 夜雨聆风
夜雨聆风不是炫技,是实战。这篇文章告诉你,AI 开发工具真正的价值,是把你变成一个能独立交付复杂系统的人。
先说结论
三件事你看完这篇文章就能复现:
用 OpenCode 的「PPT 专家 + 内容创作专家」组合,一句话生成专业 PPT 连上 MySQL 8.0,从数据库读取动态数据自动导出 PPT 和 PDF 遇到「PDF 中文字不显示」这个天坑,如何用多模态模型快速定位根因
不吹概念,直接上实战过程,包括失败的部分。
![生成的 PPT 和 PDF 效果展示,支持广告宣传]






一、OpenCode 到底是什么?为什么值得关注
很多人对 AI 编程工具的理解还停留在「帮我写段代码」。
OpenCode 不一样,它的核心逻辑是代理系统(Agent System)——不同的专家代理负责不同领域,你描述目标,代理自己拆解任务、调工具、执行、反思、修正。
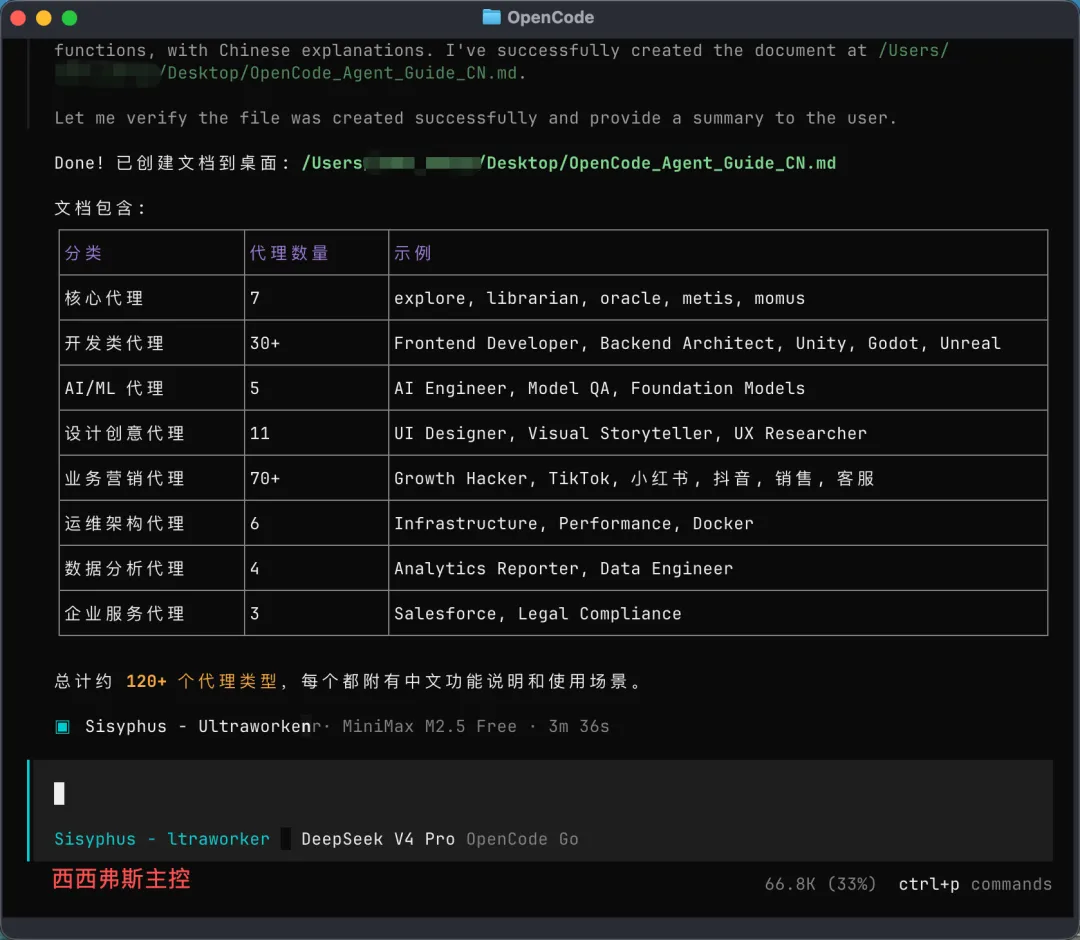
它内置了超过 100 种专家代理,覆盖前端、后端、运维、AI/ML、设计、营销、数据分析、游戏开发…… Claude Code 等AI编程工具都支持,上篇文章中有介绍 114+专家和你一起工作!
但我今天用到的,就只有两个。
二、从零到 PPT:只用两个专家代理
起点:技能文档驱动
OpenCode 有一套「技能(Skills)」机制。我从技能库里直接找到了:
PPT 专家:负责幻灯片结构、布局和视觉设计 内容创作专家:负责文案撰写、叙事逻辑和表达优化
两个代理的组合调用方式:
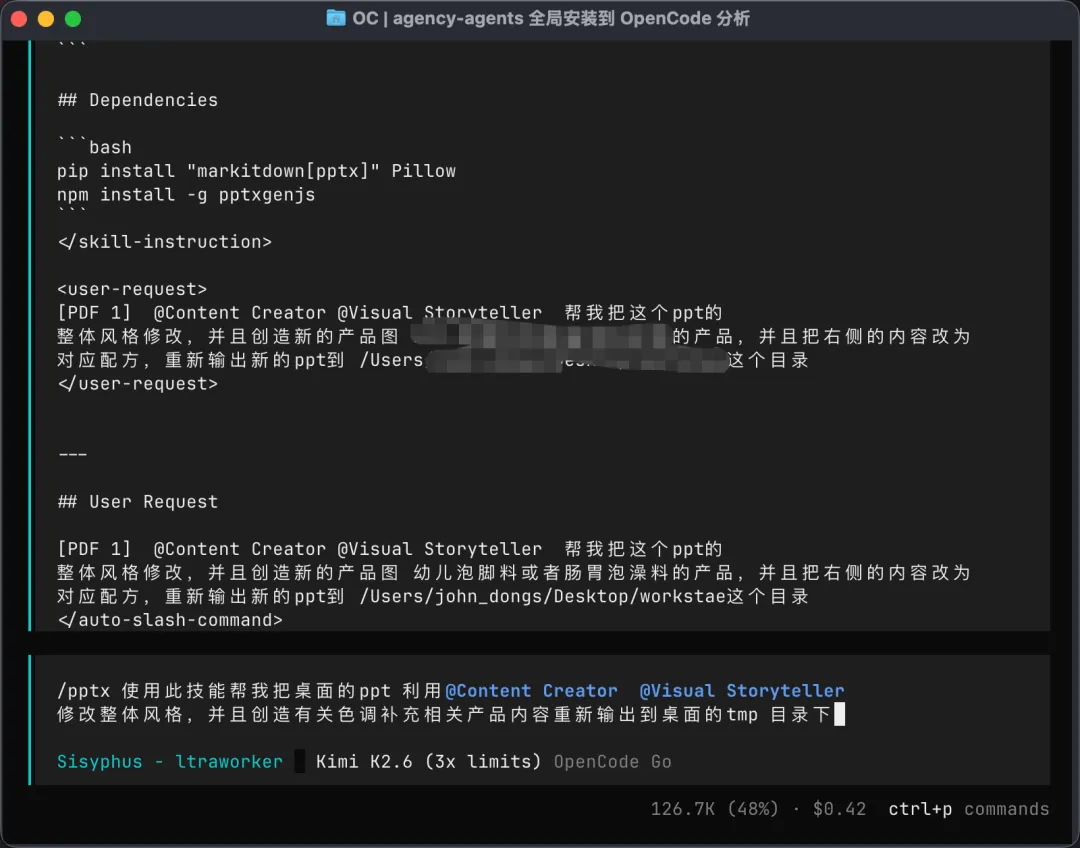
效果让我意外——**第一次生成就达到了我预期的 80%**,结构清晰,视觉不土,内容可用。 ![生成过程 AI工具相关截图,上篇文章114+Agent专家]
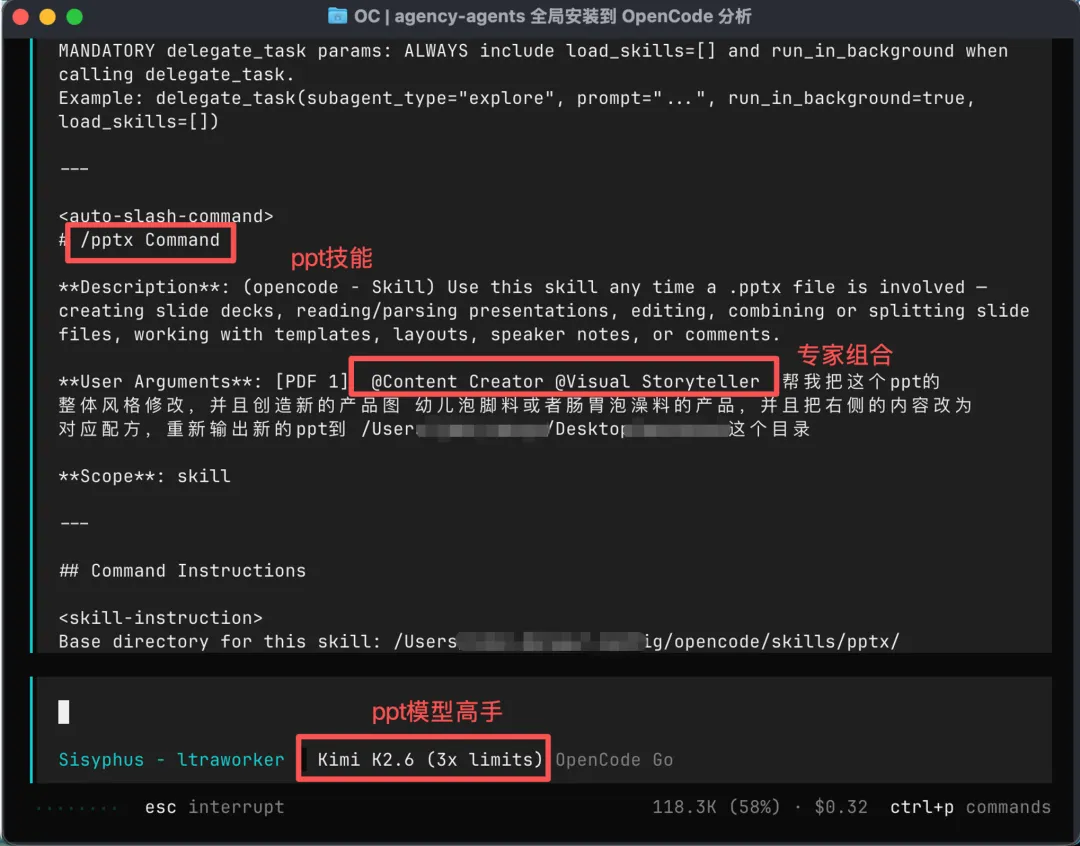
这就是技能文档的价值:它把最佳实践写进了提示词,省去了你反复调教 AI 的时间。
三、进阶:连 MySQL,动态数据自动出 PPT + PDF
静态 PPT 够用,但真正的效率武器是动态生成。
场景设定:公司有一个 MySQL 8.0 数据库,存着销售数据、项目进度、KPI 指标。我想要每周自动从数据库拉数据,生成报告 PPT 和 PDF,不用人工整理。
架构很简单
MySQL 8.0
↓ JDBC 查询
Java/Python 后端
↓ 数据填充模板
PPT 生成(Apache POI)
↓ 转换
PDF 导出(OpenPDF)
用 DeepSeek V4(刚刚官宣,速度极快)来写这套导出逻辑,大约 20 分钟把主体功能跑通了。
// 从数据库读取数据
List<SalesData> data = salesRepository.findByWeek(currentWeek);
// 填充到 PPT 模板
XSSFWorkbook workbook = new XSSFWorkbook();
PPTGenerator.fillTemplate(data, "weekly_report_template.pptx");
// 导出 PDF
PDFExporter.convert("output.pptx", "output.pdf");
功能是通了。但问题来了——
四、天坑出现:PDF 里的中文字全消失了
生成的 PDF 打开一看:排版在,图表在,中文全没了。
这种问题最难调,因为不报错,只是「字不见了」。
第一轮:DeepSeek V4 出马
让 DeepSeek V4 分析问题,它给出了几个方向:
字体路径没找到 字符编码问题 PDF 字体嵌入失败
按照建议改了字体路径配置,换了编码设置——无效。
第二轮:换 Qwen 3.6 Plus
Qwen 擅长中文相关的技术问题,我以为它能直接命中。
给出的方案:检查字体文件是否损坏、尝试 iTextPDF 替代 OpenPDF——依然无效。
第三轮:MiniMax 2.7
MiniMax 的建议更细,涉及到 OpenPDF 的字体加载顺序问题,我一一排查——还是不行。
三个模型,来回折腾,问题没解决,但我对问题的边界越来越清晰了。这其实是重要的:AI 调试的价值不只是给答案,也在于帮你缩小问题范围。
五、Kimi K2.6:多模态找到了根因
我换了策略:直接把截图、报错日志、代码片段全丢给 Kimi K2.6,让它从视觉层面分析。
Kimi K2.6 的回答直接定位了两个根本原因:
根本原因 1:Variable Font 格式不被 OpenPDF 1.3.30 支持
你使用的系统中文字体(如微软雅黑的某些版本)是 Variable Font 格式(可变字体),OpenPDF 1.3.30 的字体解析器无法正确处理这种格式,导致字符渲染时找不到字形,输出为空白。
根本原因 2:OpenPDF 的 CJK 子集化(Subsetting)Bug
即使换用静态字体,OpenPDF 默认会对嵌入字体进行子集化处理以减小文件体积。但其子集化逻辑对 CJK(中日韩)字符存在 bug,会导致字符映射丢失。
解决方案:在字体注册时调用
setSubset(false),关闭子集化。
// 错误方式(默认开启子集化)
BaseFont bf = BaseFont.createFont("fonts/NotoSansSC-Regular.ttf",
BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
// 正确方式(关闭子集化 + 使用静态字体)
BaseFont bf = BaseFont.createFont("fonts/NotoSansSC-Regular.ttf",
BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
bf.setSubset(false); // 关键一行
同时,字体需要换成静态字体(非 Variable Font),推荐使用:
Noto Sans SC(Google Fonts 静态版) 思源黑体静态版
改完,重新运行——
中文完整显示,问题解决。
![问题解决后AI工具截图]

六、复盘:这次实战教会我的三件事
1. 专家组合比单一模型更重要
PPT 生成之所以效果好,不是因为某个模型多厉害,而是因为两个专家代理各司其职——内容专家管文字逻辑,PPT 专家管视觉结构。这是 OpenCode 代理系统设计的精髓。
2. 不同模型有不同的「感知维度」
DeepSeek V4 快,适合快速实现功能逻辑。 Qwen 擅长中文场景的语义理解。 Kimi K2.6 的多模态能力,让它能从截图里「看出来」问题——这是纯文本模型做不到的。
不是一个模型打天下,而是用对的模型做对的事。
3. AI 工具的真正价值是「交付能力」
我一个人,两天内完成了:
数据库连接层 动态数据读取逻辑 PPT 模板填充 PDF 导出修复 整个系统的测试验证
这放在以前,是一个小团队一两周的工作量。
AI 的价值不是替代你思考,而是把你的上限拉高,让你一个人能交付以前需要团队的东西。
七、你现在可以做的事
如果你想复现这套系统,需要的东西:
工具层
OpenCode(本地部署或云端) MySQL 8.0 数据库 Java 17+ 或 Python 3.10+(后端服务)
关键依赖
<!-- PPT 生成 -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.5</version>
</dependency>
<!-- PDF 导出 -->
<dependency>
<groupId>com.github.librepdf</groupId>
<artifactId>openpdf</artifactId>
<version>1.3.30</version>
</dependency>
字体
下载 Noto Sans SC 静态版:https://fonts.google.com/noto/specimen/Noto+Sans+SC 记住: setSubset(false)是关键
模型选择建议
快速实现功能:DeepSeek V4 中文内容生成:Qwen 3.6 Plus 视觉问题定位:Kimi K2.6(多模态) 复杂架构设计:Claude Sonnet / Opus
写在最后
我发这篇文章不是为了告诉你某个模型多厉害。
我想说的是:当你学会把不同模型当成不同专家来调用的时候,你的开发效率会发生质变。
一个人,一台电脑,一套 AI 工具栈——可以做的事情远比你想象的多。
这不是未来,这是现在。
如果你在复现过程中遇到问题,或者有更好的实现方式,欢迎在评论区交流。
