 夜雨聆风
夜雨聆风▼ 做您定制的类似分析,请与刘老师联系。
不做实验,也能发IF10+SCI?正在悄悄流行的文献计量分析,不仅是“论文捷径”,更是“基金申请外挂”!

引言
罕见病是指发生率较低或发病率罕见的一类疾病。目前,全球在罕见病发病率界定标准方面尚未形成统一规范,也尚无公认的统一标准。世界卫生组织(WHO)将患病率在每千人0.65至1之间的疾病界定为罕见病。在2021年发布的《中国罕见病定义研究报告》中,我国提出了罕见病的判定标准:若某疾病满足以下任一条件,即可认定为罕见病——新生儿发病率低于1/10,000,患病率低于1/10,000,或患者总数少于14万。罕见病多由特定基因突变引起,常累及人体多个器官和系统,呈现慢性、进行性和消耗性的疾病发展过程。其特点包括单病种发病率低、患者群体占比较小。这也导致罕见病在诊疗过程中存在诸多问题,如诊断难度大、误诊率高以及缺乏规范化治疗方案等。此外,孤儿药的研发成本高昂,真正成功上市的药物数量有限。
由于中国人口基数庞大,罕见病患者总数预计超过2000万,呈现出“罕见病并不罕见”的局面。这些患者迫切需要有效的诊断与治疗手段。因此,中国学者高度重视罕见病研究,在该领域投入了更多资源与资金,以推动新的发现和治疗策略的产生。这不仅有助于推动政府制定针对罕见病的公共卫生政策,也有利于保障患者的权益。同时,还能够促进全球范围内的罕见病研究合作,提升中国在该领域的学术影响力。
对罕见病相关文献进行系统梳理与总结,概括该领域的研究进展、现状、研究热点及潜在发展趋势,对于引导研究者选择合适的研究方向、推动该领域的长期发展具有积极意义。Web of Science(WOS)和中国知网(CNKI)是国内外最具代表性的核心期刊数据库,能够从不同语言和国家视角揭示科研发展趋势。基于此,本研究采用CiteSpace软件,从多角度对罕见病相关研究开展文献计量分析,并绘制知识图谱,为我国罕见病研究提供有价值的参考。

该文2026年发表于Intractable and Rare Diseases Research
JCR分区:Q2
▼ 想发表自己的文献计量分析论文?点击👇获得更多高质量文献计量分析模板。

(👆经典文献计量分析模板,持续更新中)
以下分为三个方面进行解读。
一. 检索策略
1. 文献检索与数据筛选
以“罕见病”或“少见病”为检索词,在中国知网(CNKI)数据库中进行中文文献检索,时间范围为1985年1月至2024年11月,共检索到中文原始文献4176篇。以“rare disease”或“rare diseases”为检索词,在Web of Science(WOS)数据库中进行英文文献检索,时间范围同样为1985年至2024年,共获得英文原始文献4981篇。
为确保文献检索质量及后续文献计量分析的科学性,对数据进行了筛选处理。首先剔除重复文献,同时排除编辑性材料、书籍章节、来信等类型的文献;此外,还剔除了作者信息不完整或缺失的文献。经过多轮筛选,最终保留中文文献2293篇,英文文献2362篇(见图1)。
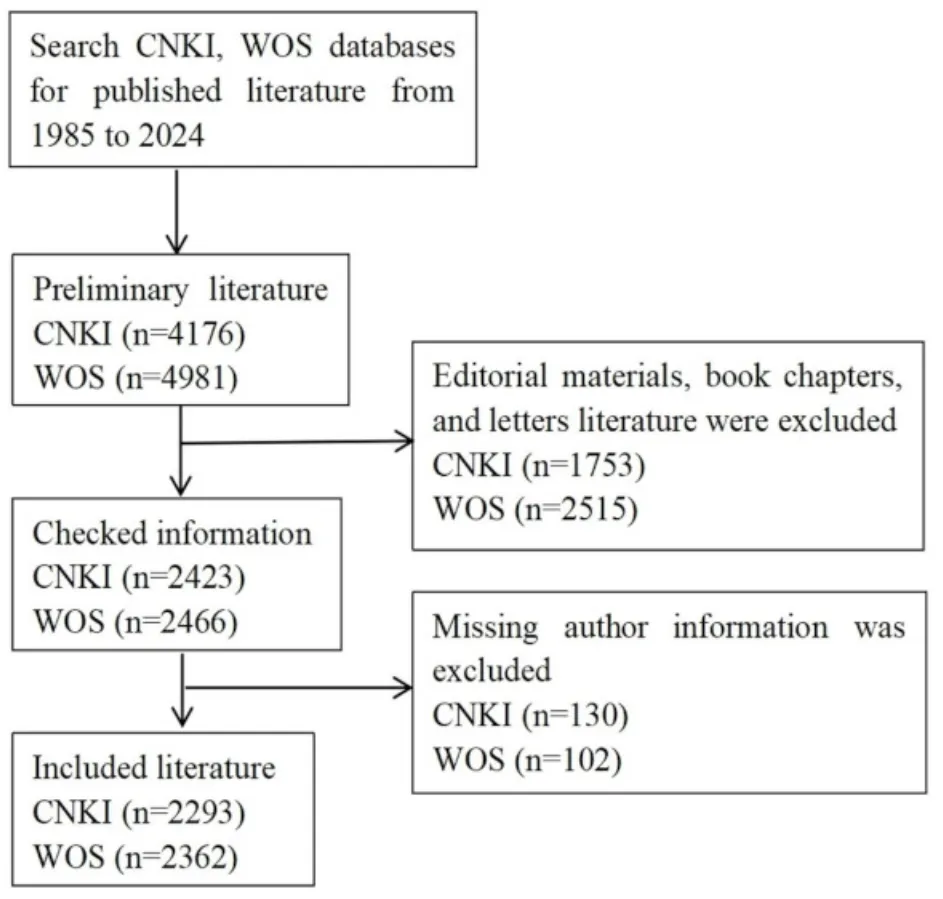
2. 研究方法
将中国知网(CNKI)的检索结果以“Refworks”格式导出,而Web of Science(WOS)的检索结果则以“Plain Text - Full Record and References(纯文本—完整记录与参考文献)”格式导出,数据内容包括作者、研究机构、国家、发表年份及关键词等信息。随后,利用CiteSpace软件对数据进行可视化分析。
参数设置如下:时间切片范围为“1985.1—2024.11”,时间切片间隔设为1年;节点类型选择作者、机构和关键词进行分析。网络连接强度采用余弦相似度,并使用Pathfinder算法对网络进行剪枝处理。
二. 主要结果
1. 发文量统计分析
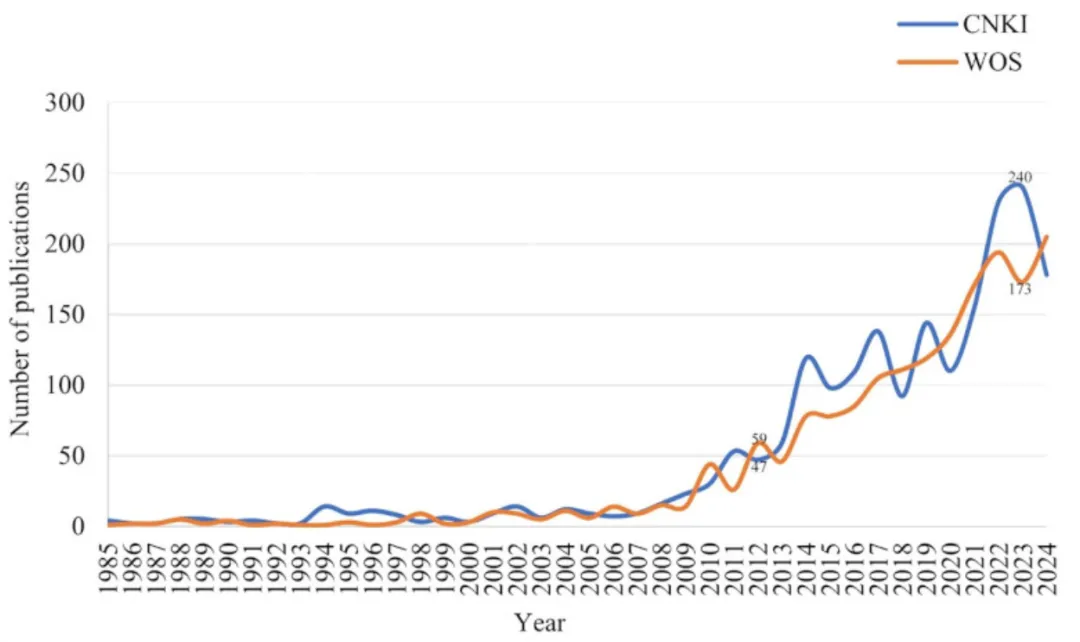
通过对年度发文量的统计分析,可以清晰了解我国及其他国家某一研究领域的发展现状及未来趋势。罕见病研究领域的年度发文量总体呈现波动上升趋势,自2012年以来,这一增长趋势愈发明显。根据中国知网(CNKI)数据库的数据,发文量由2012年的47篇增长至2023年的240篇;同样,Web of Science(WOS)数据库显示,2012年至2023年间发文量增加了174篇。尽管个别年份存在小幅波动,但整体增长趋势十分显著。
需要说明的是,2024年的数据尚不完整,由于未纳入2024年11月之后的文献,可能导致当年发文量相对偏低。总体来看,过去十年中,罕见病已成为一个重要的研究领域,当前学者仍需持续加大对该领域的关注与投入(见图2)。
2. 国家/地区分布
本研究利用CiteSpace绘制了国家/地区共现图谱(见图3)。
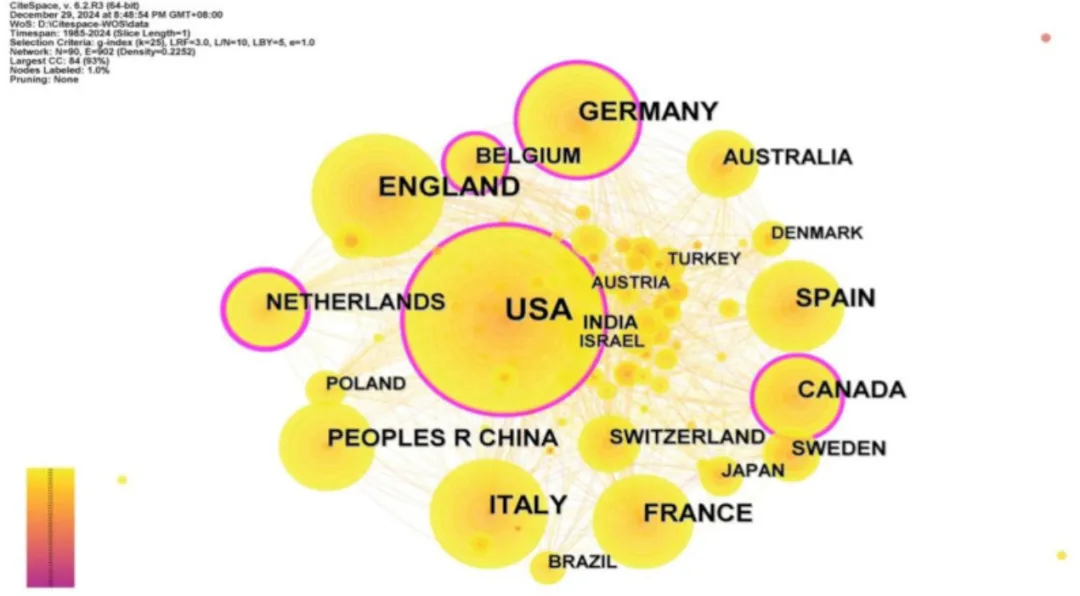
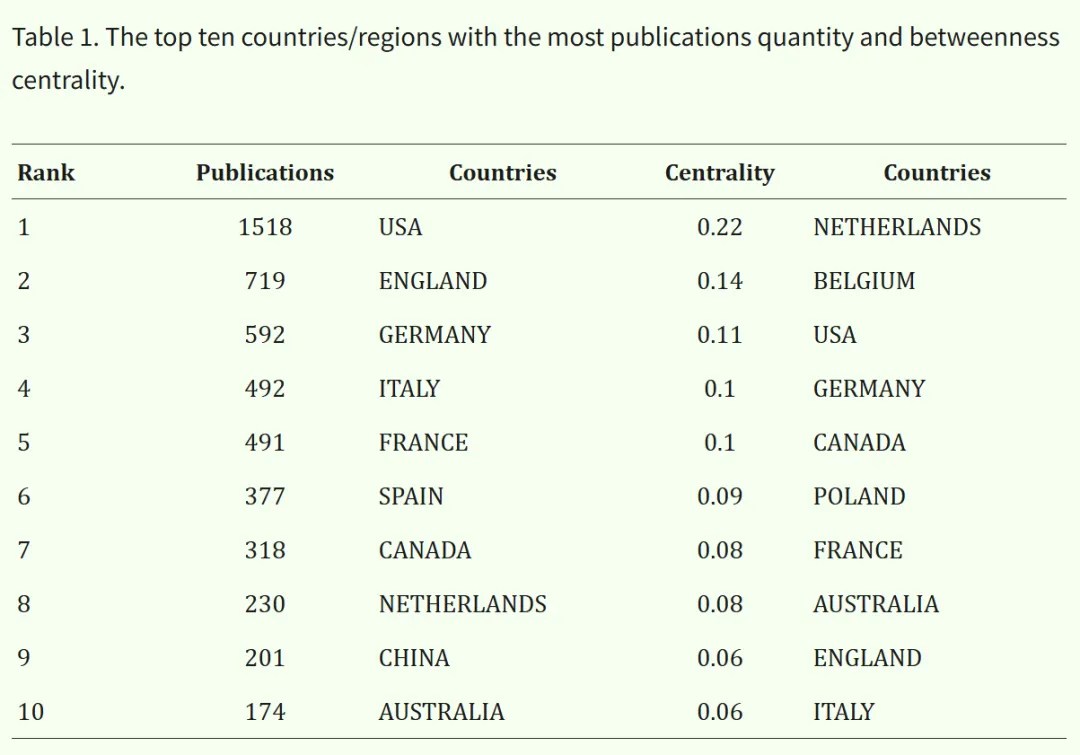
该图谱包含90个节点和902条连线,网络密度为0.2252,表明共有90个国家/地区参与了罕见病研究领域。在Web of Science(WOS)数据库中,发文量最多的国家为美国,共1518篇;其次为英国(719篇),随后依次为意大利(592篇)和德国(492篇),中国的排名相对靠后(201篇)。排名第一的美国与其他国家之间存在明显差距,说明美国在罕见病研究领域占据核心地位(见表1)。
在共现图中,紫色节点表示中介中心性大于0.1的国家,其中荷兰(0.22)、比利时(0.14)、德国(0.10)、加拿大(0.10)和美国(0.11)在该领域中发挥着“桥梁”作用。综合发文量和中介中心性来看,美国和英国在罕见病药物警戒研究领域贡献最为突出。
从期刊分布角度来看,美国及其他欧洲发达国家占据主导地位(见表2)。
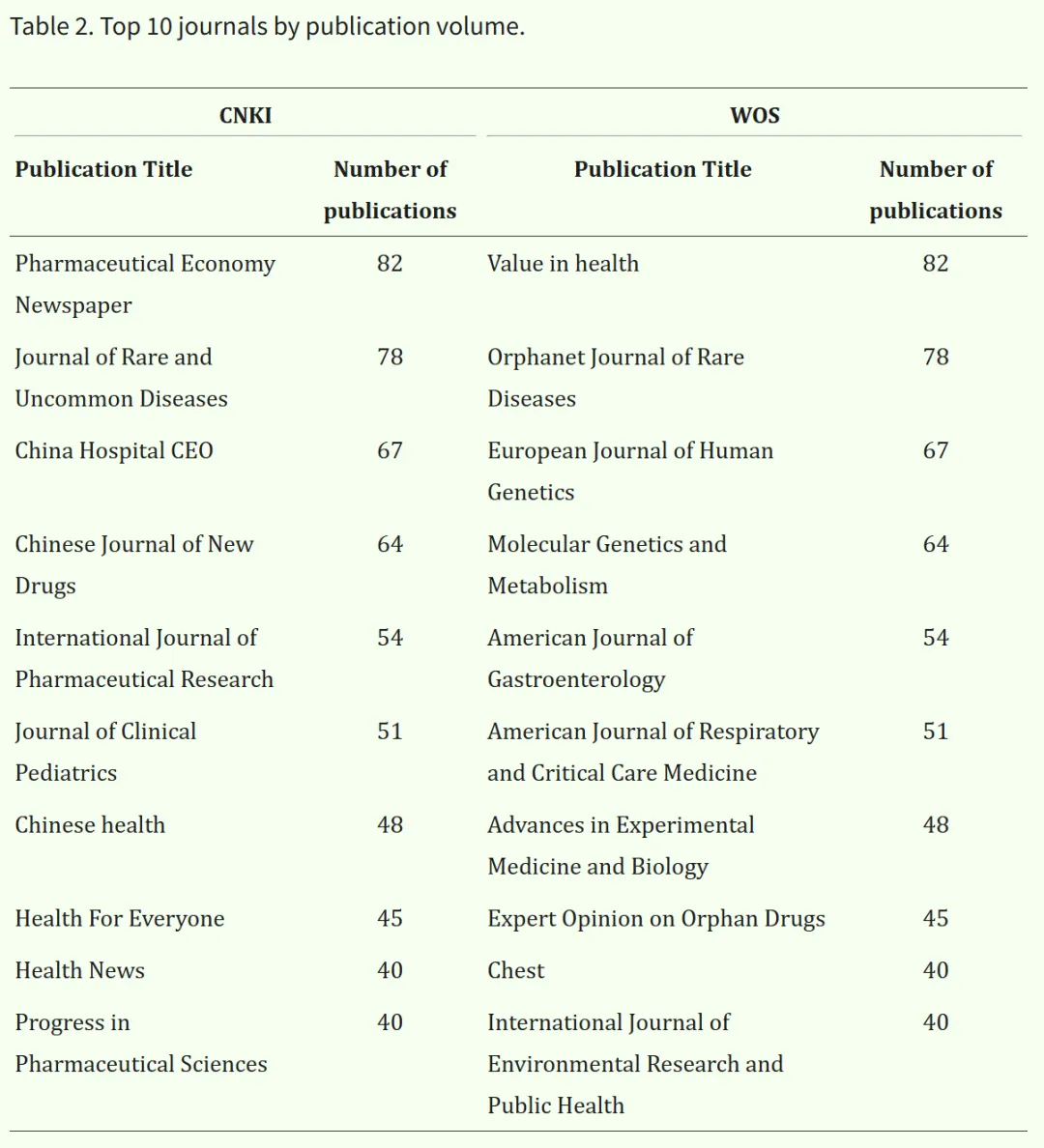
3. 机构分析
采用CiteSpace 6.2.R3软件对研究机构进行分析,绘制了发文机构分布图(见图4 A和B)。图中节点代表发文机构,节点之间的连线表示不同机构之间的合作关系,连线越粗表示合作程度越高。中国知网(CNKI)数据库中的机构可视化图谱共包含360个节点和117条连线,网络密度为0.0018。我国发文量最多的机构为中国医学科学院北京协和医院,共发表162篇文献(见表3)。
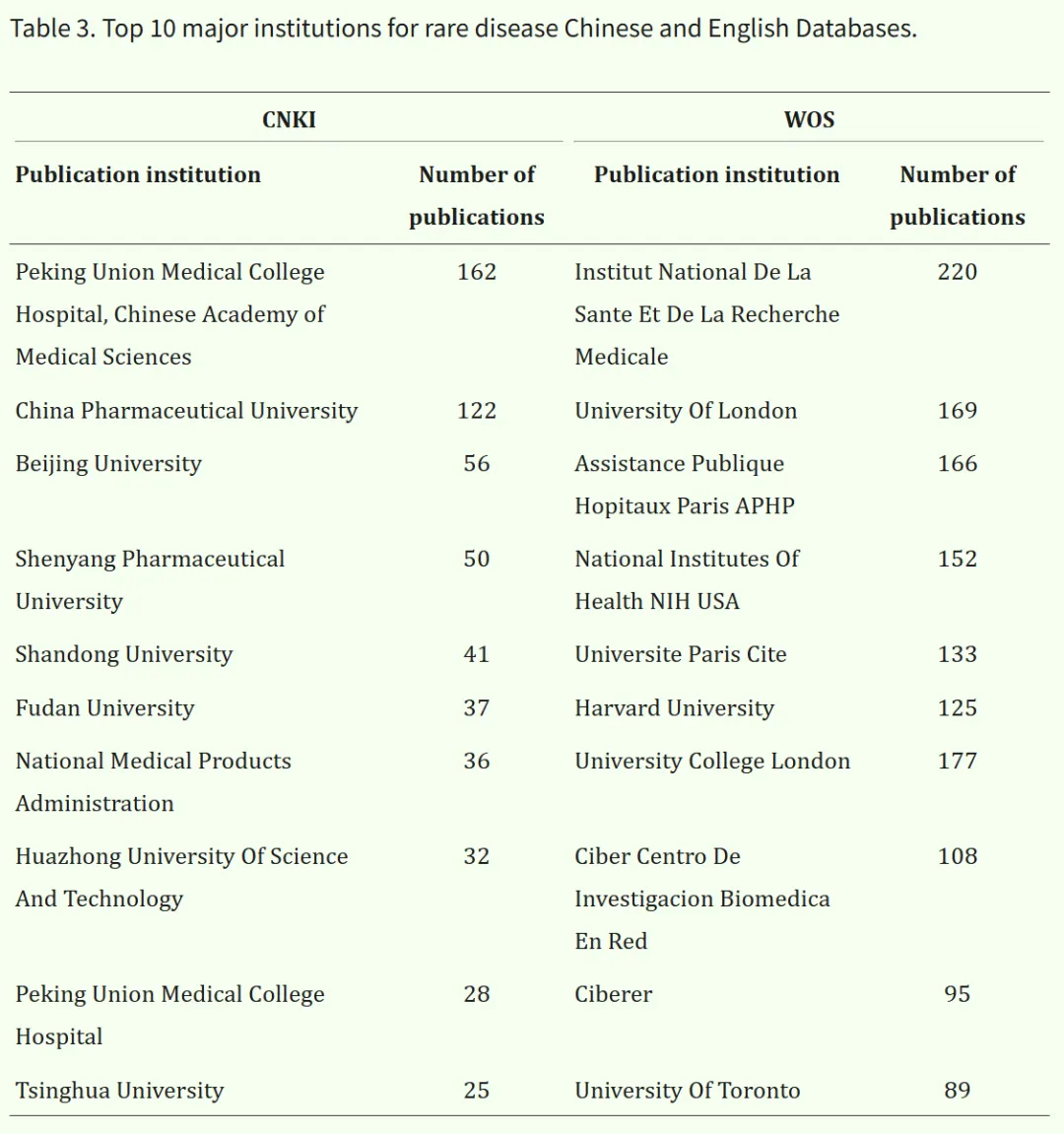
作为我国顶尖的医疗与科研中心之一,该机构与中国医学科学院基础医学研究所、清华大学等知名机构合作,共同建立了国家疑难重症及罕见病重点实验室,以及淋巴管肌瘤病/结节性硬化症复合体罕见病专项基金,推动了我国罕见病研究的发展。
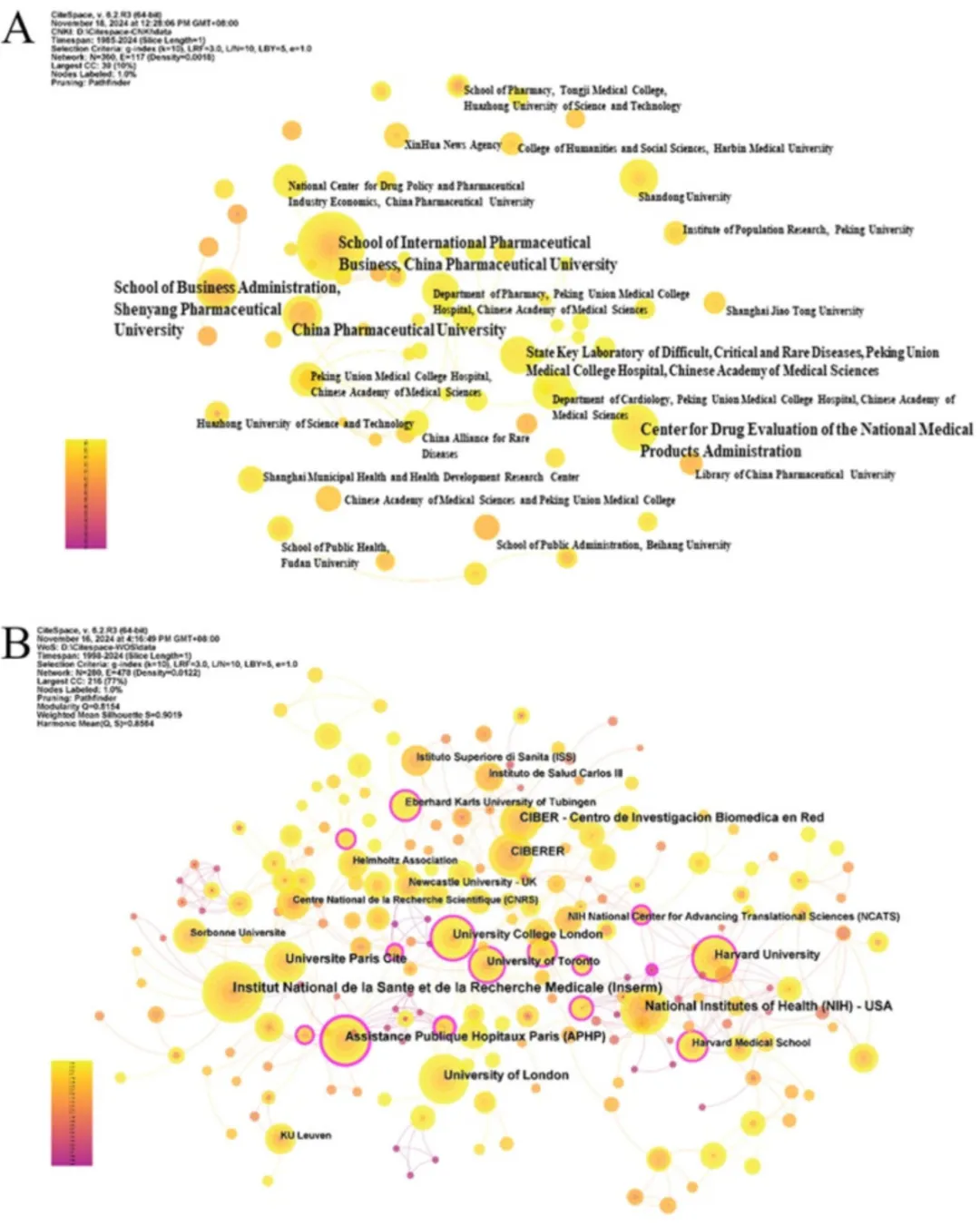
相比之下,Web of Science(WOS)数据库中的机构可视化图谱包含280个节点和478条连线,网络密度为0.0122。国外发文量最多的机构为法国国家健康与医学研究院(National Institute of Health and Medical Research)。该机构成立于1964年,拥有丰富的科研资源和一流的研究团队。
上述图谱显示,罕见病研究领域在机构合作方面存在明显差异:国外机构之间联系紧密、合作程度较高,而我国研究机构之间相对较为分散,合作较少。这一差异表明,有必要进一步加强该领域的国际合作与交流。
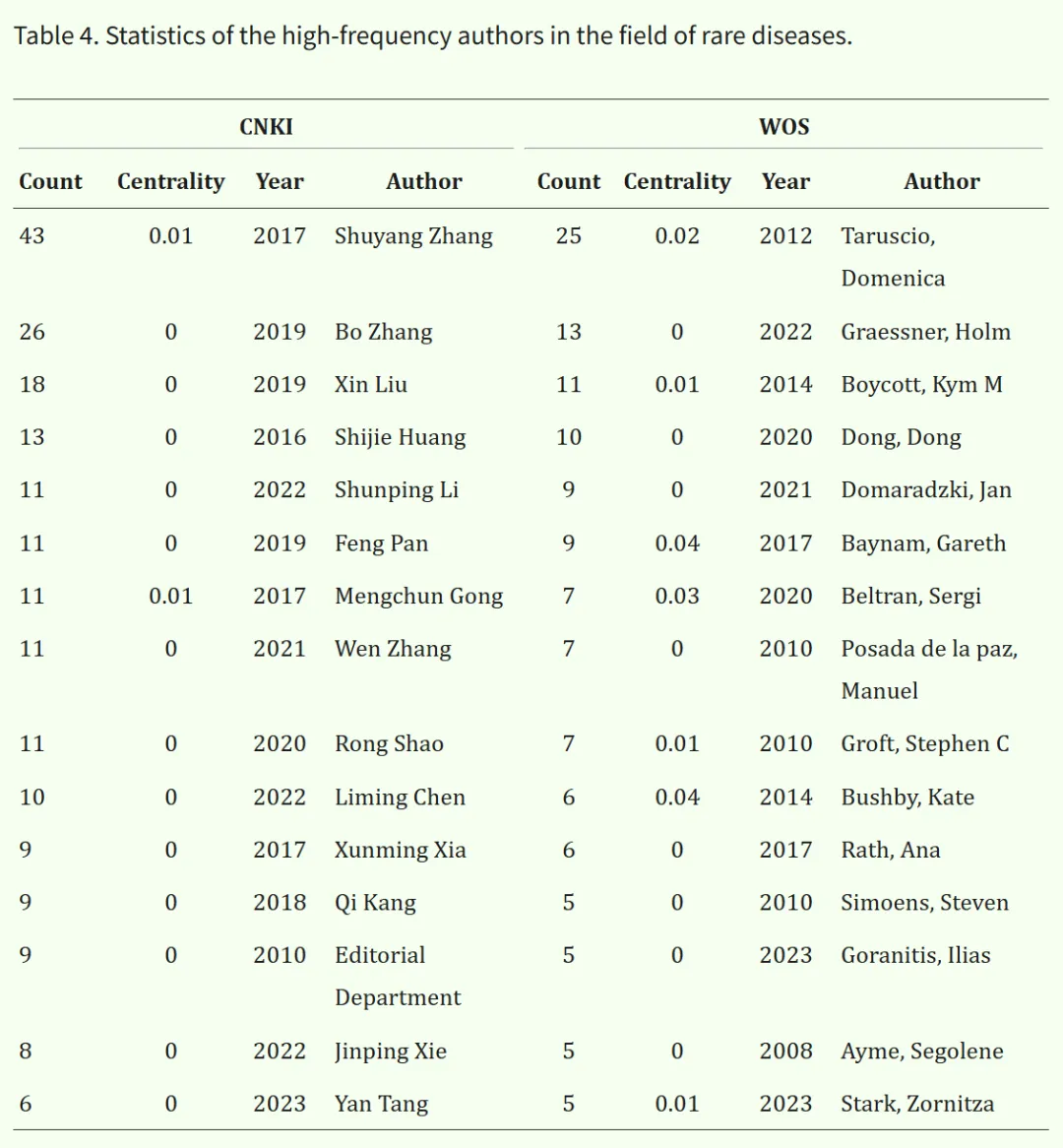
4. 作者分析
作者共现图能够直观展示该领域的核心研究者及其合作强度。图中每个节点代表一位作者,作者之间的连线表示合作关系。节点与连线的颜色用于表示合作起始时间,从1985年的棕红色逐渐过渡至2024年的黄色。节点的大小与作者的合作者数量成正比,而节点圆圈的大小则反映该作者的发文总量。节点之间的连线则体现作者之间的合作程度。
通过该图谱可以识别出领域内的合作团队。在中文文献中,主要的合作团队以张抒扬和张波为代表,共包含436个节点、308条连线,网络密度为0.0032(见图5A)。该团队主要聚焦我国罕见病领域,开展罕见病发病机制及新药研发相关研究。在英文文献中,Taruscio D、Graessner H 和 Boycott KM 为发文量排名前三的作者,这三位学者构成了合作网络的核心,其图谱包含413个节点、394条连线,网络密度为0.0046(见图5B)。
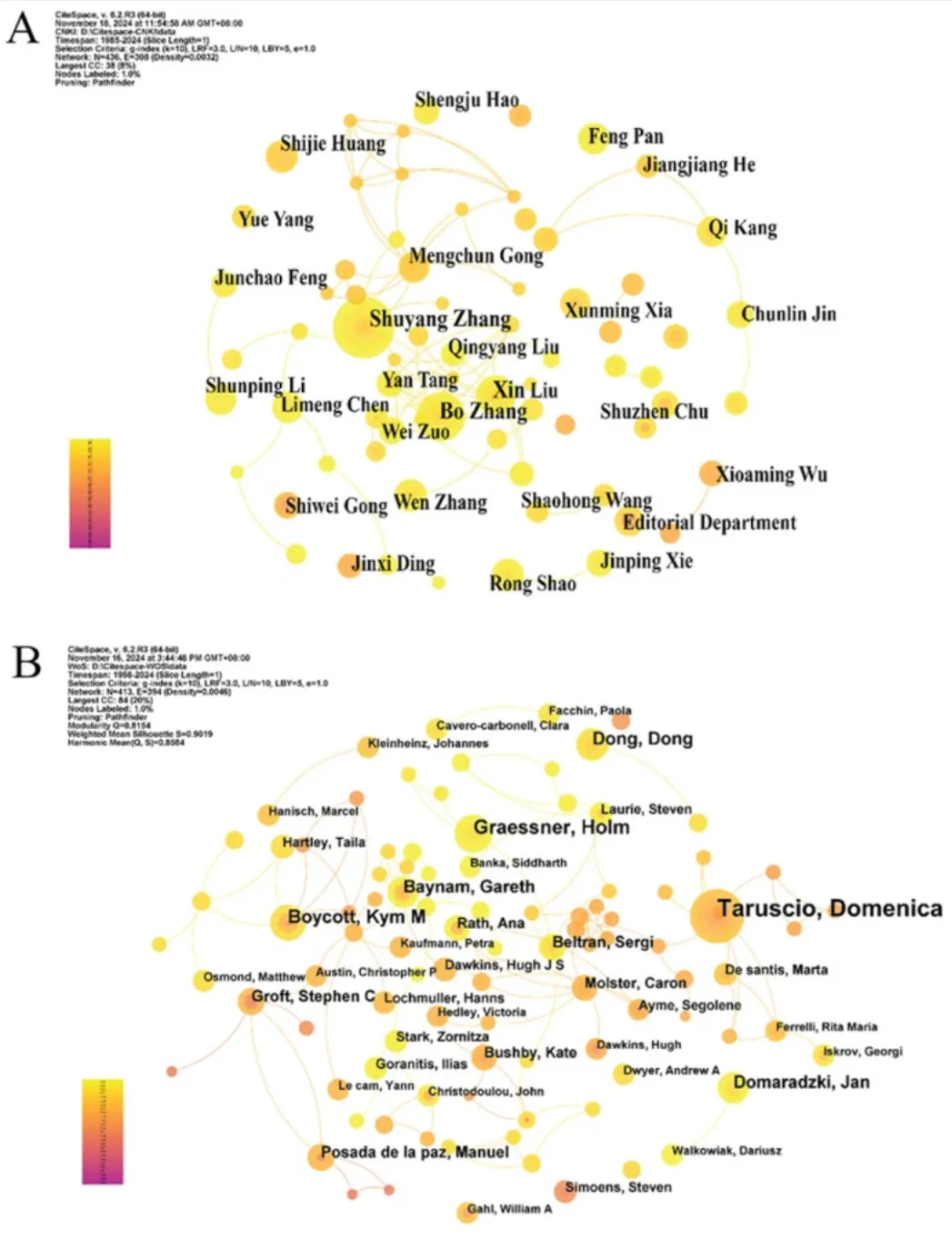
上述三位专家均在罕见病研究领域作出了重要贡献。发文频次排名前十的作者见表4。
5. 关键词分析
5.1 关键词共现分析
在CiteSpace软件中选择Pathfinder算法,并结合合并网络与分区网络剪枝处理,对Web of Science(WOS)和中国知网(CNKI)数据库中的文献关键词分别进行分析,从而得到罕见病关键词共现图谱(见图6 A和B)。关键词是对文献核心主题和内容的高度概括,该图谱反映了该领域关键词的出现频率及研究热点。图中方形节点的大小表示关键词出现的频次,方块越大,说明该关键词在研究中出现频率越高,越具有核心地位。
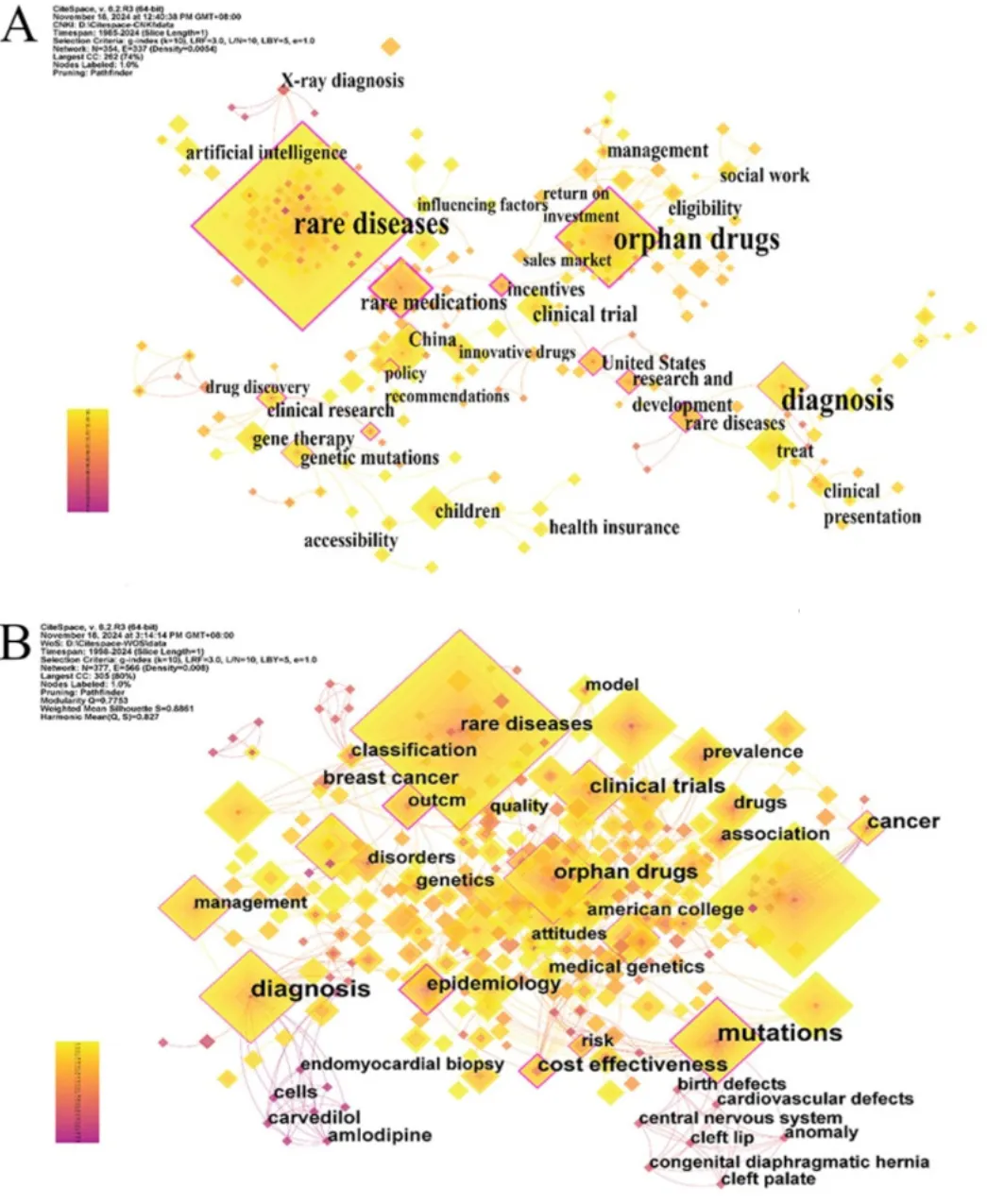
CNKI数据库结果显示,我国排名前五的高频关键词分别为:罕见病(675次)、孤儿药(164次)、罕用药(61次)、诊断(45次)和医疗保险(40次)。WOS数据库中排名前五的高频关键词为:rare diseases(449次)、rare disease(282次)、diagnosis(110次)、orphan drugs(92次)以及children(87次)。可以看出,孤儿药、诊断方法及治疗策略是国内外罕见病研究的共同关注重点。
中介中心性是衡量关键词重要性的关键指标之一,中心性大于0.1的节点被视为关键节点。根据中心性从高到低排序,具体结果见表5。CNKI数据库中中心性最高的关键词为“罕用药”,其次为“病因”,研究重点主要集中在孤儿药的开发方面;而WOS数据库中中心性最高的关键词为“epidemiology(流行病学)”,其次为“mutations(突变)”,研究重点更多集中在罕见病的基因治疗领域。这表明我国与国际在罕见病研究方向上存在一定差异。
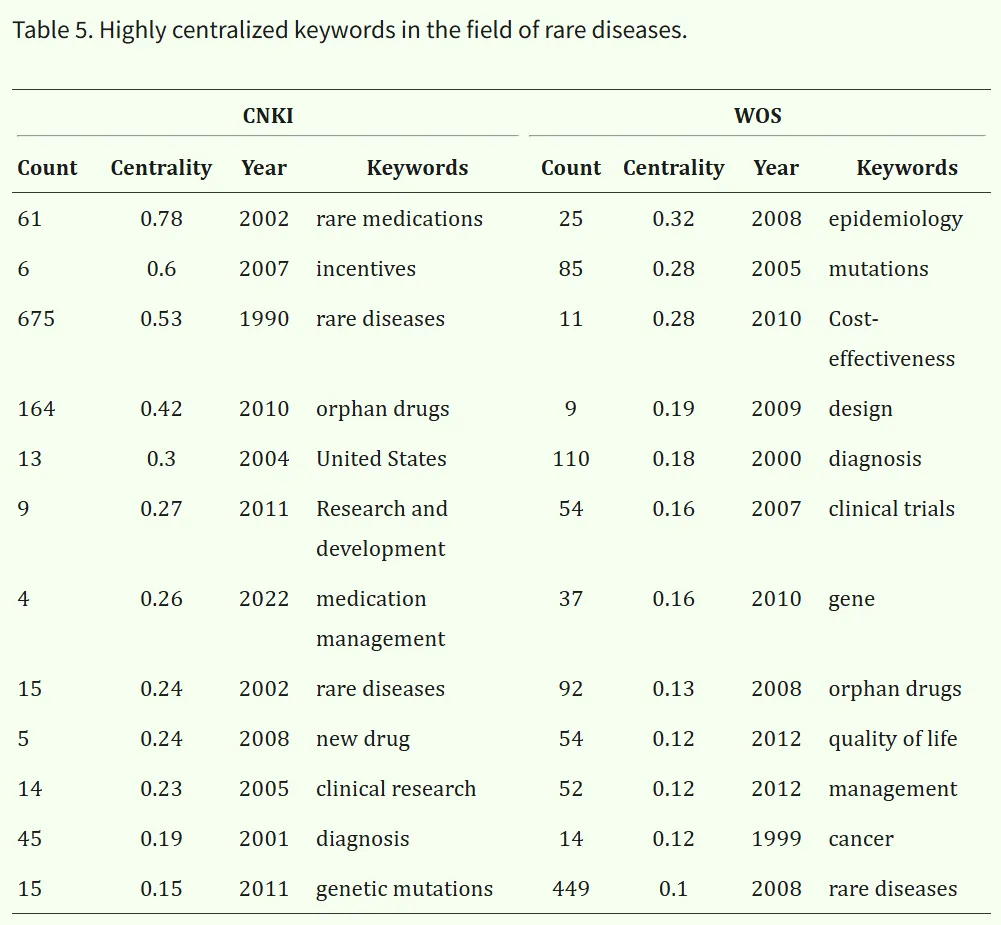
5.2 关键词聚类分析
本研究采用谱聚类算法中的自然对数似然比(LLR)方法进行关键词聚类分析。模块度值(modularity Q值)用于衡量聚类网络结构的稳定性,一般认为当Q值大于0.3时,说明聚类效果显著。平均轮廓值(加权平均轮廓系数,S值)反映聚类内部节点的相似程度,其取值范围通常为0.5至1.0,临界值为0.5。S值越高,表示类内相似性越强,聚类结果越合理。
本研究中,CNKI数据库聚类模块的Q值为0.8561,平均轮廓值S为0.984,表明中文文献的关键词聚类清晰、主题划分明确(图7A)。WOS数据库聚类模块的Q值为0.8154,平均轮廓值S为0.9019(图7B),同样显示出显著的聚类结构以及较高的聚类准确性和合理性。这表明,无论是在中国还是在全球范围内,罕见病的临床治疗与孤儿药的研发都是重要的研究热点。
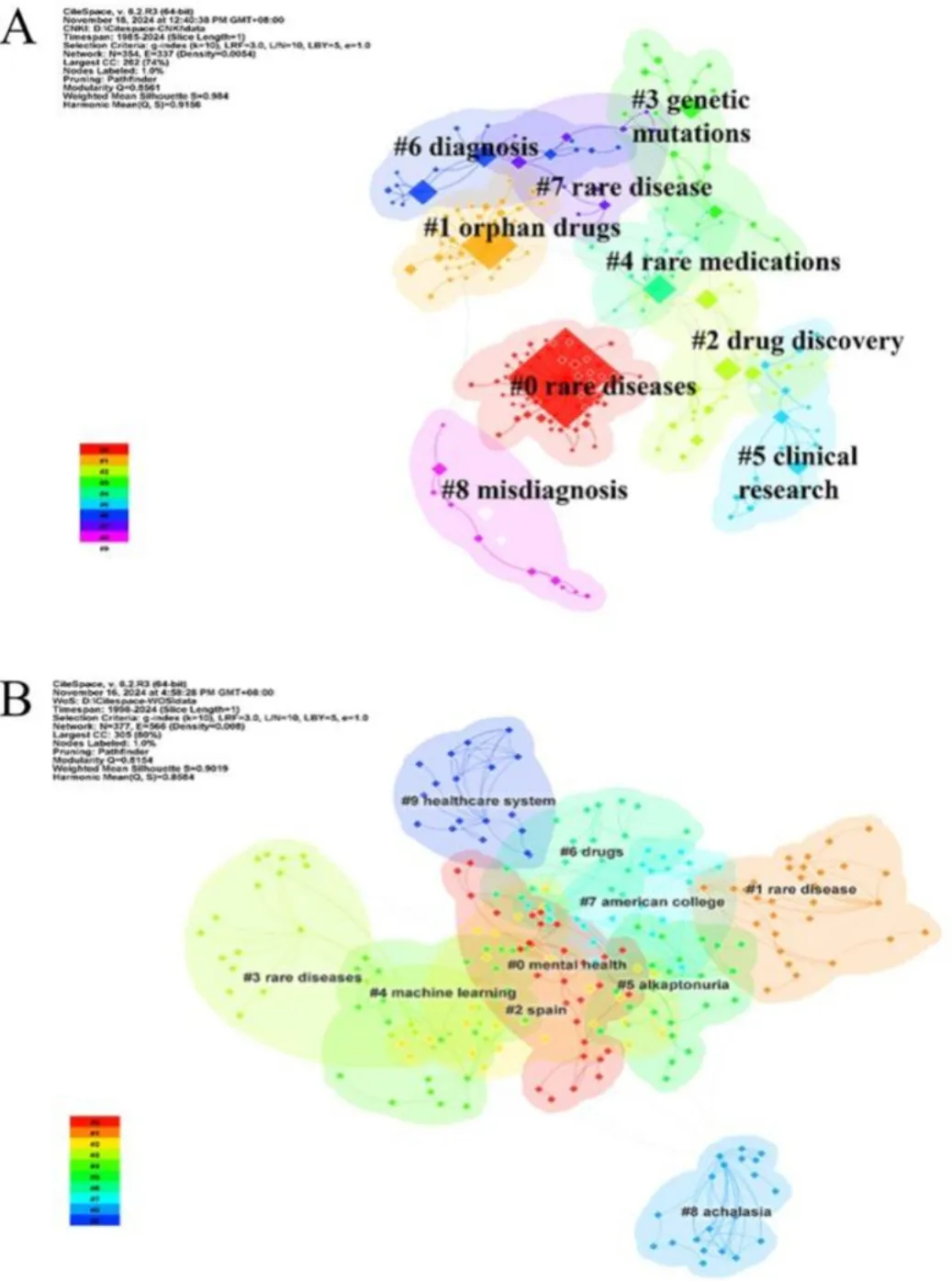
5.3 关键词突现分析
突现词是指在特定时间段内出现频率显著上升的关键词,能够反映该时期的研究热点及发展趋势。本研究采用 CiteSpace 6.2.R3 软件对全球罕见病研究领域的突现关键词进行可视化分析,以探讨该领域的研究动态与发展方向(图8A 和 B)。突现强度用于衡量关键词的重要性,表示该关键词在短时间内被大量引用。在可视化图中,浅蓝色带表示尚未突现的关键词,深蓝色带表示已经出现的关键词,而红色带则表示在对应时间段内被频繁引用的关键词。
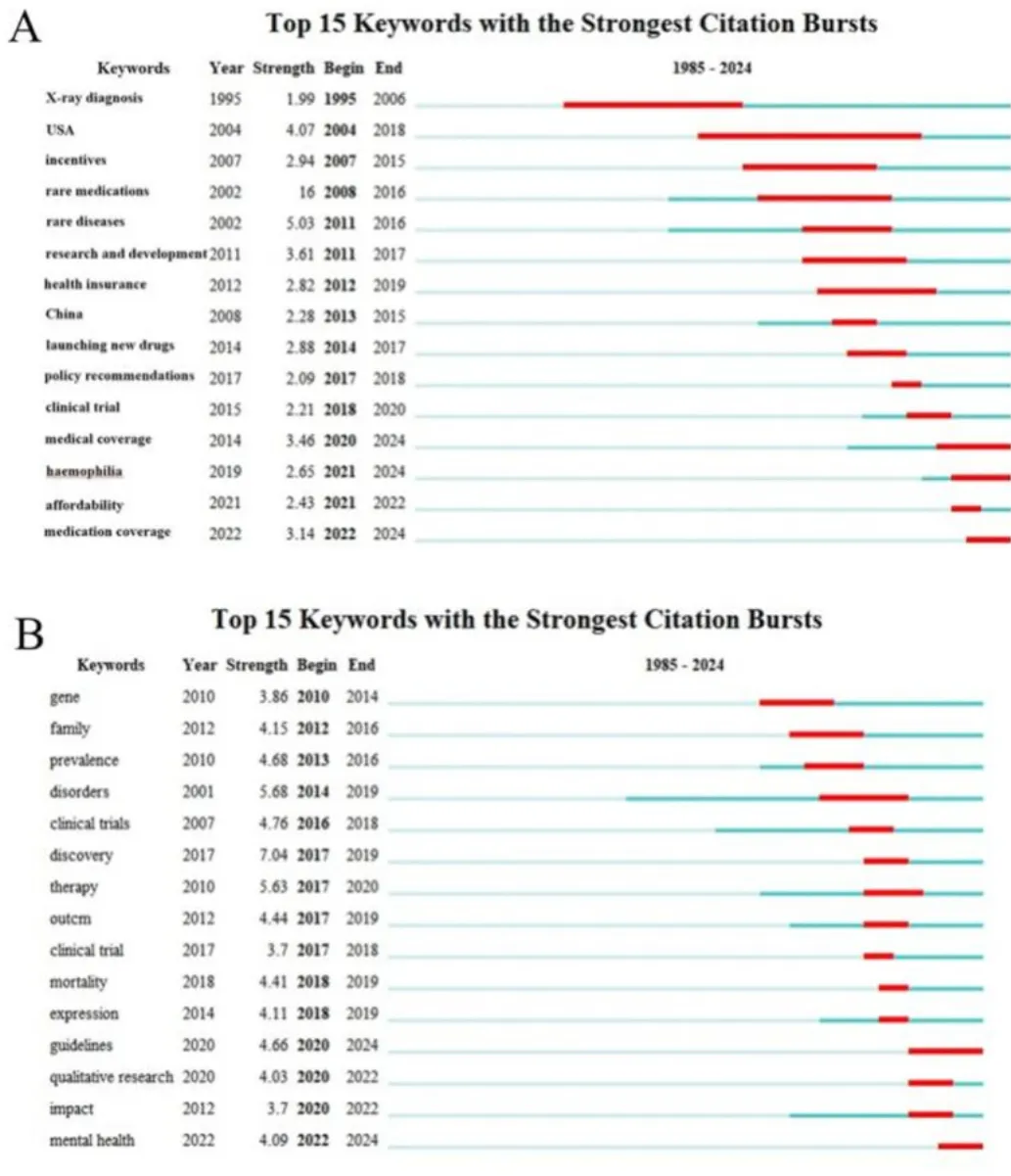
在 CNKI 数据库中,罕见病研究的突现关键词主要集中在罕见药物、罕见病以及孤儿药等方面。值得注意的是,自 2020 年以来,研究人员对罕见病医疗保障体系的关注逐渐增加,表明学界开始更加重视相关治疗的医疗保险问题。
在 WOS 数据库中,罕见病研究的重点主要集中于临床试验、定性研究、患者报告结局、欧洲参考网络以及孤儿药等方面。两个数据库均表明,孤儿药的研发以及遗传诊断是全球范围内罕见病研究的共同关键领域。此外,国际上还广泛关注罕见病的分子机制以及罕见病人群的健康管理问题。
6. 参考文献分析6.1 共被引文献分析
高被引文献能够反映某一研究领域的热点问题。通过对共被引文献的分析,可以识别特定时间范围内研究主题的动态变化。基于引文频次分析,筛选出被引频次排名前10的英文文献(表6,此处只显示原文表格中的部分)。较高的被引频次通常表明这些文献在该领域具有基础性或广泛影响力,有助于揭示关键研究进展和重要成果。
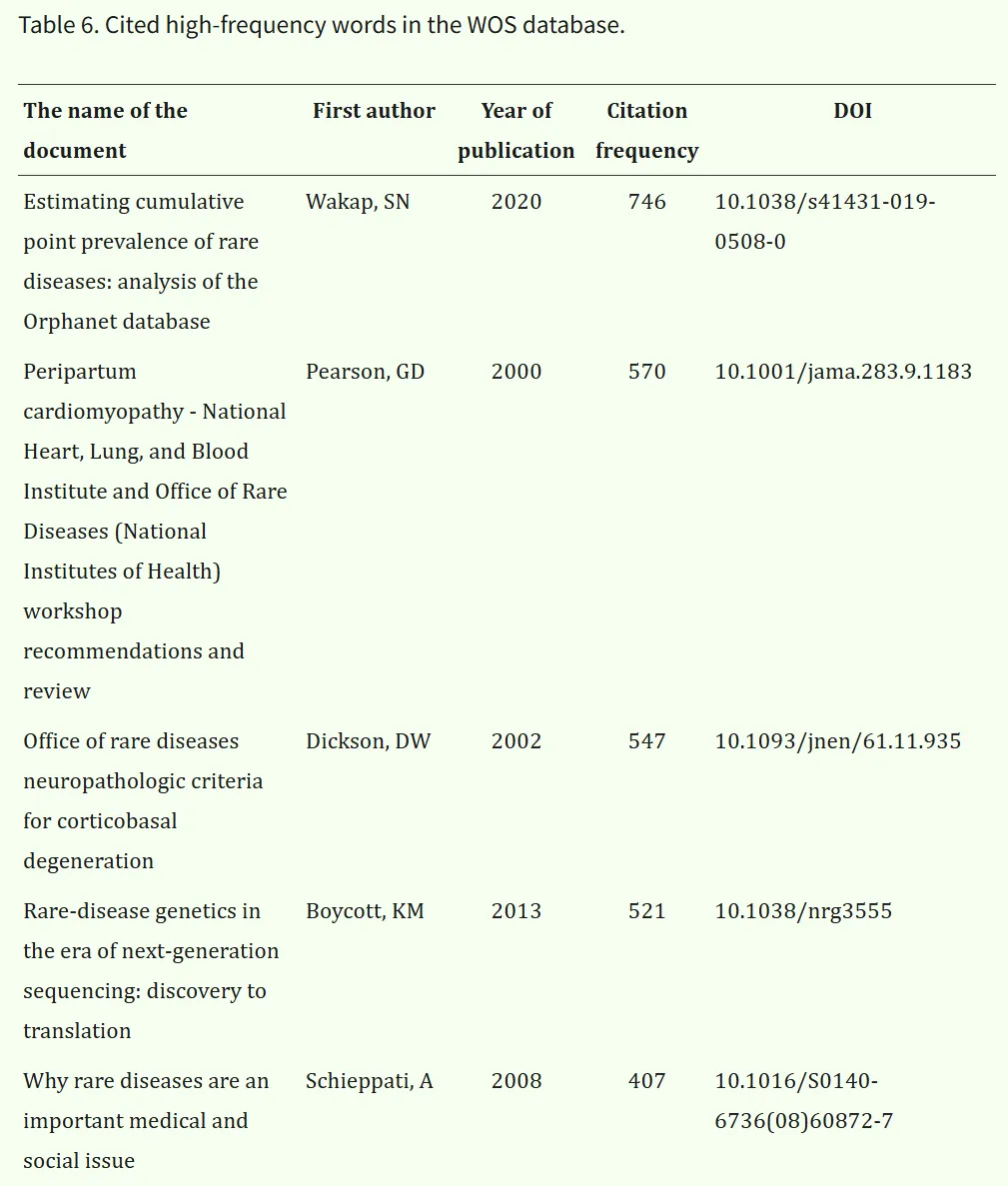
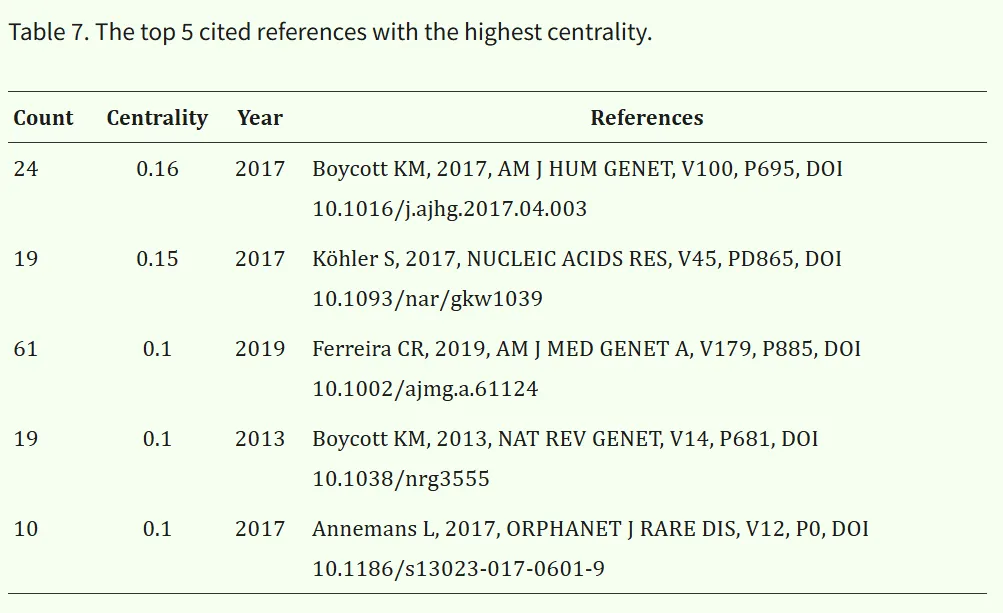
相关研究对美国医学遗传学与基因组学学会(ACMG)与分子病理学协会(AMP)联合制定的序列变异解读标准与指南进行了阐释,并探讨了蛋白编码基因在疾病筛查中的有效性。Boycott KM 等人发表的文章《Rare-disease genetics in the era of next-generation sequencing: discovery to translation》不仅具有较高的被引频次,同时也具有较高的中介中心性(表7)。由此可以推断,遗传技术、遗传医学以及人类表型本体(HPO)模型在罕见病研究领域具有重要的影响力和关键地位。
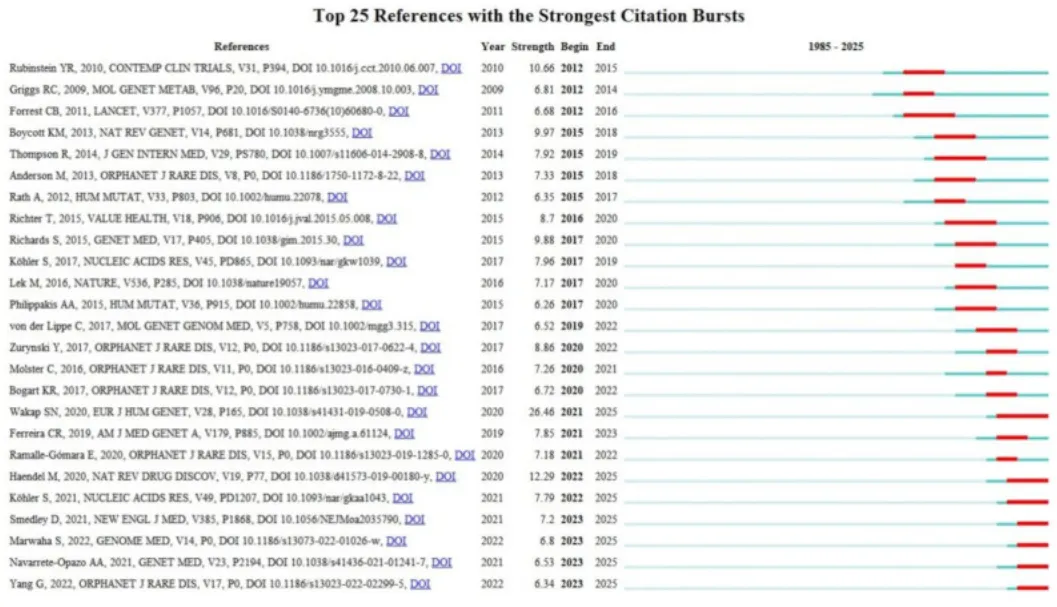
6.2 参考文献突现分析
当某一参考文献在特定时间段内被大量集中引用时,其突现值较高,这通常表明该文献的研究成果代表了该领域的创新发现或前沿方向。图9展示了突现强度排名前25位的参考文献及其相关信息。其中,有3篇文献的突现强度超过10,分别为 Wakap SN 等人的文献(突现强度为26.46)、Haendel M 等人的文献(突现强度为12.29)以及 Betts 等人的文献(突现强度为10.66)。
三. 讨论
罕见病研究领域已引起学界的广泛关注,并取得了显著成果。本研究识别了高产出的国家、机构和作者,这些主体已建立起具有代表性的研究团队,内部合作紧密,为后续研究提供了坚实的学术支持。同时,我们还确定了被引次数最高的十位影响力作者以及被共引最多的期刊,其研究成果已获得学术界的广泛认可。
1. CNKI 与 WOS 数据库的比较
从发文数量来看,美国遥遥领先,其发表量约为中国的7.5倍。尽管中国的论文产出仍低于部分欧洲国家,但自2012年以来,CNKI数据库中关于罕见病的研究论文数量持续增长。这一趋势反映出中国对罕见病研究的重视程度不断提升,同时研究质量仍有进一步提升空间。
美国和欧盟等经济发达国家之所以具备较强的科研能力,主要源于多方面因素。例如,美国是全球最早制定罕见病相关专门法律的国家,建立了完善的诊断、治疗、研发及孤儿药开发体系,并配套创新激励机制。此外,这些领域还获得了大量资金支持。
从研究重点来看,基于CNKI关键词频率和聚类结果,中国期刊更关注罕见病药物,而国外期刊则更侧重基因突变与治疗研究。这一差异可能源于政策背景不同。美国自1983年《孤儿药法案》出台后,持续完善相关政策体系,如实施细则及《罕见病法案》,逐步构建覆盖药物全生命周期的激励机制。欧盟也于1999年建立《孤儿药条例》,并在2000年成立孤儿药委员会,对相关申请进行评估。
这些国家在罕见病治疗研发方面具有主导地位,广泛开展基因研究、基因治疗及发病机制探索,为新药开发奠定基础。相比之下,中国虽已出台加快审批、减税、纳入医保等政策,但罕见病药物仍以进口为主,与欧美国家仍存在差距。因此,中国仍需进一步完善政策体系,推动罕见病防治水平提升。
2. 罕见病领域的研究热点
2.1 孤儿药研发
罕见病又称“孤儿病”,相应治疗药物被称为“孤儿药”。由于疾病复杂多样、认知有限以及患者群体较小,孤儿药研发具有高难度、周期长和风险大的特点,这也成为罕见病治疗的主要障碍。
目前全球已识别超过7000种罕见病,但仅约400种有治疗方法,凸显了孤儿药研发的紧迫性。在高突现被引文献中,约三分之一涉及孤儿药研发。
美国在该领域起步较早,《孤儿药法案》不仅明确罕见病定义,还提供研发资助、税收优惠及上市后7年市场独占期。这些激励机制显著降低了研发风险。欧盟则提供长达10年的市场独占期及多种财政支持。
近年来,孤儿药在FDA批准药物中占比超过35%。基因治疗、抗体治疗、酶替代疗法及药物再利用等技术成为研究热点。新技术的发展为罕见病治疗带来了新的希望。
2.2 基因组学与遗传学
基因组研究通过全基因组或外显子测序识别与罕见病相关的基因变异,并用于疾病诊断、机制研究及精准治疗。CNKI和WOS中,“基因”和“突变”均为高频关键词。
基因治疗已在多种罕见病(如Wiskott-Aldrich综合征、Fanconi贫血)中取得进展。2017年首批基因治疗药物上市,标志着个体化治疗时代的到来。目前全球已有40多种基因治疗药物获批。
2024年,美国研究团队对8000多个疑似单基因罕见病家庭进行测序,发现基因组测序可将诊断率提高8%。中国也高度重视该领域发展,例如2022年启动UPWARDS项目,目前已有514家医院参与,检测人数超过10万。
2.3 医疗保险保障
罕见病已成为全球公共卫生的重要挑战。由于患者少、研发成本高,制药企业积极性不足,因此各国纷纷通过立法保障患者权益。
美国通过完善的政策体系和资金支持,缩短孤儿药审批时间并降低费用。欧盟通过持续完善法规,构建了系统化管理体系。
中国在国际上的相关研究影响力较低,但在政策层面高度重视。例如建立罕见病目录、纳入医保、推进药品谈判降价、构建多层次保障体系等。
2018年发布的首批目录包含121种罕见病,2023年第二批新增86种,标志着中国在罕见病保障体系建设方面取得重要进展。
2.4 人工智能与大数据
Orphanet数据库是国际权威罕见病数据库,提供高质量数据支持。人类表型本体(HPO)也成为重要标准工具,有助于全球数据共享和疾病研究。
人工智能的发展使得通过大数据分析基因与疾病关系成为可能。例如EVA工具可通过外显子测序识别致病突变,已应用于多种罕见病研究。
AI在数据整合和分析方面具有巨大潜力,有助于解决诊断率低、患者分散等问题。
编者按
随着全球对罕见病问题关注度的持续提升,相关研究已从早期的零散探索逐步走向系统化与协同化发展。从本研究的分析可以看出,发达国家依托完善的政策体系、稳定的资金支持以及成熟的科研平台,在孤儿药研发、基因治疗及疾病机制研究等方面已形成明显优势。而中国等新兴研究力量虽起步较晚,但在政策推动、研究投入和临床网络建设方面正加速追赶,展现出良好的发展潜力。
当前罕见病研究呈现出几个值得关注的趋势:其一,孤儿药研发仍是核心驱动力,但需在激励机制与市场可及性之间取得平衡;其二,基因组学与精准医学正深刻改变疾病诊断与治疗模式,推动从“症状治疗”向“机制干预”转变;其三,医疗保障体系逐渐成为影响研究转化与患者获益的重要因素;其四,人工智能与大数据的融合应用,为解决罕见病“数据稀缺”与“诊断困难”等瓶颈提供了新路径。
基于上述发现,罕见病研究可获得以下启示:首先,应进一步强化跨学科与国际合作,构建开放共享的数据与研究网络;其次,完善政策激励与监管体系,促进从基础研究到临床转化的全链条发展;再次,加强本土创新能力,减少对进口药物的依赖;最后,以患者为中心,推动医疗保障、伦理规范与技术进步的协同发展。
未来,罕见病研究不仅是医学问题,更是公共卫生与社会治理的重要议题。唯有通过科技创新、制度完善与全球协作的共同推进,方能真正改善罕见病患者的诊疗现状与生活质量。
原文链接:
广而告之:
如果您也需要对自己公司的产品或者对自己研究的领域做系统梳理,可以找美国Healsan恒祥医学科技做文献计量分析。并可同时获赠五个仅Healsan™大数据才有的福利:
文献检索老师参与学员选题的文献检索; 完成分析后,免费使用SCI论文神器10天,以完成论文撰写; 作者撰写好之后,获得免费查重; 作者投稿前,获得免费的选刊服务。

(点击👆,获得持续的医学大数据分析报告)
 |  |
 |  |
 |  |
 |  |
(点击👆图片,进入自己感兴趣的专辑。或点击“资源”,浏览本公众号所有资源)
