 夜雨聆风
夜雨聆风作为一名天天跟服务器、命令行、报错日志打交道的生物信息工程师,从个人视角学习Briefings in Bioinformatics近日发表的一篇生物信息学LLM Agent综述文章。

我不关心大模型参数量有多大,我只关心一个问题:这玩意儿能不能替代我写那些繁琐又高度重复的pipeline脚本?能不能在半夜跑流程报错时,自己把问题解决了,而不是直接挂掉?
基于这个工程落地的标准,我把这篇60多个生信LLM Agent的盘点,翻译成了生信工程师的内部复盘。
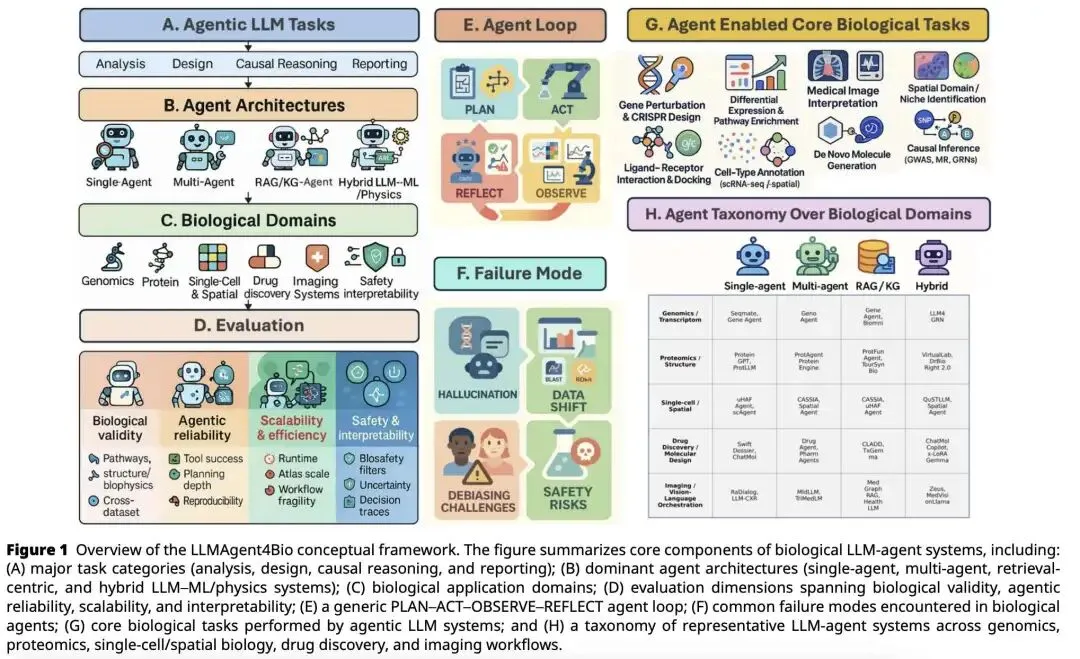
用工程语言重新定义LLM Agent
别被“智能体”这个词忽悠了。在生信工程师眼里,现在所谓的LLM Agent,本质上就是一个“带异常处理机制和自然语言接口的自动化工作流引擎”。
以前我们用Snakemake或Nextflow写流程,是“硬编码”的逻辑树:A步骤输出作为B步骤输入,报错了就停机发邮件。
现在的LLM Agent,把这个逻辑树变成了一个状态机。这篇综述里提到的四个组件,翻译成工程语言就是:
Task(目标):需求文档。 Tools(外部工具):Conda环境里的可执行文件(如hisat2, samtools)或Python包(如scanpy)。 Control Loop(控制循环):Plan-Act-Observe-Reflect,本质上就是一个巨大的 try-except块。它去读stderr,分析报错原因,修改参数,重新subprocess.run()。LLM(大脑):一个不太稳定但能看懂人类语言和报错日志的“调度器”。
所以,它不是在取代生信工具,而是在取代“写调度脚本和查StackOverflow的这个动作”。
架构选型:什么场景该用什么架构?
文章把Agent分成了四类,作为架构设计,我这么理解它们的适用边界:
1. 单线程脚本模式
本质:相当于让LLM写了一个长篇Bash脚本,串行执行。 适用:RNA-seq等极其成熟、容错率低、seldom 需要人工干预的标准分析(如 SeqMate)。工程师评价:可控性最强,但灵活性最差。跟我直接写个Shell脚本没多大区别,只是输入变成了自然语言。
2. 微服务/多角色编排模式
本质:模拟课题组分工,相当于微服务架构。PI节点负责任务拆分,Coder节点写代码,Reviewer节点做输入输出校验(Schema验证)。 适用:空间转录组、药物发现这种工具链长、异构数据多、中间需要大量人工判断的场景(如 CASSIA,DrugAgent)。工程师评价:思路是对的,拆解了复杂度。但引入了极大的通信开销和上下文丢失风险,某个子Agent如果理解偏了,错误会被放大。
3. RAG挂载模式
本质:LLM + 本地向量数据库(如Chroma/FAISS)。 适用:基因功能注释、临床知识问答。不产生新的计算结果,只做知识抽取。 工程师评价:最实用的模式。生信分析里查基因、查通路太费时间了,只要它的检索召回率够高,绝对的好帮手。
4. Wrapper封装模式 (Hybrid LLM-ML/Physics)
本质:LLM当API网关,底层调用AlphaFold、分子对接引擎等重型GPU任务。 适用:蛋白结构预测、小分子生成。 工程师评价:LLM在这里纯属“虎皮”,干活的还是传统深度学习模型,LLM只是把用户的自然语言翻译成了配置文件。
落地评估:各领域的“自动化成熟度”
从工程落地的角度,我给目前的几个赛道打个分:
基因组/RNA-seq(成熟度:高):这是最好自动化的,因为底层工具(FastQC到DESeq2)太稳定了,输入输出格式极其标准。Agent在这里很容易做到“开箱即用”。 单细胞/空间组(成熟度:中):痛点明显,因为Scanpy/Seurat的参数多如牛毛,不同的组织、降维方法跑出来结果差异极大。Agent在这里最大的价值是做“参数网格搜索的解释器”。 蛋白/药化(成熟度:低):文章吹得很凶,但看看 Virtual Lab的数据(92个设计只验证了2个),就知道这离真正的高通量工业级筛选还差得远。底层物理引擎的计算代价太高,容不得LLM在上面瞎试错。
避坑指南:为什么我现在还不敢把它扔到生产服务器上?
作为要对最终数据负责的人,这篇综述提到的几个Failure Modes简直直戳我的大动脉。如果现在要让Agent上生产环境,必须解决以下硬伤:
1. 致命的“错误级联”这是最可怕的。生信流程最讲究“垃圾进,垃圾出(GIGO)”。如果第一步比对因为Agent传错了参数导致BAM文件是空的,但它没有做文件大小/格式的硬性校验,它就会硬着头皮去跑下游的定量、差异分析。最后它会给你生成一份格式完美、图表精美的报告,但结论全是假的。工程解法:必须在每个Act之后,强制加入硬编码的断言检查,而不是靠LLM自己“反思”。
2. 幻觉在生信里的特殊表现在生信里,幻觉不是胡说八道,而是“伪造文件路径”和“编造不存在的包名”。它可能会调用一个根本没安装的Bioconductor包,或者引用一个不存在的参考基因组路径。工程解法:限制Agent的执行环境,做好环境隔离,不能让它随便 pip install。
3. 彻底丧失“可复现性”生信文章发不出去,很多时候是因为复现不出来。现在这些Agent底层调用GPT-4,每次生成的代码逻辑、选用的参数都不一样。今天跑出一个显著性基因,明天跑可能就没了。工程解法:必须固化Prompt模板,甚至在达到稳定效果后,将Agent生成的代码“硬化”为传统的Python脚本,彻底抛弃LLM层。
工程师的行动指南
看完这篇综述,我的结论很明确:LLM Agent现在是个好用的“原型验证工具”,但绝不是一个合格的“生产环境组件”。
作为生信工程师,我们的饭碗不会被抢走,但我们的工作重心必须转移:
从“写代码”转向“写约束”:以后写代码的时间变少了,写YAML配置文件、写系统Prompt、定义输入输出Schema的时间变多了。我们要成为给Agent立规矩的人。 掌握工具编排能力:别光盯着LangChain,去看看怎么用Python把现有的生信命令行工具包装成标准API,这是接入Agent的前置条件。 守住“数据校验”的底线:不要相信Agent的判断,所有的中间文件(FASTQ, BAM, h5ad)的质量控制,必须保留传统生信脚本的硬校验逻辑。
总而言之,别指望它替你想生物学意义。把它当成一个不知疲倦但经常犯迷糊的初级程序员,你负责架构设计和最终Code Review,它负责干脏活累活。这才是现阶段生信Agent最合理的用法。
一些有用的学习资源:
