 夜雨聆风
夜雨聆风痛点突出
让人头疼的文档一致性难题
在大型装备制造、工程建设或科研项目交付中,最让团队如履薄冰的,往往不是单一技术的突破,而是确保海量文档中技术参数、性能指标、材料规格的绝对一致。
一份最终的《总装报告》、《验收大纲》或《项目总览》,其核心数据都源自数百份分散的《子系统设计手册》、《部件测试报告》和《物料清单》。一旦源头文档在迭代中更新了一个参数,而总成文档未能同步,轻则导致交付争议,重则引发运行风险。
过去,我们只能依靠资深工程师,人工翻阅成百上千页文档,像“人肉差分机”一样逐项比对。这个过程耗时耗力、极易出错,已成为项目质量和效率的突出瓶颈。
初试AI
通用的语义检索在技术文档前失灵
强大的AI大模型能帮我们解决这个问题吗?我们首先尝试了通用AI方案,将所有子文档切片,构建知识库,让AI根据总结文档的每一段描述进行全文语义检索和比对。
结果却令人沮丧。AI召回的内容常常失之毫厘,谬以千里。原因在于,技术文档中充斥着大量高度相似的专业术语和描述结构。例如,“壳体材料屈服强度 ≥ 355MPa”这个指标,可能出现在多个不同部件的规格书中。传统的语义检索只能识别到“屈服强度”和“MPa”的相似性,却完全无法判断这个“355MPa”究竟属于“泵体壳体”还是“阀体壳体”,导致比对结果一片混乱。这种“大力出奇迹”的粗放方法,在要求精确一致的技术领域碰了壁。
破局关键
像专家一样按图索骥的AI智能体
纯靠语义匹配走不通,我们回归工程思维的本质。一位优秀的工程师在核对指标时,绝不会盲目搜索,而是会先定位文件,哪份报告?再定位章节,哪项指标?最后核对具体数值。
我们据此设计了一套引导AI模拟这一精确思维过程的工作流:
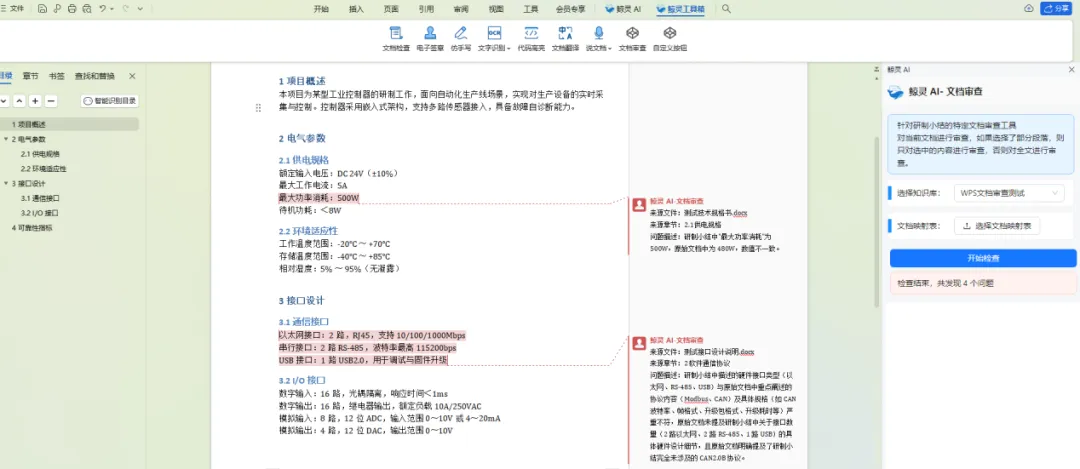
不让AI直接扎进数字的海洋。我们将待核对段落,如总报告中的某项性能综述,连同所有子文档的文件编号与标题交给AI,利用AI强大的推理能力,找到最可能源自的测试报告或设计文档。这一步,将搜索范围从所有文档的所有内容,精准缩小到少数几份相关文档。
锁定文档后,我们提取该文档的详细目录树。AI通过理解“章节3.1 静态强度测试”与“章节3.2 疲劳性能测试”的逻辑关系,能够精准判断出来总报告中关于“极限载荷”的结论,应源自《XX结构测试报告》的第3.1.2节“极限工况数据”。这一步,赋予了AI“按图索骥”的能力。
此时,我们才将源头文档中定位到的具体章节内容提取出来,与总报告中的描述并列,交给AI进行严格的一致性校验。AI会像一名质检员,精确识别出“参数数值不匹配”、“计量单位不一致”、“技术状态描述冲突”等问题。
最终,所有AI发现的不一致项,都会自动以批注形式,附带来源定位,插入到文档中。评审专家打开文档,哪里不一致、原始数据是什么、建议如何修正,一目了然,形成了从发现问题到解决问题的完整闭环。
价值启示
从“模糊感知”到“精确制导”
这套方法将技术文档审核从“人海战术”带入“智能精确制导”时代,效率与准确性获得数量级提升。
这次实践给我们最核心的启示是:在高度结构化、逻辑严谨的专业领域,直接套用面向通用文本的AI方法往往效果不佳。技术文档的价值不仅在于“文字”,更在于文字背后严密的结构、归属关系和精确的指标。
成功的AI工程化应用,关键在于将人类的领域知识,如文档结构、技术规范,转化为AI可理解和遵循的“导航规则”。通过多步骤的工作流,我们将AI从一个“模糊的语义理解者”,引导成一个“严谨的结构化信息处理者”,使其真正具备了解决“技术指标一致性”这类核心、高价值痛点的能力。这或许是AI融入严肃工业场景的必由之路。
关注【电科安全】公众号,了解更多吧。

供稿/杜梦男
编辑/王艳琳
审核/谢世传
