 夜雨聆风
夜雨聆风
有一类需求,刚接到的时候看起来很普通:
在网页里预览 Excel。
但真正做过的人都知道,这句话后面藏着很多夜里会突然想起来的问题。
它不只是“把表格读出来”。它要像 Excel:列宽要对,行高要对,合并单元格不能散,边框不能粗成一团,隐藏行列要消失,文本该溢出时要溢出,该换行时要换行。更麻烦的是,用户不会只给你一个 200 行的小表。他们会给你 30 万行、50 万行,甚至接近百万行的数据表,然后期待鼠标滚轮一动,页面还是稳的。
这次重构,就是从这些很具体、也很让人共情的问题开始的。
一开始,问题很朴素:它会卡
早期实现里,我们踩过几乎所有大文件预览都会踩的坑:
解析阶段太重,主线程容易被拖住,页面像“死了”。 只加载前几百行,滚到后面就是空白。 鼠标拖动滚动条时,动态加载跟不上,视图突然断层。 切回已经看过的区域,数据没有被缓存,还要重新等。 样式看起来“差不多”,但越到复杂报表越不像 Excel。
这些问题单独看都能忍一下,放在一起就很伤体验。
尤其是那种用户已经滚到了很深的位置,页面突然空白的瞬间,开发者自己看着也会有点无力。你知道不是一个按钮没写好,而是整个数据模型、解析策略、渲染方式都在提醒你:原来的路走不下去了。
我们最后换了一个思路
不是把整张 Excel 变成一张巨大的 DOM 表格。
也不是把所有数据一次性塞给表格组件,祈祷浏览器足够强。
这次的核心思路是:
解析要完整,渲染要克制;模型要稳定,数据要按需进入视口。
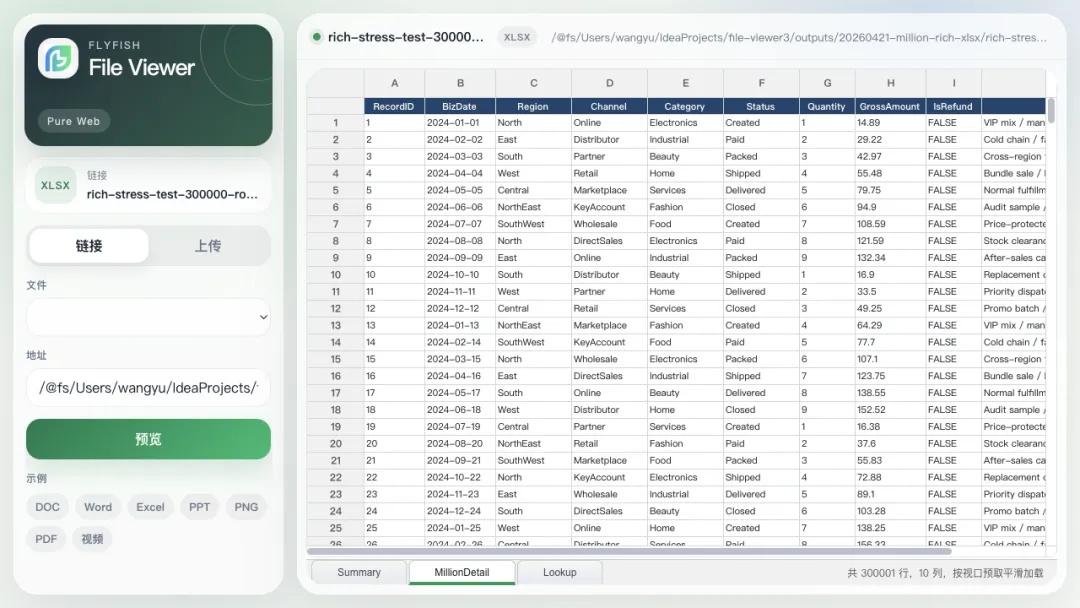
现在的链路被拆成了几层:
styled-exceljs负责统一读取 XLS / XLSX,扩展样式、列宽、行高、隐藏、合并、边框、对齐等视觉信息。Web Worker 负责高开销解析,主线程不再直接背完整解析压力。 虚拟数据模型只初始化稳定的行引用,不把每个单元格都变成 DOM。 e-virt-table基于 Canvas 做高效表格渲染。只有边框、换行、垂直对齐、文本溢出这类 Canvas 普通绘制不容易完全还原的部分,才用轻量 DOM 覆盖层补齐。 视口附近按窗口加载,并提前预取下几个窗口,让滚动更平滑。
这件事的关键不是“让浏览器一次画完百万行”,而是承认浏览器不应该一次画完百万行。
样式读取:从“能看”到“像 Excel”
Excel 最容易被低估的地方,是样式信息非常碎。
一个单元格看起来只是黄色底、黑色边框、居中显示。实际读取时,信息可能来自列样式、行样式、单元格样式,还可能带主题色、tint、边框类型、隐藏状态、默认行高、默认列宽。
这次我们把 Excel 读取统一收敛到 styled-exceljs:
const readOptions = {type: 'array',dense: true,cellDates: true,cellStyles: true,browserPixels: true,validateMerges: true}它给预览层提供了几个非常关键的能力:
cell.s:完整样式对象,包括字体、填充、边框、对齐、数字格式等。ws["!cols"]/ws["!rows"]:列宽、行高、隐藏状态,以及浏览器像素值。browserPixels:把 Excel 的尺寸换算成更接近浏览器渲染的像素。validateMerges:尽早发现重复、越界、重叠的合并单元格。auto_fit_columns:当文件没有明确列宽时,按内容测量兜底。
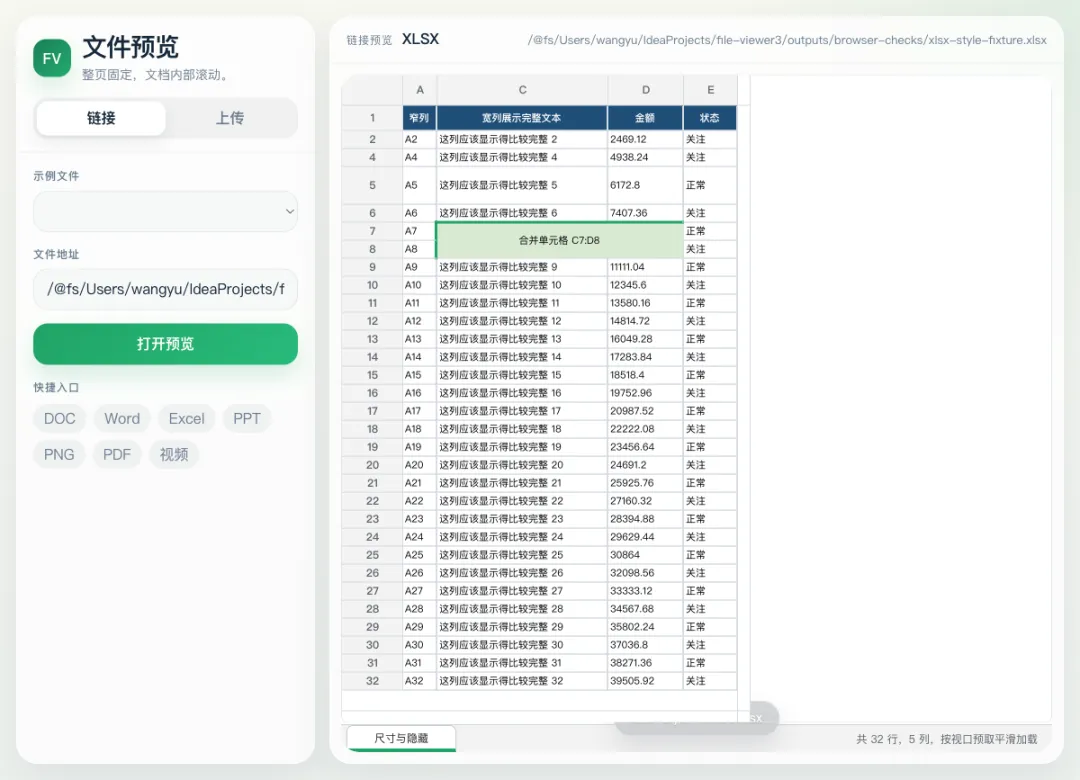
这里有个很真实的取舍:如果 Excel 明确给了列宽,我们尊重原始列宽;如果没有,再用内容测量兜底。否则合并标题、长文本、说明列很容易反向撑开整张表,让报表结构变形。
合并、边框和文本溢出,是最磨人的细节
Excel 的视觉规则里,有几个点特别容易把人磨到没脾气。
第一是合并单元格。
合并信息不能跟着 500 行窗口一起切片。如果一个合并区域跨窗口,窗口内才知道它的局部信息,渲染就会残缺。所以现在合并单元格和列宽属于整表级结构信息,会在第一个窗口下发并缓存。
第二是边框。
相邻两个单元格都有边框时,如果直接各画各的,边框就会变粗。现在渲染层会做一个简单的边框折叠判断:相邻边框比较宽度和样式优先级,只保留更应该显示的那一条。
第三是文本溢出。
很多 Excel 报表并不是靠“自动撑宽列”完成排版的,而是允许文本溢出到右侧空白单元格里。我们后来专门补了这层逻辑:普通文本在不换行、不收缩、不是数字的情况下,如果右侧连续空白,就允许它像 Excel 一样向外延展。
这些细节很小,但它们决定了用户看到的是“一个数据表”,还是“我的 Excel”。
大数据优化:不要让百万行真的进入页面
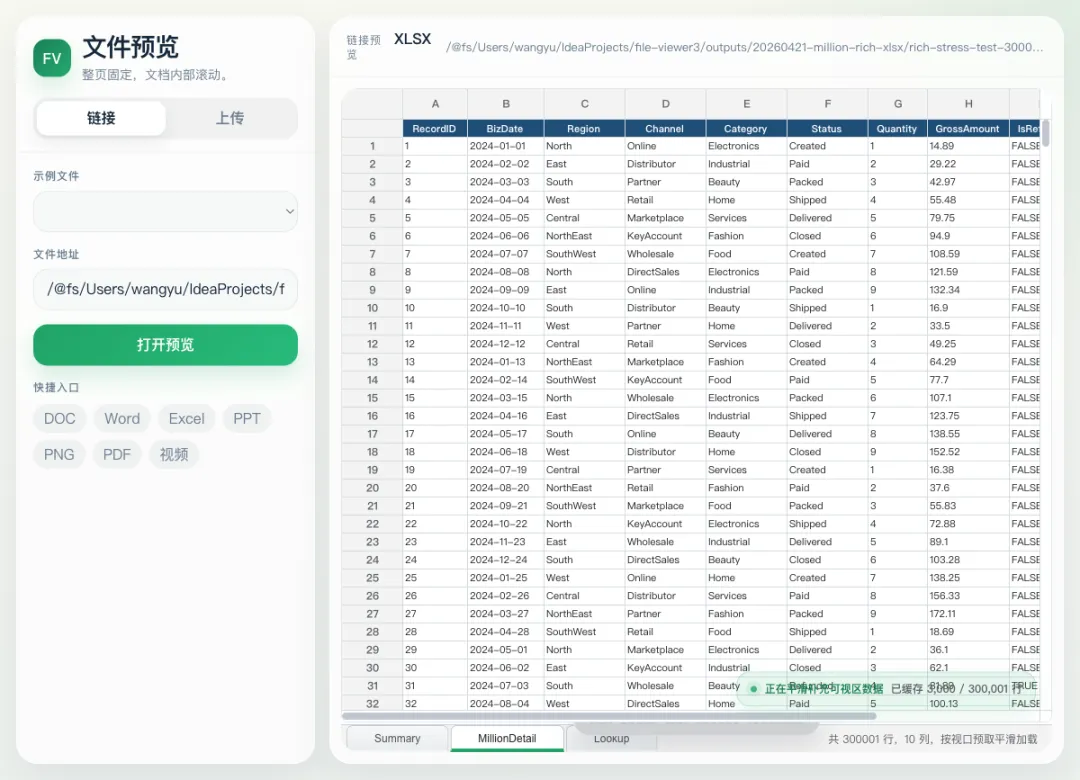
这次性能优化里,最重要的是虚拟数据模型。
我们把每个工作表抽象成一个稳定的虚拟状态:
exportconstWINDOW_SIZE = 500exportconstPREFETCH_AHEAD = 3exportconstPREFETCH_BEHIND = 1每次只请求当前视口附近的窗口。滚动向下时,提前加载下面几个窗口;滚动向上时,也保留身后的热窗口。用户拖动滚动条时,计算当前可视区,再把对应窗口交给 worker。
更关键的是:行对象不反复销毁重建。
已经创建过的虚拟行会被复用,只把当前窗口的数据回填进去。这样做有两个好处:
表格内部缓存稳定,不会因为换一批行对象就重新抖动。 已经读取过的窗口直接命中缓存,切回来不会再次空白。
这其实是整个体验改善最大的地方。大文件预览最怕“我明明刚刚看过,怎么回来又没了”。缓存不是锦上添花,它是大文件体验的底座。
实测数字
测试环境:
设备:Apple M4,32GB 内存,10 核 CPU 系统:macOS 26.4.1 Node:v25.2.1 数据:14.27MB 富样式 Excel,3 个工作表,主明细表 300,001行 ×10列依赖: styled-exceljs@0.21.1,e-virt-table@1.3.25

6.8s | |
7.1s | |
558ms | |
0-1ms | |
2.8s | |
631MB |
这些数字并不想证明“已经没有成本了”。
相反,它们说明了一个现实:富样式 Excel 的解析本来就贵。真正能优化的是把成本放到合适的位置,把主线程从沉重的同步工作里解放出来,让用户看到内容之后,每一次滚动、切换、回看都尽量轻。
如果你也在做 Excel 预览
一些这次踩坑后沉淀下来的建议,可能对你有用:
不要用 DOM 直接承载超大表格,哪怕只是一开始看起来方便。 样式读取和渲染模型要分开,不要让解析库直接决定 UI 结构。 列宽、行高、合并、隐藏这些结构信息要整表缓存,不能跟着分页数据一起丢。 行对象引用要稳定,虚拟滚动组件通常很依赖这一点。 已加载窗口必须缓存,回滚时重新请求会严重破坏信任感。 复杂边框、单元格级对齐、文本溢出可以只在可视区做覆盖层,不要全量 DOM 化。 Loading 不要变成惩罚。首屏可以有明确加载态,后续补窗口只需要温和提示。
最后也想诚实地说一句:在纯前端里做 Excel 预览,永远不可能轻松。
如果目标是“像 Excel 一样处理所有情况”,那会是一个很长的工程。图片、图表、公式计算、条件格式、打印布局,每一个展开都是新世界。
但如果我们的目标是:让大多数真实业务 Excel 能打开、能滚动、能看懂、尽量像原文件,并且不把浏览器拖死,那这条路是走得通的。
写在最后
这次优化做下来,最深的感受不是某个库终于换对了,也不是某个参数终于调好了。
而是很多体验问题,背后都不是“一个 bug”。
滚动空白不是一个 bug,是数据窗口和缓存模型没有想清楚。
列宽不对不是一个 bug,是解析层没有拿到足够接近 Excel 的尺寸语义。
边框变粗不是一个 bug,是浏览器绘制模型和 Excel 视觉模型不一样。
用户说“很难受”,很多时候不是在挑剔。他只是把我们没处理好的复杂度,真实地感受到了。
所以这篇文章想分享的也不只是实现方案。
更想说的是:如果你也在做这种看起来普通、做起来很深的功能,不要太快怀疑自己。很多时候不是你写得不够努力,而是问题本来就有一层又一层。
慢慢拆开,一层一层放回它该在的位置。
浏览器里的 Excel,也会一点点安静下来。
