 夜雨聆风
夜雨聆风
读外文论文、教材或技术文档,最折磨人的往往不是语言本身,而是排版。
原文信息密度高,读起来费劲;用普通翻译工具一转,公式崩了、图片丢了、表格乱了,最后剩下一堆难以整理的纯文本。想重新排版?那工作量简直劝退。
市面上保留排版的开源项目不少,但大多挑食:只认可复制、可编辑的 PDF,遇到行内公式复杂点的就歇菜,更别提图片型或扫描版 PDF 了。
最近发现一个开源项目叫 RetainPDF,它从一开始就是冲着硬骨头去的:解决各类 PDF 的保留排版翻译问题,尤其是扫描件和复杂公式。
GitHub:https://github.com/wxyhgk/retain-pdf 网盘:https://pan.quark.cn/s/7966e30bdcd5 提取码:9ZE7
它能做什么?
简单说,上传一个 PDF,它能还你一个保留原始排版的中文译文。
不管是扫描版、截图版,还是满是公式的技术文档,它都能处理。输出格式支持 PDF、Markdown 或 ZIP 打包,按需取用。网页端能直接操作,也支持命令行和 API 接入,方便集成到工作流里。

和同类方案比,强在哪?
比起 PDFMathTranslate 或 PolyglotPDF,RetainPDF 补上了最大的短板:图片型 PDF。它在行内公式与正文的衔接上更自然,排版崩掉的概率明显更低。
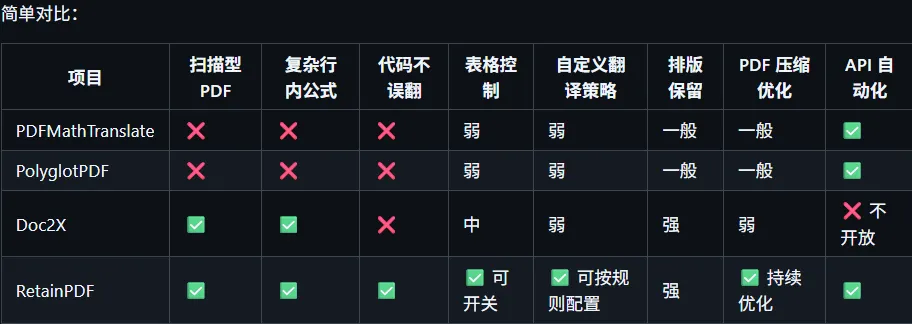
比起 Doc2X 这类闭源方案,它的优势在于自主可控。你可以本地部署,自己掌控接口和结果文件,不用担心数据泄露或服务中断。实测在翻译后的 PDF 体积、整体速度和字体大小控制上,表现甚至更好。
最关键的是,产出的结果接近“直接可用”,不需要再花大量时间手工修排版。
怎么用起来?
这个项目是前后端分离的全栈架构,OCR、翻译、排版与交付全部打通。结构解耦做得不错,既方便直接使用,也利于开发者二次开发。个人用户直接使用开发者打包好的软件就可以。
团队用户:Docker 一键启动
如果你想给局域网、团队或多台设备一起用,推荐用 Docker 部署。
确认环境
系统:优先 Linux(Ubuntu 22.04/24.04),Windows/macOS 也可。 配置:至少 4 核 CPU、8GB 内存(推荐 16GB)、10GB 磁盘空间。 注意:主要吃 CPU 和内存,不依赖独立显卡。ARM 架构(如 Mac M 系列、树莓派)需确认有 x86_64 兼容环境。 安装 Docker 确保已安装
docker和docker compose,并自检版本。拉取项目
git clone https://github.com/wxyhgk/retain-pdf.gitcd retain-pdf启动服务
docker compose up -d启动完成后,浏览器访问
http://127.0.0.1:40001即可。
专业用户:自定义配置
如果你想给团队用,或者调整默认行为,可以修改 docker 目录下的配置文件:
docker-compose.yml:编排入口,默认拉取镜像启动 app + web。docker/auth.local.json:配置 API 鉴权白名单。前端请求头里的X-API-Key必须命中这里的值。docker/web.env:控制前端默认注入的后端 Key、模型默认值、OCR 提供商(默认 paddle,也可切 mineru)等。docker/app.env:控制后端运行参数,如并发任务数、上传大小限制(默认 200MB)、页数限制(默认 600 页)等。
默认暴露三个端口:
40001:前端页面 41000:完整 Rust API 42000:简便同步接口
更新与维护
更新到最新镜像版本很简单:
cd retain-pdf/docker/deliverydocker compose pulldocker compose up -d建议更新后执行 docker compose ps 检查状态。
写在最后
RetainPDF让本地化、高精度的 PDF 翻译变得触手可及。不用再把时间浪费在调整排版上,把精力留给内容本身,这才是技术该有的样子。

