 夜雨聆风
夜雨聆风
1. 爆裂开场:从3000元到4900元的“暴力美学”升级
兄弟们,我真没想到,上一篇关于《3000元老电脑跑起35B大模型》的文章发出去后,后台直接炸裂了。满屏幕的“硬核”、“给力”、“这就去闲鱼捡卡”让我意识到,大家苦云端大模型“按量计费”和高昂硬件溢价久矣。

评论区里,有兄弟热血沸腾:“看完文章我当晚就去垃圾堆里翻出了我的R7 1700,这就去配3060!”但也有兄弟提出了更尖锐的刚需:“博主,15 tokens/s虽然能用,但真要写代码或者读长文档,智力还是差点意思。Q2量化版本偶尔会胡言乱语,上下文4K转瞬即逝,能不能再卷一点?不求4090,能不能在5000块以内让我们看到质变?”
看到这些留言,我这颗折腾硬件的心瞬间又燃起来了。上一套配置我们证明了“能跑”,而这一次,我要带大家看看什么叫“好用”。我把那台3000元的“老破小”重新推上了手术台,进行了一场废土朋克式的暴力手术。
我仅仅追加了不到2000元的预算,整机总价依然死死控制在4900元以内,却完成了一次近乎恐怖的跨代升级。升级后的体感是什么?是生成速度从“等字出来”的15t/s飙升到“满屏刷屏”的50t/s;是智力量化从Q2的“逻辑短路”跃迁到Q4版本的“稳如老狗”;是上下文从捉襟见肘的4K直接扩容到足以吞下一整篇深度长文的16K。
这不再是实验室里的极限生存玩具,而是一台真正能干重活、能当生产力中心的本地AI服务器。这次升级我们不走堆料的邪路,精准地把每一分钱都砸在了显存和扩展性上。兄弟们,坐稳了,4900元干翻万元机的暴力美学,现在开场!
2. 深度复盘:上一代“3000元战神”的极限与痛点

在带大家看新手术方案前,咱们得先聊聊为什么要动这一刀。上一套配置(R7 3700X + B450 + 单张3060 12GB)虽然在性价比上封了神,但在深度使用一周后,我发现了三个不可回避的“极限求生”尴尬点,这些痛点在实际生产中简直让人抓狂。
首先是**“Q2量化的智商缺失”**。 为了把35B模型塞进单卡12GB显存,我们被迫选用了Q2_K量化版本。兄弟们,Q2版本虽然能跑,但它在MoE(混合专家模型)架构下的智力损耗是肉眼可见的。它更像是一个脑子灵光但表达粗糙的助手。
具体场景:我尝试让它分析一段复杂的Rust所有权报错,它虽然能指出大致位置,但在解释生命周期(Lifetime)细节时,由于精度太低,竟然开始自创语法。这种“一本正经地胡说八道”在关键时刻非常致命。
其次是**“4K上下文的多轮失忆”**。 4K上下文在2026年这个动辄万字长文的时代,简直是“金鱼的记忆”。
写长代码报错:你把一个包含五个文件的项目逻辑丢进去,它分析到一半,前面的函数定义就因为窗口溢出被“挤”掉了。 长文润色翻车:我给它一段3000字的公众号草稿,让它根据开头的基调改写结尾。结果它读完结尾,已经忘了开头我定下的那种“热血兄弟情”的语气,回馈给我一股浓浓的AI翻译腔。
最后是**“B450主板的物理天花板”**。 原本那块200元的B450主板,虽然是“穷人乐”首选,但在AI的世界里它已经顶到了肺。你想加卡?对不起,槽位不够,或者是副槽跑在寒酸的PCIe 2.0 x4带宽上。想跑全速并行?想都不敢想。为了从“极限求生”变成“游刃有余”,这套针对性的硬件手术势在必行。
3. 硬件手术清单:4900元的每一分钱都用在刀刃上
很多兄弟问:“你都想加性能了,为啥不去咸鱼蹲个二手3090?或者咬咬牙上4090?”
兄弟,咱们得算一笔账。2026年了,一张成色尚可的二手3090依然要5500元以上,这还没算你为了伺候它那450W功耗必须更换的1000W电源,以及为了装下这尊大佛必须换的大型机箱。这一套折腾下来,预算直接奔着8000块去了。
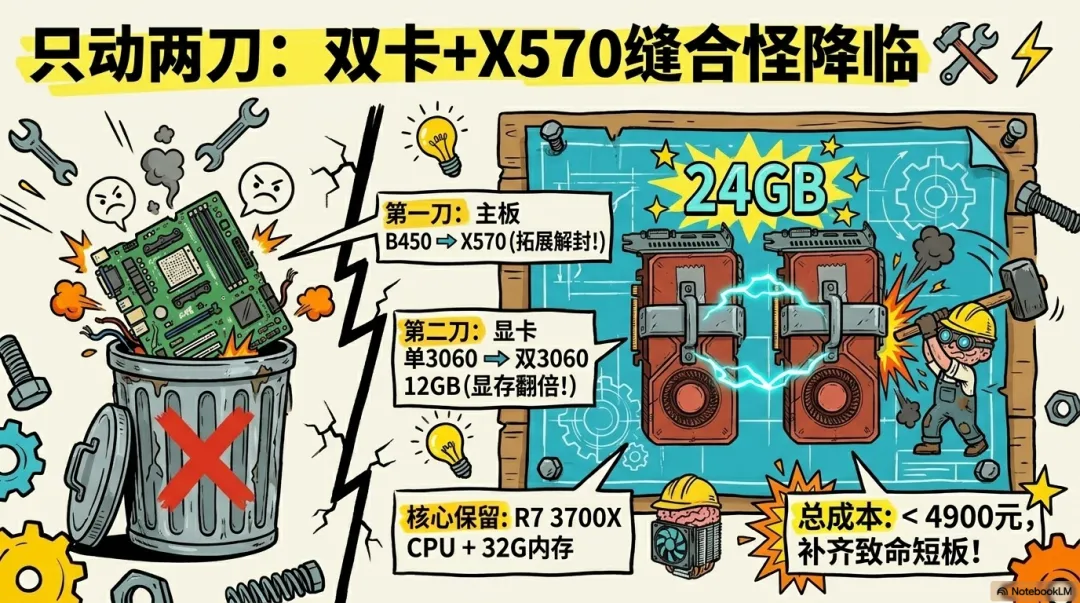
我们的策略是:坚定不移地压榨RTX 3060 12GB。 这张卡的核心算力确实一般,但它那12GB显存简直是本地AI界的“硬通货”。单张3060是12GB,两张拼在一起就是24GB。这24GB显存池,正好能把35B权重的Q4量化版舒舒服服地装进去。
为了支撑起这两张卡,我把原本200元的B450主板,换成了支持PCIe 4.0且具备更强扩展能力的华硕ROG X570-F GAMING。这一刀下去贵了500元,但它换来的是双卡x8+x8的高速通道。在MoE模型频繁切换显存负载时,PCIe带宽就是生命线。
升级方案详细清单(2026年4月参考价):
| CPU | R7 3700X (保持不变) | |||
| 显卡 | RTX 3060 12GB ×2 (双卡) | |||
| 主板 | 华硕ROG X570-F (约700元) | |||
| 内存 | 32GB DDR4 (保持不变) | |||
| 电源/散热 | 650W金牌电源 (增加预算) | |||
| 总成本 | 约3000元 | 约4900元 | 约+1900元 | 每一分钱都为了显存 |
兄弟,这账你得换个姿势算。二手3090(24GB)目前被炒得虚高,而且它是出了名的“核弹”,对电源和散热的要求会逼你再掏一笔巨款。 而两张3060 12GB合计只要2700元左右,不仅显存同样达到了24GB,更重要的是,在llama.cpp的多GPU负载均衡下,这种组合能把模型切得更碎。对于Qwen 35B这种MoE架构模型,双3060带来的显存带宽分布在某些场景下甚至更灵活。
总结一下这笔账:我们只花了不到2000元的升级费。我们没有去碰虚无缥缈的灯效,没有去追求虚荣的最新代CPU,而是精准地换取了本地AI最渴求的24GB显存空间和PCIe 4.0的高速扩展力。这,就叫把钱花在刀刃上。
4. 量化跃迁:从Q2到Q4的“智力体感”实测
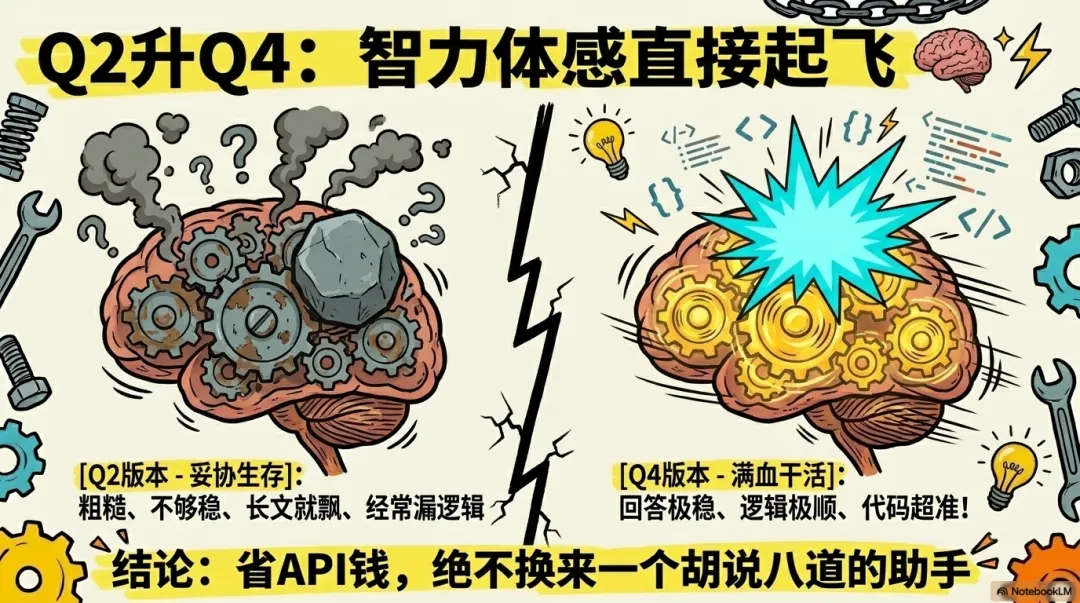
在AI圈子有一句硬道理:量化精度就是模型的“灵魂厚度”。
很多兄弟觉得4-bit量化(Q4)和2-bit量化(Q2)只是文件大小的区别,这就大错特错了。从技术底层来说,Q2量化会将权重信息割裂得支离破碎,导致“困惑度”(Perplexity)急剧上升。如果说Q2是读了精简版名著的初中生,那Q4就是精研了原著的大一新生。
在双卡24GB显存的支持下,我们终于告别了Q2的“脑残期”,迎来了Qwen3.6-35B-A3B的Q4满血体验。实测下来的智力体感,完全是两个维度的物种:
逻辑稳定性(不再胡言乱语): 以前问Q2版本一个复杂的逻辑题,比如“如果你有三个苹果,吃了一个又买了两,但我告诉你其中一个是烂的,请问你现在能吃几个?”,Q2版本偶尔会因为精度丢失,在计算过程中出现奇异的偏移。而Q4版本逻辑极度严密,它能清晰地拆解事实,逻辑链条环环相扣。 代码处理的细腻度: 我尝试让它重构一段带有异步逻辑的Python代码。Q2版本虽然改对了大部分,却漏掉了一个关键的异常处理闭环;而Q4版本不仅补齐了异常,甚至还主动建议我增加日志埋点,并给出了合理的重试机制。这种“细腻度”的碾压,才是本地AI真正从“好玩”进入“生产力”工作流的标志。
对于我们这些拿AI当生产力工具的兄弟来说,Q4量化提供的不仅仅是准确率,更是一种“安全感”。你不需要时刻担心它在某个代码角落给你埋雷,这种信任感的提升是无价的。
5. 性能封神:50t/s 与 16K 上下文的极致吞吐

智力提升只是底色,真正让我和工作室的小伙伴们尖叫的,是那个快到离谱的输出速度。
为了压榨这套双3060系统的极限,我们采用了最新的llama.cpp环境,并开启了针对双卡的深度优化。技术党的兄弟们,看好了,这是我反复调试后的最强启动指令:
$env:CUDA_VISIBLE_DEVICES="0,1".\build\bin\llama-server.exe ` -m "D:\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf" ` --host 0.0.0.0 ` --port 8080 ` -c 16384 ` -ngl 99 ` --split-mode layer ` --tensor-split 1,1 ` --flash-attn on ` -b 2048 ` -ub 512 ` --parallel 1 ` --threads 16 ` --temp 0.6 ` --top-p 0.95 ` --top-k 20 ` --min-p 0.05实测性能数据分析:
生成速度:约 50 tokens/s 兄弟们,15t/s的时候,你还能盯着屏幕看它一个字一个字蹦,像是在看老牛拉车。而50t/s是什么概念?那是真正的“满屏横扫”。你刚按下回车,啪的一下,一段高质量的分析已经横空出世。这种视觉冲击力让“等待感”彻底消失,AI的使用体验变得像刷短视频一样流畅,思维的连贯性从未如此之好。

上下文长度:实测 16K 平滑运行 16K意味着什么?它意味着你可以直接把一整篇万字公众号草稿,外加几千行的部署日志,甚至是一个小型项目的整个核心代码文件夹一次性喂给它。由于我们开启了
--flash-attn on(闪存注意力机制),在处理长文本时显存压力大幅降低,它不再会“读了后面忘前面”,它能精准地在整篇长文中进行跨段落的逻辑归纳。双卡负载均衡:
**--tensor-split 1,1**通过这个参数,我们将模型层均匀地切分到了两张3060上。每张卡负担约10-11GB的显存占用,留出1GB左右作为显存缓冲区,防止在长上下文对话中突然崩盘。这种均衡负载,让两张卡的温度和功耗都非常平稳。
6. 场景落地:把老破小变成真正的本地AI服务器
当性能不再是瓶颈,这台4900元的“缝合怪”就不再只是折腾的产物,它成了一个真正的本地生产力中心。
为什么要坚持本地部署?兄弟们,这账得细算:
隐私安全(终极正义):你的商业计划书、还没发布的视频脚本、甚至是公司内部的敏感代码,再也不用上传到云端去喂别人的模型。在本地跑,断网也能用,物理级的安全。 无限免费(告别割韭菜):只要不关机,你想跑多少万字就跑多少万字。再也没有什么“Plus会员20美元一月”,也没有什么“额度用尽”的焦虑。 响应极速:局域网内几乎零延迟。配合OpenWebUI,我老婆在客厅用iPad,我在书房用工作站,甚至我在厕所用手机,都能同时调用这台战神的算力。
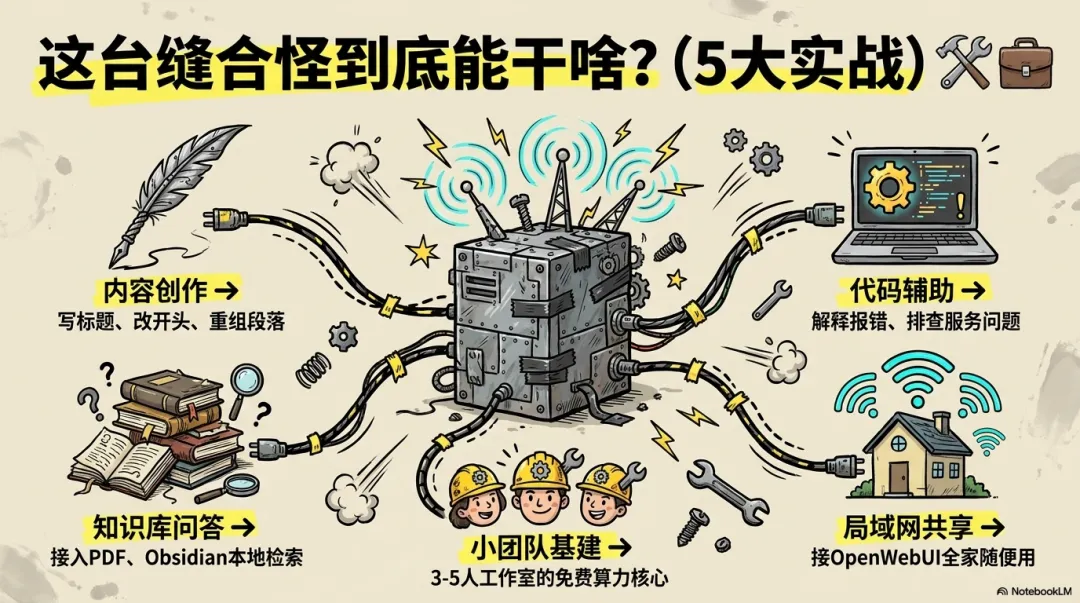
我们的实战应用方案:
内容创作润色:写完文章,丢进本地AI,让它帮我拆解结构、改写爆款标题。由于它有16K记忆,它可以通读全文后给出非常精准的修改建议。 本地知识库检索:挂载我过去三年的所有硬件测试笔记,让AI成为我个人的“大脑外挂”。 代码排错:直接把整段复杂的报错日志贴进去,不用裁剪,让它在本地环境帮我逐行排查。
这套方案不仅适合个人爱好者,对于3-5人的小创业团队,它都能成为一个成本极低的AI基础设施。它虽然看起来不体面,但它真的能帮你把活儿干了。
7. 2026避坑指南:双卡+X570的生存法则

兄弟们,硬件虽然香,但在搭建过程中我也踩了不少坑。为了不让大家重蹈覆辙,我总结了5条血泪经验,这是真正的“生存法则”:
主板的PCIe槽位玄学: 双卡不是插上就能飞。一定要选像华硕ROG X570-F GAMING这种能够支持PCIe 4.0 x8+x8通道拆分的主板。很多廉价主板第二个槽是物理x16但带宽只有x4,甚至是走南桥的x2。如果是那种带宽,副卡的速度会成为整机的拖油瓶,生成速度直接从50t/s跌回20t/s。买主板前,一定要看清楚说明书上的通道分配。 散热:双卡的“火炉效应”: 两张RTX 3060挤在一起,中间那张卡的背板会烫得能煎鸡蛋。如果你的机箱风道不好,不出十分钟显卡就会因为过热降频,速度骤减。我的建议: 必须使用大空间机箱,侧板加装两个暴力风扇,专门对着显卡缝隙吹。 电源储备:不能省的救命钱: 虽然3060单卡功耗才170W左右,但双卡加上满载的R7 3700X,加上瞬时峰值,500W电源是在玩火。强烈建议650W金牌电源起步。在二手市场,650W和500W的差价也就几十块钱,千万别省这笔钱。 软件参数调优(重点): 启动命令里的 -ub 512(超批处理大小)和--threads 16要根据你的CPU实际核心数来定。我的R7 3700X是8核16线程,设为16能获得最佳的推理调度。另外,--flash-attn必须开启,这是节省显存、提升长文本速度的神器。显卡选择:拒绝“花里胡哨”: 买二手3060时,尽量买双风扇的丐版,不要买那种巨大的三风扇卡。为什么?因为三风扇卡太长太厚,在很多主板上插了两张后,剩下的空隙太小,散热直接崩盘。双风扇卡身材适中,才是双卡并行的高性价比之选。
8. 热血结尾:告别云端收割,本地AI终将称王

写到这里,我抬头看看桌底下那台还在嗡嗡作响、闪着微弱RGB灯光的“老缝合怪”,心里满是感慨。
很多人说,AI是巨头的游戏,是4090和H100的战场,是普通人玩不起的奢侈品。但我想告诉大家,性价比不是去追逐最强的单卡,而是用最少的钱、最野的路子,跑通最高效的工作流。
从3000元到4900元,我们不仅是多加了一张显卡,更是打破了那种“不花大钱就玩不了大模型”的固有偏见。这种“废土朋克”式的玩法,才是我们这代硬件玩家真正的浪漫:在旧时代的残骸里,挖掘出新时代的算力之火。
不要被云端的订阅费割韭菜,也不要被高昂的硬件溢价劝退。这台二手硬件缝合出来的服务器,照样能在这个AI时代为你开疆拓土。
兄弟们,老电脑还能再战十年!在评论区晒出你的配置和实测数据,让我们看看谁才是真正的“本地性价比之王”。下一篇,我打算聊聊如何接入本地知识库,把这台战神彻底武装成你的“第二大脑”。
AI的未来不在云端,而在你的电脑硬盘里!
别看了,赶紧动手:
点个赞,转发给同样受够了“云端模型”的朋友。 评论区晒出你的硬件配置和实测Tokens/s,我在线帮你调优配置。
下期预告: 《OpenClaw + 本地RAG 打造零云端AI数字员工》。资源获取: 完整配置文件、模型下载直链、Obsidian模板已存放博客,看我主页即可取用

