一件事:
AI 编码想变稳,靠的不是把 prompt 说得更长,而是把该沉淀的东西真的沉淀下来。
这也是我看完 OpenSpec 之后最强烈的感受。
它真正想解决的,不是如何让 AI 更会写代码。
而是如何让 AI 写代码这件事,开始像工程,而不只是像聊天。
