 夜雨聆风
夜雨聆风上一个计费周期在凌晨四点Claude刷新周额度时结束了:在Max(20X)订阅下,用量最终达到了94%;Gemini CLI偶尔会遇到限额;Codex还有一些剩余额度。因此,以每月不到1000美元的成本来运营一个完全由AI自主运行的研究院,目前看来仍然是非常可行且有吸引力的。
这是研究院运行以来的第三个周五,鉴于最近不少朋友询问我的日常工作模式,我在此做一个小结。
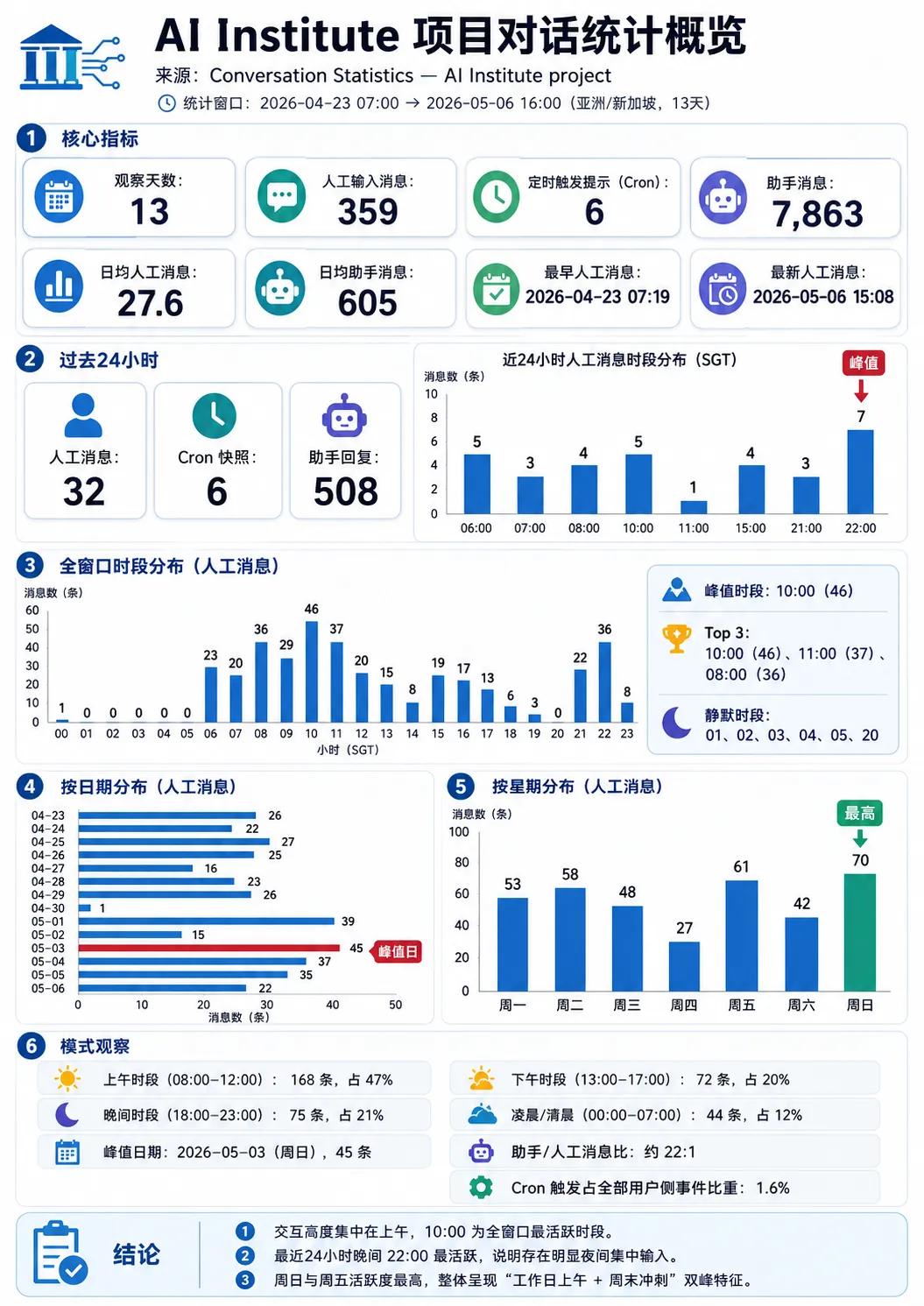
我的典型工作状态是同时开启三个项目窗口,以及若干个命令行窗口来处理其他部分的生成工作。下图展示了【AI研究院】项目在一个13天观察期内的统计数据,基本反映了我的工作方式。
日志、方案、数据库:我的三道安全阀门
自从4月23日将这个项目的主导权从Gemini交接给Claude Code后,项目进展超出了我的预期。系统运行数据的统计结果(如上图所示,虽然图片未提供,但内容有所描述)揭示了我在工作模式和与模型交互上的新特点。
工作时间与模式
我的工作高峰期集中在上午和晚上,但内容各有侧重:
●清晨 (6点-8点):主要任务是检查系统状态、查看隔夜任务的执行结果,并安排修复已发现的bug。
●午饭前 (10点-11点多):集中精力开发新功能。
●晚上:较少新增功能,更多是梳理问题和安排任务,为第二天的醒来后的工作做准备。
人机交互特点
●模型回复的消息数量远超我输入的消息数量,并且预计这个比例还会继续增加。
●我已开始设置Cron任务,用于系统监测、功能修正和定时运行报告的生成。
项目偏好与系统成熟度
与以往偏好用Gemini进行长时间迭代和循环任务不同,如今我的任务多为短时,白天基本不超过半小时。这得益于系统主干骨架已成型,大部分批量自动化任务已交由系统自动完成,我主要关注找bug和找灵感。
我非常欣赏Claude Code的“Remote Control”功能,它允许我在多设备上无缝衔接交互,这为我在咖啡馆、运动场所或街道上寻找灵感提供了极大的便利,并在心理上带来了积极影响。
AI Coding时代的安全阀门
尽管我对项目进展满意,但我从项目伊始就做了充分的准备,并将其视为对“AI泡沫论”的一次直接测试。一个需要稳定可靠、长时间运行的系统,其关注点与社交媒体上的Demo大不相同。
在AI Coding时代,系统的管理依然围绕着上下文(Context)和数据库(Database)展开,这构成了我的日志、方案、数据库三道安全阀门。
1.上下文管理:核心挑战
无论是从最早的Prompt到如今的harness和skills,核心都是解决上下文问题。模型本身没有记忆,需要通过每次对话输入足够信息,让其“看起来有记忆”。虽然许多模型宣称上下文长度已达1M tokens,但实际应用中,真正高效的上下文能力可能仍难以超越128K。对于一个代码量轻松上万行的系统,这大大超出了模型单次处理的能力。
Claude Code等Agent架构通过不仅仅依靠CLAUDE.md,更是在默认路径下进行精细的上下文和记忆管理,提供了一种优秀的解决方案。然而,以下情况仍会带来问题:
●开发环境变化:模型在感知环境变化后,有巨大的“冲动”去修改已运行代码,可能造成灾难。
●功能快速增加:上下文的前后覆盖和混乱,常导致正确的代码被错误修改,且难以恢复。
●意外因素:网络、硬件故障或模型额度耗尽等,如果用户没有“保护现场”的意识,项目可能难以恢复。
最基本的前提:代码库与版本控制
这是最基本的前提:一旦开始构建系统,而非编写程序,就必须坚持使用Git进行代码库管理,并不断提交(commit)和推送(push)正确的版本,以确保出现错误时能回退到上一个正确的状态。
2.第二道安全阀1:日志(Logs)
日志是将所做工作记录下来。除了工具/Agent自身的记录外,人工需要主动记录以下关键信息:
●新功能完成后的功能说明。
●系统作出重大改进后的系统架构整理。
●问题和bug修复记录。
●接口文档。
●每日总结。
日志的作用:
●架构:便于用户检查模型输出的大体正确性。
●学习:各种文档是未来让模型“系统学习”的可靠指引。
●实验:接口文档暴露了重要功能接口,方便在项目之外另开窗口进行新功能实验。
3.第二道安全阀2:方案(Proposal)
尽管开发工具提供规划(planning)功能,但有时会“过度思考”导致方案与实际落地有差距。我的做法是,每次提出一个问题或想要的功能时,将已记录的日志文档加入上下文,让模型提供方案(proposal),并将其写成文档。
方案的好处:
●异步开发:想法初现时,立即让模型生成proposal文档,对当前主线上下文影响小,避免因想法过多干扰主线任务。
●可行性评估:方案被记录后,易于评估对现有系统的影响和可实现性。
●并行开发:通过这种异步方式,许多功能得以在dry-run或计划阶段并行推进,并在重要功能更新时,让模型回顾并修改这些proposal,实现高效可靠的并行开发。
最终目的:在发生非数据库层面的灾难时,能让模型按顺序阅读这些文档,而非依赖其自身的记忆,从而使系统尽快恢复。
4.第三道安全阀:数据库,尚未解决的挑战
AI Coding时代,数据库的重要性日益凸显,它不仅包含传统的增删改查,还涉及对象存储、KV Cache、向量数据库等。作为一个拥有超过二十年DBA背景的人,我目前仍未找到一个完美的解决方案,只能在意识上尽可能避免灾难发生。
AI对数据库操作的风险与挑战
目前,尽管AI在代码编写方面已取得进展,但在数据库的管理和维护上仍存在严重不足。在系统开发中,数据库是区分演示(demo)和生产环境的核心标志,因为它承载着真实的业务数据。数据库不仅是技术问题,更是业务的体现,这也是DBA(数据库管理员)的价值往往高于普通程序员,甚至成为架构师必备技能的原因——DBA需要理解业务逻辑,而业务往往带有非逻辑性和特殊性。真实的数据库结构是业务需求和性能考量多方妥协的结果,即使AI从零构建系统也无法避免这些复杂性。
当前AI模型或Agent对数据库的操作存在以下高风险行为:
1.随意修改表结构:缺乏对业务和数据结构的深层理解,可能导致结构不稳定。
2.随意设置主键、外键:不当的约束设置会影响数据完整性和系统性能。
3.倾向于全表重写:在程序变动后,AI倾向于“删库重来”,而不是进行精确的修改。
4.环境误判导致混乱修改:一旦对系统环境定位错误,可能对数据库进行不可逆的破坏性修改。
5.性能低下:AI编写的系统在不断修改中,表结构可能变得混乱,查询操作简单粗暴,导致性能极差。
过去,我曾多次因AI在改进过程中不慎破坏数据库而不得不重头开始项目。在传统人工开发时代,尽管有备份和恢复机制,数据破坏后的恢复也因头绪繁多和数据不平衡而耗时费力;而在AI时代,代码生成效率过快,进一步加剧了这种不平衡,使得检查和恢复难度大幅提高。
为了规避数据库风险,即使在AI能力显著提升的今天,开发者仍需保持警惕并采取预防措施。例如,加强如下约束:
●尽量使用小表,避免AI生成大表。
●放弃外键,简化结构。
●只建新表,不轻易删除旧表。
●在扩展字段前,进行仔细检查。
●最重要的是,少做表设计,宁可牺牲部分性能,也要保证未来的稳定性。
在当前的系统开发和维护中,人工投入精力最大的仍是数据库环节。由于代码和库表结构高度耦合,人工直接修改表结构已不可行,重点在于进行性能优化,尤其是SQL调优。通过模型辅助(在明确指出问题时AI表现良好)进行了一次大规模的检查和优化,成功地在系统任务量和数据量显著增长的情况下,将数据库读写次数维持在低水平,大幅提升了系统响应速度。
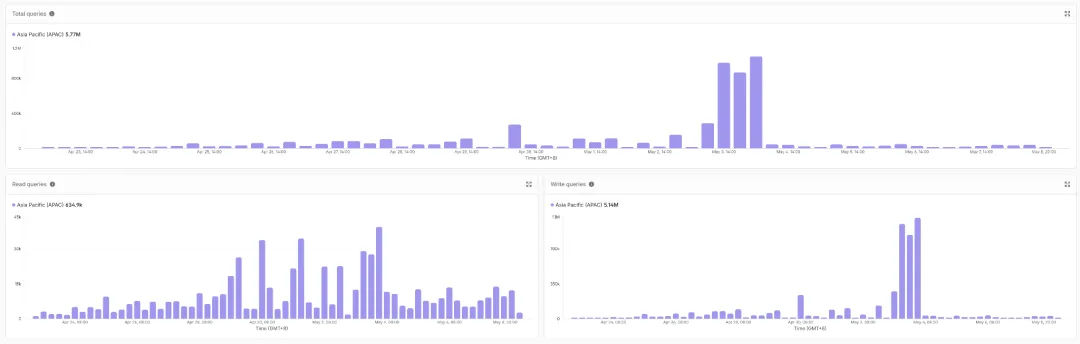
五月初的那几天,系统确实经历了最大的考验,各种问题集中爆发。最终,我们依靠底层的调度和数据库操作优化才得以解决。当然,与二十多年前的那些“关键时刻”相比,这次的规模不值一提。
我将日志、方案(提案)和数据库视为自己的“安全阀”,与其说是约束(harness),我更喜欢称之为安全阀。它们是我的定心丸,有了它们,我反而能更放心地信任模型和Agent,让它们大胆去尝试。
在这三道安全阀中,数据库无疑是最核心的。什么时候Agent能够真正掌控数据库,我们也许就离真正的生产应用不远了。但我深知,这一步并非朝夕之间能完成。程序设计的经验可以从数据、从用户日常的连续操作中习得,但数据库的“决策点”往往依赖于经验和业务背景知识,这些信息是隐性的,并不直接存在于数据之中。
这也是众多企业AI转型和落地过程中最重要的分水岭:企业何时能让AI接管核心业务数据库。据我观察和了解,即使是顶尖的科技巨头,离这一步也还有很长的路要走。原因有二:一是经验丰富的DBA手中掌握着大量自动化运维工具和脚本(编写脚本甚至是DBA最核心的技能和执念),效率已然非常高;二是,一旦发生数据库事故,责任由谁来承担?
然而,如果这一步跨不过去,AI转型就无从谈起。只要一套AI系统无法妥善解决数据库问题,它就永远只能停留在演示(demo)阶段。
