 夜雨聆风
夜雨聆风你有没有遇到过这种情况——AI 上周刚告诉你的项目背景,这周再问它,它一脸茫然。你们之间没有「共同记忆」,每次对话都像重新认识一个陌生人。这不是 AI 的态度问题,是架构问题。
OpenClaw 在 v4.5 版本引入了一个名为「梦境」(Dreaming)的核心功能,专门来解决 AI 代理的「失忆症」。它的核心思路来自人类神经科学:大脑在睡眠期间会整理白天的短期记忆,筛选出重要的信息转化为长期知识。
OpenClaw 做了同样的事——每天凌晨 3 点,你的 AI 会自动进入「睡眠」,把过去一天的对话碎片整理、评分、归档,让有价值的记忆真正积累下来,而不是随着会话结束就消失。
一、先搞懂:OpenClaw 的五层记忆体系
梦境不是凭空运行的,它依托于 OpenClaw 的一整套分层记忆架构。理解这个体系,是用好梦境功能的前提。
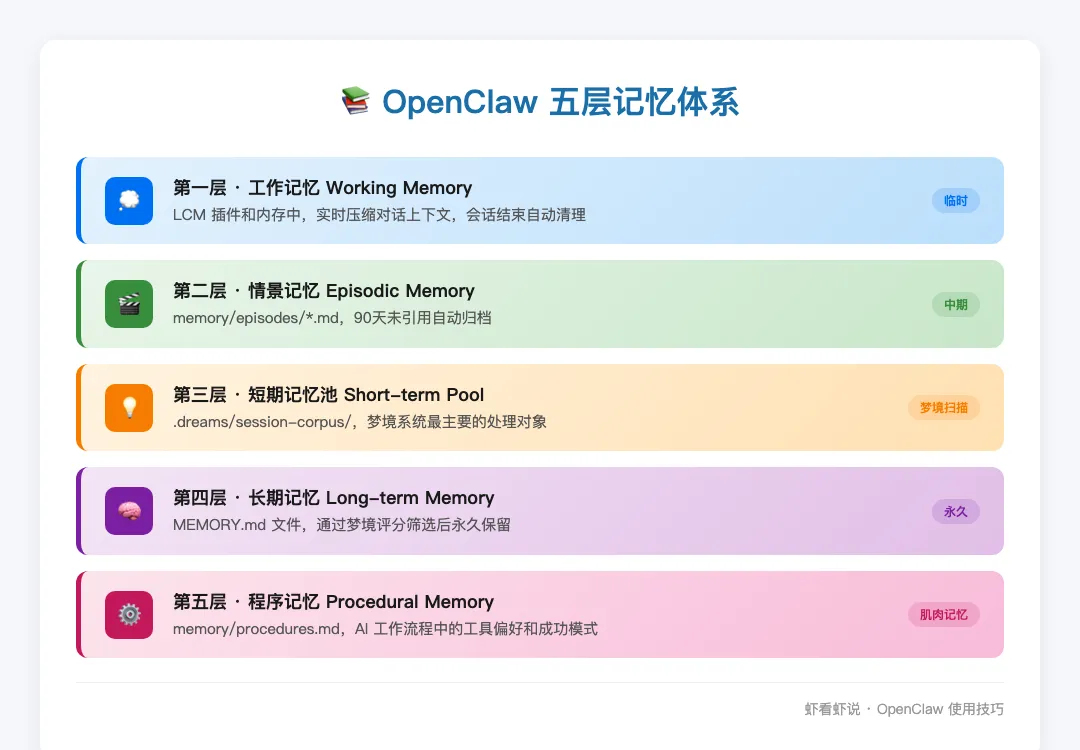
图:OpenClaw 五层记忆体系全景
第一层:工作记忆(Working Memory)
存在于 LCM 插件和内存中,负责实时压缩对话上下文、处理当前任务逻辑。会话结束后自动清理——相当于电脑的 RAM,断电就没了。
第二层:情景记忆(Episodic Memory)
存储在 memory/episodes/*.md,记录特定项目的叙事脉络和事件时间线。如果 90 天没有被引用,系统会自动归档——类似于把老照片移出相册。
第三层:短期记忆池(Short-term Memory Pool)
这是梦境系统最主要的处理对象。存储在 .dreams/session-corpus/ 目录下,内容是脱敏后的会话片段和搜索回溯轨迹。梦境每天扫描的就是这里。
第四层:长期记忆(Long-term Memory)
就是 MEMORY.md 文件。经过梦境评分筛选后被认为关键的信息,最终会写入这里,永久保留。
第五层:程序记忆(Procedural Memory)
存储在 memory/procedures.md,记录 AI 在工作流程中成功使用的模式、工具偏好。相当于「肌肉记忆」——通过不断成功执行来强化。
二、梦境的三阶段:AI 是怎么「睡觉」的
每天凌晨 3 点(可配置),OpenClaw 会执行一轮完整的梦境扫描。整个过程模拟人类睡眠的三个阶段,每一步都有明确的输入输出逻辑。

图:梦境三阶段工作流程
第一阶段:浅睡眠(Light Sleep)— 信号摄取与去重
系统首先扫描过去 24 小时内(可通过 maxAgeDays 配置)的每日日志 memory/YYYY-MM-DD.md 和会话转录。这里用到的核心技术是基于 Jaccard 相似度的语义去重,默认阈值 0.9。也就是说,如果两条信息的内容重复度达到 90%,系统会自动合并,防止同一事实因为表达方式略有不同而被重复计算。
💡 关键点:浅睡眠阶段不会直接向 MEMORY.md 写入任何内容。它的产出是记录在 .dreams/ 目录下的「强化信号」,作为后续深度评分的初始值。
第二阶段:REM 睡眠 — 模式识别与跨会话关联
这是梦境系统「思考」自己经历的时刻。系统会分析短期记忆池中的概念标签频率,通过后台子代理(Subagent)提取对话中的潜在主题和反思性信号。
REM 阶段最大的价值在于发现跨会话的关联性。举个例子:如果你周一讨论了 API 安全,周三又讨论了 OAuth 实现,REM 阶段会识别出「安全性」这个核心主题,并在 DREAMS.md 中生成一个 ## REM Sleep 块。
第三阶段:深睡眠(Deep Sleep)— 知识晋升与持久化
这是梦境功能的最终「决策门」。系统会调用一套六维加权评分算法,对所有候选记忆进行最终评分。只有同时通过 minScore(最低核心性得分)和 minRecallCount(最低被召回次数)两道关卡的记忆,才会被写入 MEMORY.md。
在写入之前,系统还会执行一个极其关键的安全机制——片段重水化(Rehydration)。系统会重新读取原始日志文件,确认那些在白天被你手动删除或修改过的信息不会被误写进长期记忆。
三、六维评分模型:系统是怎么判断什么值得记住的
梦境功能的评分体系透明且可量化,每个记忆条目都会经过动态评估。核心公式考虑三个维度:基础权重(高频提及翻倍,永久标记恒定 1.0)、衰减因子(6 个月以上的陈旧信息自动边缘化)、引用增强(频繁检索的信息获得对数级加分)。
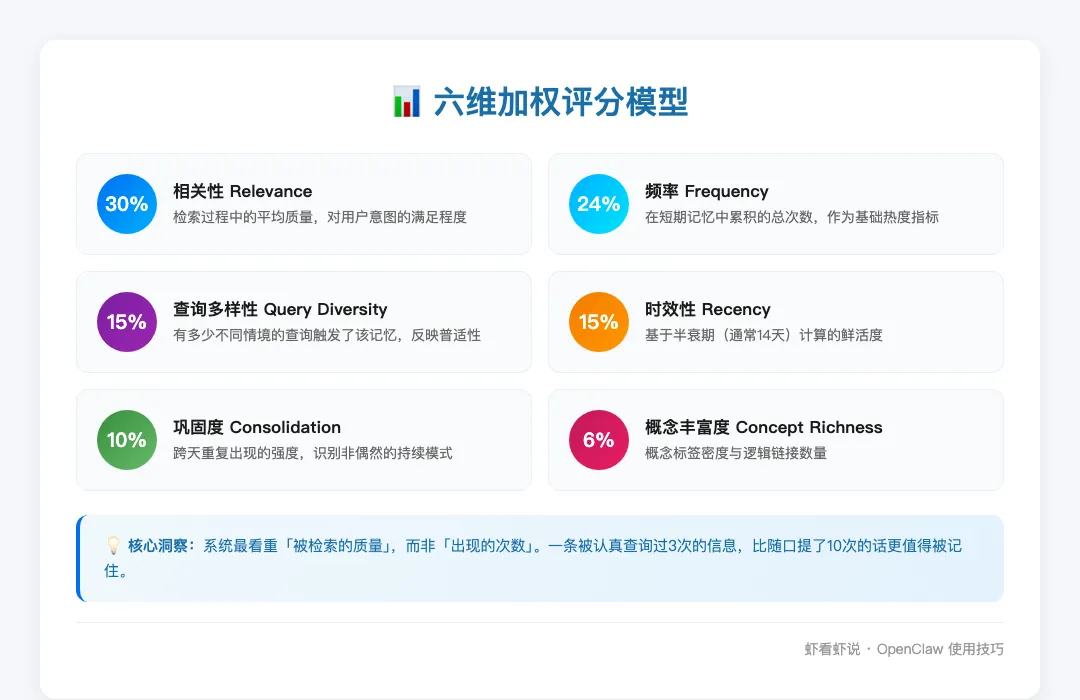
图:六维加权评分体系
在 Deep 阶段,评分进一步细分为六个加权信号:
| 信号 | 权重 | 认知维度 |
|---|---|---|
| 相关性(Relevance) | 30% | 检索过程中的平均质量,对用户意图的满足程度 |
| 频率(Frequency) | 24% | 在短期记忆中累积的总次数,作为基础热度指标 |
| 查询多样性(Query Diversity) | 15% | 有多少不同情境的查询触发了该记忆,反映普适性 |
| 时效性(Recency) | 15% | 基于半衰期(通常14天)计算的鲜活度 |
| 巩固度(Consolidation) | 10% | 跨天重复出现的强度,识别非偶然的持续模式 |
| 概念丰富度(Concept Richness) | 6% | 概念标签密度与逻辑链接数量 |
四、实操指南:3 条命令用起来
理解了原理,来看看怎么动手用。
开启梦境扫描
/dreaming on或在web端手动开启
查看状态和下次扫描时间
/dreaming status手动强制提升某条记忆
如果觉得某条信息很关键,不想等自动评分,可以手动触发:
openclaw memory promote --apply查看某条记忆的决策链路
系统为什么决定记住或不记住某条信息?可以这样查看:
openclaw memory promote-explain "<memory-id>"关键配置参数调优建议
| 参数 | 默认值 | 调优建议 |
|---|---|---|
frequency | 0 3 * * * | 高频用户改为 0 */6 * * *(每6小时一次) |
phases.deep.minScore | 0.8 | 存储过快调高至 0.9;感觉漏掉核心记忆调低至 0.7 |
phases.deep.minRecallCount | 3 | 想过滤偶然提及可以增大;敏感信息可以减小 |
phases.rem.lookbackDays | 7 | 长期项目建议延长至 14 或 30 天 |
五、Token 节省与性能收益
用好梦境功能,不只让 AI 更「懂你」,还有直接的效率收益。根据实测数据,经过记忆系统压缩后:
在 LoCoMo 基准测试中,接入 Cortex Memory 后检索准确度从原生 35.65% 提升至 68.42%,效率提升约 18 倍。
六、安全加固:防的不是你,是恶意插件
梦境功能还有一个容易被忽视的价值维度:安全性。今年早些时候发生的 ClawHavoc 供应链攻击事件中,恶意攻击者上传了 800+ 带有数据窃取脚本的插件。这些插件可能将伪造的「高优先级」记忆条目注入梦境流程,诱导系统将恶意内容固化。
OpenClaw 在 v2026.2.23 版本中进行了系统性加固:HSTS 与 SSPSS 保护、独立后台用户权限(无 sudo 能力)。Q1 2027 路线图中还规划了 WASM 沙盒化。建议定期运行:
openclaw security audit --deep让你的 AI 真正「记住」你
从「失忆助手」到「共同成长的数字伙伴」,差距就在于这套自动化的记忆整理机制。不需要你每天手动总结,AI 会自己在凌晨把一天中有价值的信息提炼出来,层层筛选后总结为长期记忆。下次再聊同一件事,它不会说「我们之前没聊过这个」。
📌 下期预告
本地模型也能跑得动!OpenClaw + Ollama 提效指南——如何用免费本地模型省掉 OpenAI API 费用,同时保护隐私。
