 夜雨聆风
夜雨聆风记录 AI 和新工具,如何重写普通人的工作与学习方式
不用向量库,PageIndex 把 PDF 检索讲清楚了
很多人做 RAG,第一步就是切块、向量化、塞进向量库。
这套流程太熟了,熟到我们有时候忘了问一句:如果文档本来就有目录、章节、表格和脚注,为什么非要先把它切碎?
这也是我这次看 PageIndex 最有意思的地方。

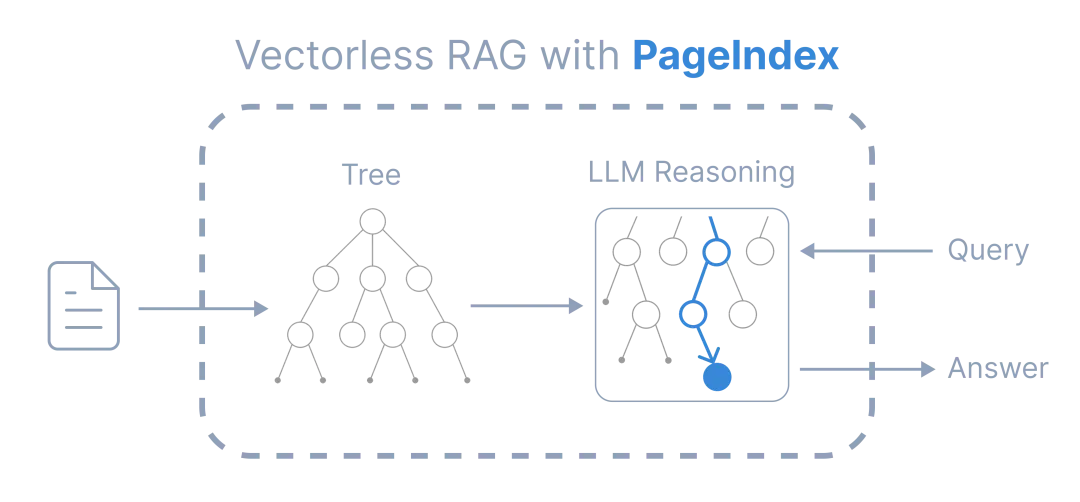
它不是又做了一个更会“搜相似段落”的工具,而是换了一个起手式:先把长 PDF 还原成一棵树,再让模型顺着这棵树去找答案。
对长篇专业文档来说,最重要的可能不是搜得快,而是别把结构先弄丢。
PageIndex 到底改了哪一步
PageIndex 是 VectifyAI 开源的一个文档索引工具。官方给它的定位很直接:vectorless、reasoning-based RAG。
说成人话,就是不用 embedding,不先依赖向量数据库,也不把文档切成一堆孤立 chunk。
它会先把 PDF 变成一个类似目录的层级树。每个节点对应一段自然结构,比如章节、子章节、页码范围和摘要。然后模型不是一次性去全库里捞 Top-K,而是像人读年报一样,先看目录,再判断该进哪一层,再继续往下找。
这件事听起来不复杂,但它戳中了传统 RAG 在长文档里的一个老问题。
很多检索失败,不是模型不会回答,而是它一开始拿到的材料就不对。
比如你问一份 10-K 财报里的某个收入变化,向量检索可能找到一堆“收入”“增长”“业务分部”相似的段落。但真正的答案也许藏在某个表格、脚注,或者一个小节下面。词很像,不等于证据真的对。
98.7% 这个数字要怎么看
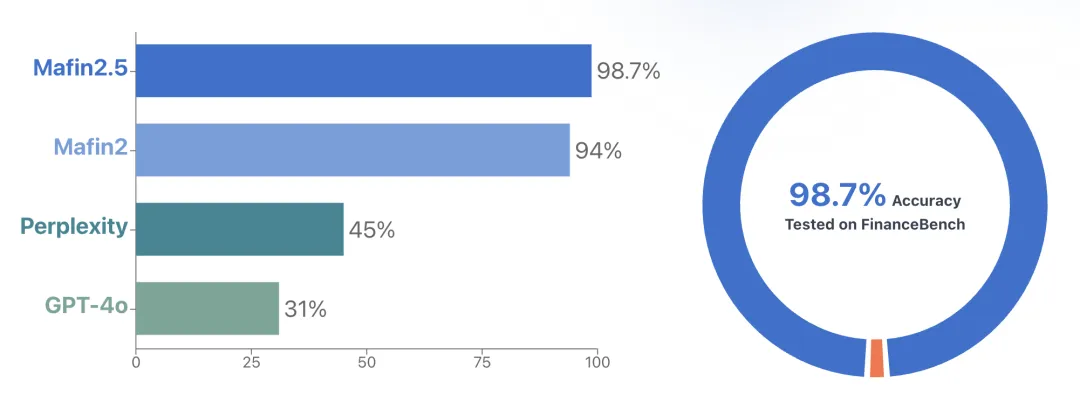
这次 PageIndex 被很多人注意到,是因为 VectifyAI 的 Mafin 2.5。
按照官方博客和评测仓库的说法,Mafin 2.5 基于 PageIndex,在 FinanceBench 上取得了 98.7% 的准确率。FinanceBench 是一个金融问答基准,问题来自上市公司公开材料,很多任务都要从 SEC 备案文件里找到答案和证据。
这个数字确实亮眼。
但我会稍微加一个括号:98.7% 是 Mafin 2.5 这个金融 RAG 系统在 FinanceBench 上的结果,不应该简单理解成“只要装了 PageIndex,所有 PDF 问答都能 98.7%”。
官方首页还给过一个对比:传统向量 RAG 的两种设置大约在 30% 和 50%,PageIndex 方案是 98.7%。这个对比很有冲击力,但它更适合作为方向提示,而不是万能结论。
真正值得记住的是后面那层原因。
金融报告这种文档,天生就是层级化的。章节、表格、附注、页码、披露口径,很多答案依赖结构。你把它粗暴切碎以后,再用相似度去找,就很容易把“看起来相关”和“真正回答问题”混在一起。
PageIndex 的价值,是让 AI 先学会按结构找材料。
它适合什么,不适合什么
我觉得 PageIndex 最适合三类东西。
第一类是财报、招股书、SEC 文件。它们长,而且结构稳定。
第二类是合同、政策、规范、技术手册。你经常不是要泛泛总结,而是要找到某个条款、某个定义、某个例外。
第三类是教材、论文合集、研究报告。问题往往不是“有没有这个词”,而是“这个概念在哪一章被定义,后面又如何展开”。
这些场景里,目录不是装饰。目录本身就是检索路径。
但它也不是没有代价。
PageIndex 需要先生成树状索引,检索时还要让模型多次判断该走哪一层。这意味着更多 LLM 调用,也就是更高成本和更长延迟。对便宜、快速、模糊的资料搜索来说,向量库依然很实用。
另外,如果资料本身很乱,比如聊天记录、网页碎片、扫描质量差的材料、没有明显层级的杂项知识库,PageIndex 也未必占便宜。你得先把结构清出来,它才有东西可走。
不是所有知识库都需要一棵树,但长文档一旦有结构,就不该只当一袋词来搜。
对普通人有什么用
普通人未必马上要部署 PageIndex。
但它给了我们一个很实用的提醒:以后让 AI 读长 PDF,不要一上来就问答案。
可以先让它做三件事。
先生成目录和章节摘要。
再让它说明为了回答这个问题,应该进入哪几个章节。
最后再要求它给出页码、章节名和原文证据。
这其实就是 PageIndex 背后的工作习惯。
你不一定要先搭一套复杂系统,也可以先改变提问方式。尤其是处理合同、年报、说明书、论文的时候,不要把 AI 当成全文搜索框,而要把它当成一个会翻目录的助理。
如果它连自己从哪里找到答案都说不清,那答案写得再顺,也只能先打个问号。
我更在意的是这件事
过去两年,RAG 的很多讨论都围着向量库、chunk size、rerank、embedding 模型打转。
这些当然重要。
但 PageIndex 把另一个问题推到了台前:文档本来是什么形状,AI 有没有尊重这个形状?
对于短文本和泛检索,向量相似度很好用。可一旦进入专业长文档,尤其是财务、法律、医学、工程这些领域,很多错误都不是因为模型不聪明,而是因为系统一开始就把上下文拆坏了。
PageIndex 不一定会替代传统 RAG。
但它很清楚地提醒了一件事:以后做文档 AI,不能只问怎么搜得更快,也要问怎么读得更像一个靠谱的人。
参考资料
VectifyAI/PageIndex, https://github.com/VectifyAI/PageIndex
PageIndex Leads Financial QA Benchmark, https://pageindex.ai/blog/Mafin2.5
VectifyAI/Mafin2.5-FinanceBench, https://github.com/VectifyAI/Mafin2.5-FinanceBench
FinanceBench: A New Benchmark for Financial Question Answering, https://arxiv.org/abs/2311.11944
留言区
如果让 AI 帮你读一份很长的 PDF,你最担心它漏掉哪类信息?
