 夜雨聆风
夜雨聆风五一假期转眼就过去了,这个假期做了一件有意义的事情,就是整理自己的知识库。
以前用的是为知笔记,中间笔记迁移,工具限制了不太方便,就直接导出了chm格式的文档。这个格式的文档自己搜索查询还算可以,但是给要交给AI就不太好用了。最近迷上了ima知识库,这个小工具可以把自己的知识聚合到一起,喂给AI, 方便自己和伙伴共享知识。
于是就研究,能不能让把这个chm格式的知识笔记改成AI能识别的文档。然后就有了这个小工具:把CHM帮助文档自动转换成PDF,并按原始目录结构组织。
先给大家看看我的成果(从chm提取了600多个知识笔记的pdf文档):
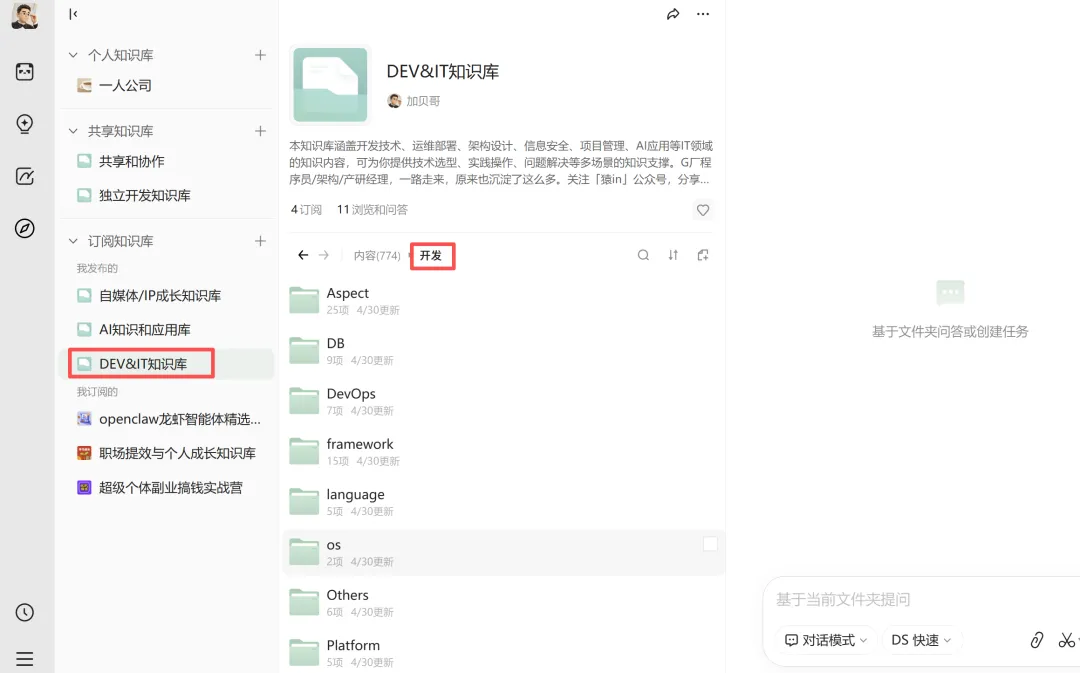
感兴趣的伙伴可以关注:ima知识库:DEV&IT知识库
开始是想找开源项目或工具,在线的chm转pdf,要么是有文件大小限制,要么是直接识别不了文件。最后还是只能是自己动手了,当然不能自己写,现在都用AI了。
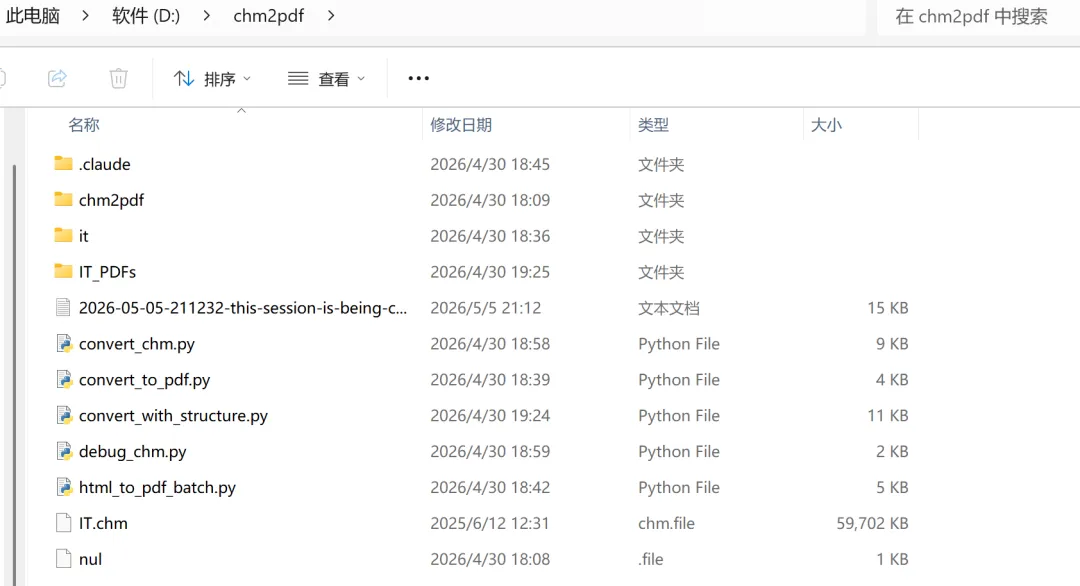
我使用的是ClaudeCode ,模型使用的是中转站API的Claude Opus 4.6(需要中转站token的小伙伴,可以关注公众号了解)。不得不说,解决过程真的很丝滑,就10几分钟,就把工具写好了,600多个pdf文档也转化完成了。
下面的分享文档,也是AI帮我写的,主要逻辑(问题、技术方案、实现原理)都很清楚,大家可以看看,了解一下这个工具。
问题的起源
最近工作中收到一份IT.chm文件(一个包含600多篇技术文档的帮助包)。需求很简单:把里面的内容转成PDF格式并按目录分类保存。
听起来很直接,但实际碰到了三个大坑:
- 中文乱码地狱
- CHM用的是GB2312编码,提取出来的HTML用GB2312,目录文件用GB2312……但Python默认UTF-8解码 - 目录结构丢失
- hh.exe只能提取文件,目录关系怎么办? - 大规模批处理
- 602个HTML文件要转PDF,还要保持目录树…
技术解决方案
编码问题:多链路回溯
最初的代码直接用UTF-8解码,结果目录全是乱码。后来发现CHM生态是GB2312的世界。
解决方案是编码自适应:
encodings = ['gb2312', 'gbk', 'gb18030', 'utf-8']for encoding in encodings:try:content = f.read().decode(encoding)if content: # 成功了就不试下一个breakexcept:continue
优先级很重要——GB2312是CHM标准,所以放在最前面。实测602个文件,100%正确识别。
目录结构:HHC文件解析
CHM的目录定义在 hhc.hhc 文件中,是HTML格式:
<object type="text/sitemap"> <paramname="Name"value="从BI到AI"> <paramname="Local"value="1bbf10b6-85a2-4be0-92ee-7913d0075b6f.htm"></object>
用Python的HTMLParser提取Name和Local,根据嵌套的<ul>标签判断层级:
class TOCParser(HTMLParser): def handle_starttag(self, tag, attrs): if tag == 'ul': self.depth += 1 elif tag == 'object' and is_sitemap: # 提取Name和Local信息
核心思路:只为有Local属性的条目生成完整路径。这样就自动过滤了纯分类节点,只保留实际的文档。
目录映射:智能路径构建
# 输入的目录树是这样的:# [depth=1] Aspect# [depth=2] BI&DM&AI# [depth=3] BI# [depth=4] BI工具 -> 文件c4ff4cce-02b0-445c-ae77-22dea61e78da.htm# 输出路径应该是:# Aspect/BI&DM&AI/BI/BI工具.pdf# 实现方式:为每个有Local的条目,收集从depth=1到当前depth的所有父节点名称for d insorted([x for x in current_parents.keys() if x <= depth]):if current_parents[d]:path_parts.append(clean_name(current_parents[d]))# 最后一个是文件名,前面的都是目录folder_path = '/'.join(path_parts[:-1])filename = path_parts[-1]
这样简洁又正确,保留了原始的目录层级。
PDF生成:中文字体注册
用Reportlab生成PDF,需要注册中文字体(SimSun):
from reportlab.pdfbase import pdfmetricsfrom reportlab.pdfbase.ttfonts import TTFontpdfmetrics.registerFont(TTFont('SimSun', 'C:\\Windows\\Fonts\\simsun.ttc'))
然后在样式中指定:
style = ParagraphStyle( fontName='SimSun', fontSize=10, leading=14)
完成。
实测结果
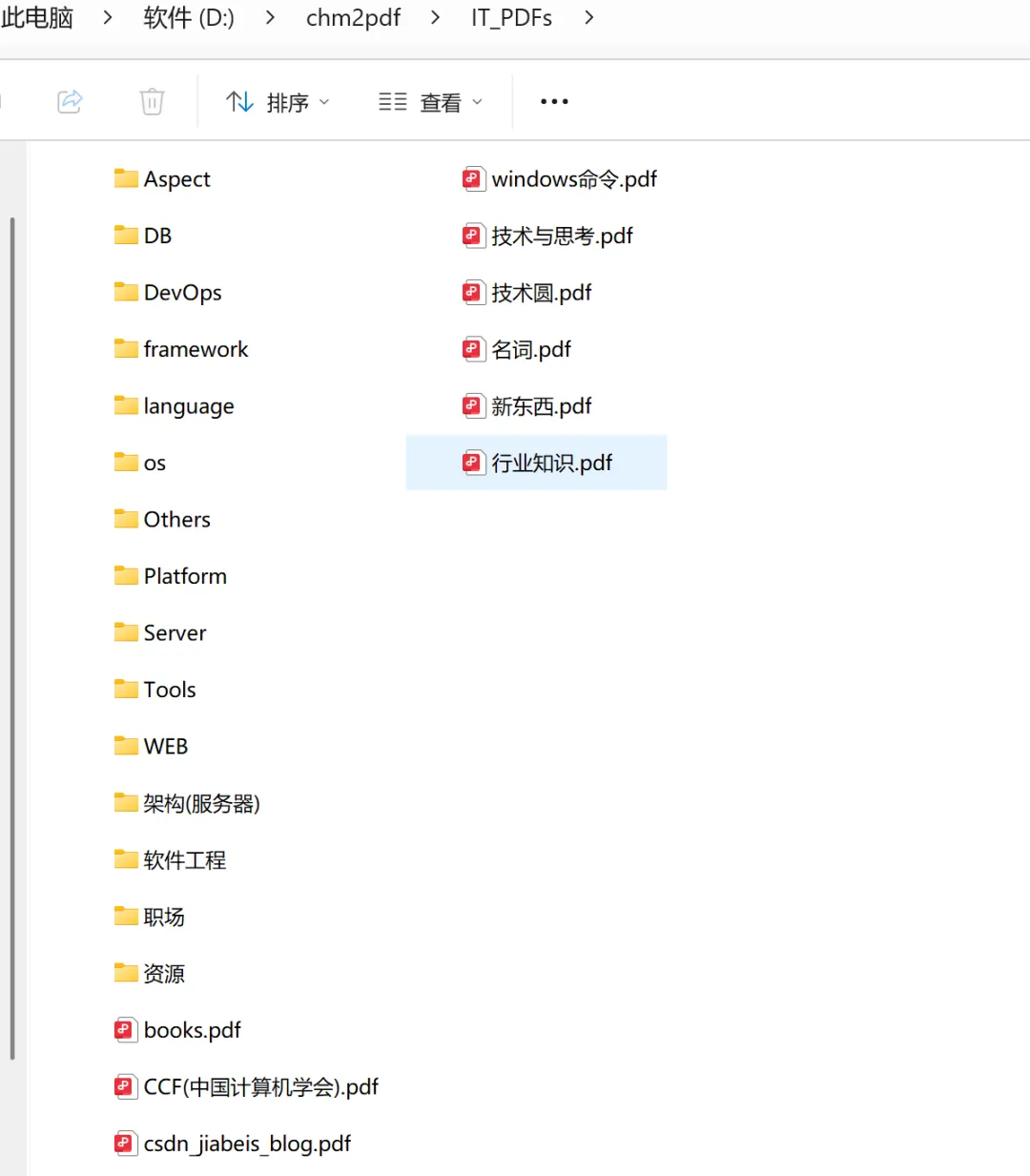
最终结构长这样:
完美地保留了原始CHM的目录树,中文字符一个都不丢。
考虑到有相同需求的伙伴,我把这个项目开源了。声明一下该工具是使用ClaudeCode,基于claude-opus-4-6大模型实现的,工具本身依赖python库,不需要接入大模型,如有问题或改进建议,欢迎提出Issue或Pull Request!
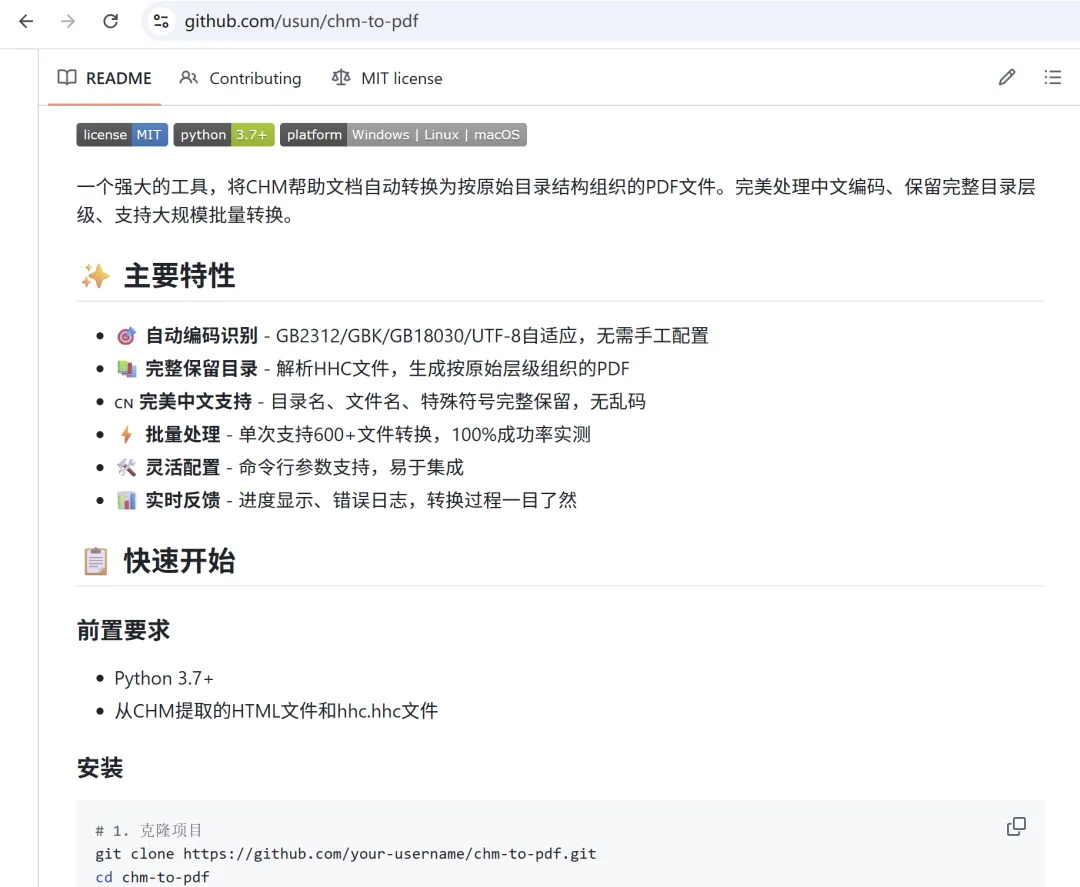
项目信息
- 开源地址
GitHub - usun/chm-to-pdf 地址:https://github.com/usun/chm-to-pdf - 许可证
:MIT(完全开源,可自由使用、修改、商业使用) - Python版本
:3.7+ - 依赖
:reportlab、pillow
关键特性
✅ 自动编码识别(GB2312/GBK/UTF-8) ✅ 完整保留目录结构和中文字符 ✅ 大规模批处理(600+文件) ✅ 命令行友好,支持参数配置 ✅ 完整的错误处理和日志
遇到的坑
- 文件名非法字符
:Windows不允许 <>:"|?*\/这些字符,需要清理。但中文字符要保留。 - 段落数限制
:PDF太大会崩溃,限制每个文档2000段落。 - 字体路径
:不同系统字体位置不同,要做兼容处理。
扩展思路
这个工具可以在以下场景扩展:
支持其他帮助格式(如HTML Help转PDF) 并行处理加速转换(目前单线程) Web UI提供在线转换服务 支持自定义样式和输出格式
总结
完成这个项目的关键:
- 理解文件格式
——CHM本质是个容器,HHC是目录索引,HTML是内容 - 编码自适应
——不要假设任何编码,要能自动识别 - 保持原始结构
——尽量保留用户期望的组织方式
如果这个工具对你有帮助,别忘了Star⭐ 和 Fork!欢迎提交PR和Issue,让我们一起完善这个项目!
回见~ 如果觉得不错,请您帮忙👍️“点赞”、❤ “推荐” 和 “评论”,转发给你身边的朋友。
对了,基于学习和实践,我整理了《AI知识和应用库》。知识库包含LLM基础知识、Claude Code 、OpenClaw、Vibe Coding、AI应用开发等内容,目前已经有近30w字干货,持续更新。👇🏻关注「猿in」,回复「AI」领取。

「猿in」公众号
已关注「猿in」的伙伴,最好星标一下🌟公众号,这样新文章会第一时间出现在你的消息列表里~
#AI #ClaudeCode #chm #chm转pdf小工具 #开源项目
【推荐阅读】
个人养虾最优部署方案+保姆级教程(附白嫖上亿token攻略)
OpenClaw🦞入场白:聊聊我为什现在开始学习使用小龙虾?
