 夜雨聆风
夜雨聆风
近日,AI 研究者 Nathan Lambert(Interconnects AI 创始人、前 Ai2 研究员)结束了他的中国之行,写下了这篇观察笔记。在从杭州驶往上海的高铁上,他望着窗外连绵的山脊,上面点缀着风力发电机,在落日余晖中勾勒出剪影。群山之下,是一望无际的田野和拔地而起的高楼。他说,从中国回来后满怀敬意。去到一个如此不同的国度,却受到如此热情的欢迎,这是一种非常温暖、非常真实的人与人之间的体验。
中国的语言模型公司天然就是优秀的快速跟进者。这得益于教育和工作中的文化传统,以及构建科技公司的微妙差异。如果你只看产出——最新、最大的模型驱动着智能体工作流——以及投入——优秀的科学家、大规模数据和强大的算力——中美实验室看起来非常相似。真正持久的差异,在于这些要素如何被组织和调配。
Lambert 一直觉得中国实验室之所以能如此出色地追赶并紧跟前沿,一部分原因在于他们的文化天然适配这项任务。但在没有跟当事人直接交流之前,他总觉得不太适合把这种直觉当作重要结论来讲。这次与众多优秀、谦逊、坦诚的中国顶尖实验室科学家交流后,他之前的很多判断都变得更加清晰了。
如今,构建最好的 LLM 在很大程度上取决于从数据到架构细节再到 RL 算法实现的全栈精细打磨。模型的每一个环节都可能带来改进,而将它们整合在一起是一个复杂的过程——一些天才个体的工作有时需要被搁置,以服务于整体模型的多目标优化。
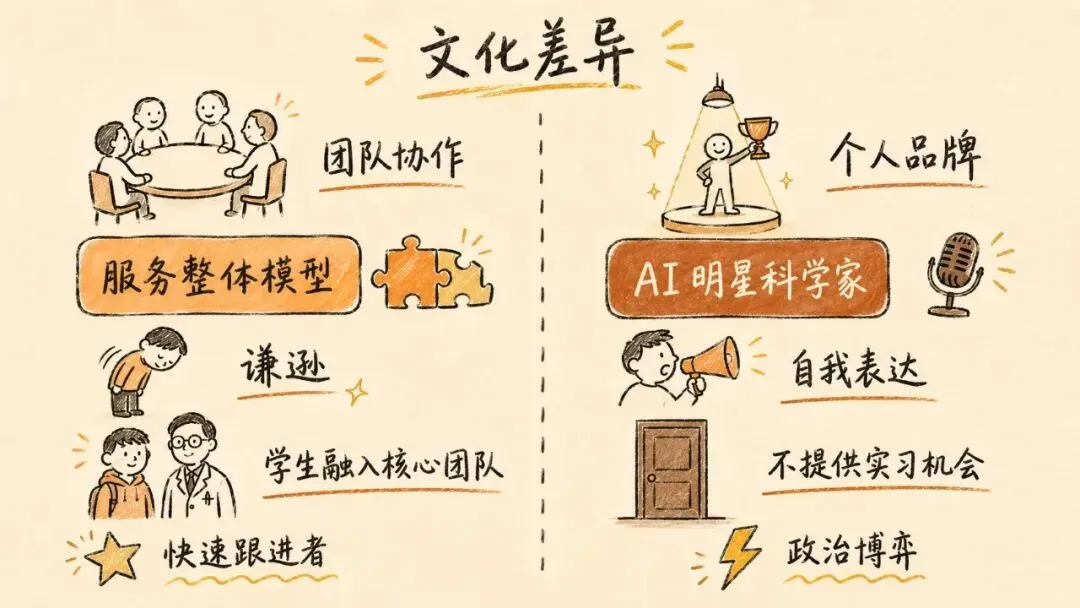
美国研究者在解决各个单点问题上同样极其出色,但美国文化中更鼓励为自己发声。作为科学家,你越会替自己的工作"站台",就越容易成功,而当下的风潮更是催生了一条新的成名之路——"AI 明星科学家"。这不可避免地导致冲突。Llama 团队据传就是在这种政治博弈的重压下分崩离析的。Lambert 还听说有的实验室不得不额外补偿顶尖研究员,才能让他们停止抱怨自己的方案没被最终模型采纳。不管这个说法是否完全属实,道理是明摆的:自我意识和对个人职业发展的追求,确实会妨碍做出最好的模型。中美之间在这种文化上哪怕只有微小的方向性差异,都可能对最终成果产生实质性影响。
这也与中国模型的构建者群体有关。在所有实验室里,一个直观的现实是:核心贡献者中有很大比例是在读学生。这些实验室都很年轻,这让 Lambert 想起了他在 Ai2 的团队结构——学生被视为同行,直接融入 LLM 团队。这与美国顶级实验室的做法截然不同——OpenAI、Anthropic、Cursor 这些公司根本不提供实习机会。Google 名义上有与 Gemini 相关的实习岗位,但普遍的担忧是你的实习会被隔离在边缘项目,接触不到真正核心的东西。
总结一下,这种文化上的微妙差异如何提升构建模型的能力:
• 更愿意做那些不起眼但能提升最终模型效果的工作, • 新人没有经历过之前 AI 炒作周期的包袱,能更快地适应新技术(事实上,有一位中国科学家在交流中就特别强调了这个优势), • 个人意识更淡薄,组织架构更容易扩展,因为大家更少去博弈体制, • 充沛的人才非常擅长在已有概念验证的基础上解决问题。
这种天然适配当下语言模型构建的倾向,恰好与一个广为人知的刻板印象形成对照:中国研究者在开创性的、从0到1的学术型研究上产出较少。在此行偏学术性的实验室访问里,许多负责人都谈到了如何培育更有雄心的研究文化。与此同时,一些技术领导者对这种科研方式的转变能否在短期内实现持怀疑态度,因为这需要对教育和激励体系进行根本性的重新设计,其规模之大在当前的经济平衡下难以实现。现行文化培养出的学生和工程师,在 LLM 构建这件事上确实非常出色——而且他们的数量极其充裕。
这些学生也告诉 Lambert,中国正在发生与美国类似的人才流失——许多原本考虑走学术路线的人,现在打算留在工业界。最有趣的一句话来自一位对当教授感兴趣的研究者,他想贴近教育体系,但随即感慨道:教育问题已经被 LLM 解决了——"学生干嘛还要来找我聊!"
学生们的优势在于能用全新的眼光看待 LLM。过去几年,LLM 的核心范式从扩展 MoE,到扩展 RL,再到实现智能体,经历了多次转变。要在任何一个方向上做好,都需要极速吸收海量的上下文信息,既包括广泛的文献,也包括公司内部的技术栈。学生们习惯于这样做,而且他们乐于谦虚地放下一切关于"什么应该有效"的先入之见,一头扎进去,倾注全力争取改进模型的机会。
这些学生还有一种令人惊讶的直接,不会被那些可能分散科学家注意力的哲学讨论所干扰。当 Lambert 问及他们对模型的经济学影响或长期社会风险的看法时,相比之下,极少有中国研究者对此有深入的见解或想要施加影响的动力。他们的角色就是做出最好的模型。
这种差异是微妙的,很容易被否认,但当你与一位优雅、聪慧、英语流利的研究者长谈时,最能感受到这一点——关于 AI 哲学层面的基础问题悬在空中,对方露出的是一种单纯的困惑。对他们来说,这属于认知偏差。有一位研究者甚至引用了 Dan Wang 的著名论点——中国是工程师在治理国家,而美国是律师在治理——来强调他们对"造东西"的渴望。在中国,并不存在一条系统性的路径来打造科学家的明星效应,也没有类似 Dwarkesh 或 Lex 这种能把科学家推向主流大众的超级播客。
试图让中国科学家评论 AI 引发的经济不确定性、超越简单 AGI 能力范畴的问题、或者模型行为的道德争论——这些尝试恰恰也说明了这些科学家高度专注、深度投入的工作习惯。他们对工作极其投入,而对偏哲学层面的宏大议题关注较少。
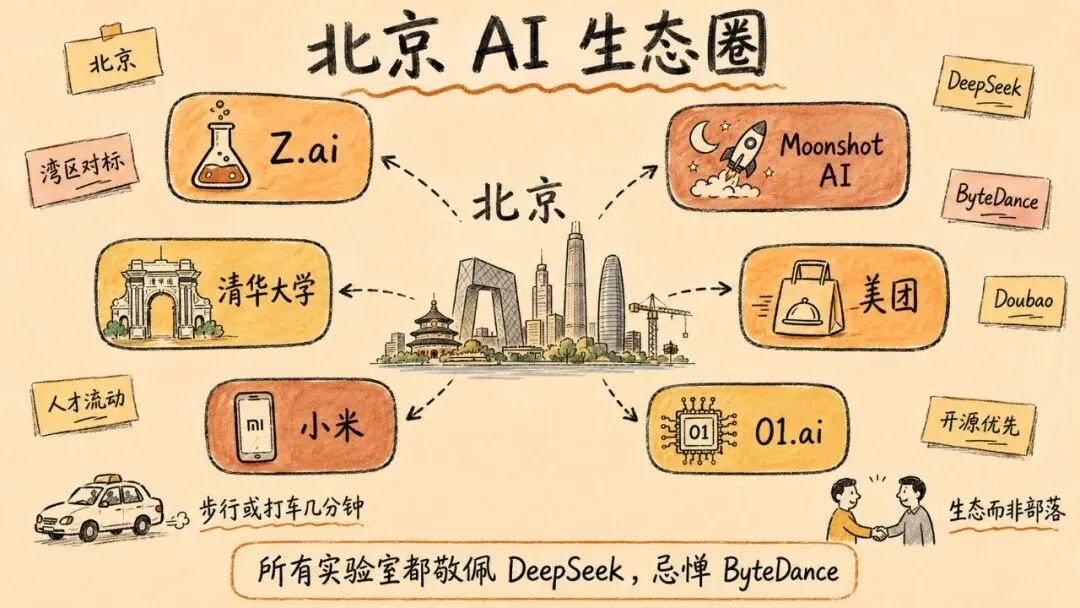
往大了说——北京给人的感觉很像湾区,一家竞争对手的实验室可能就在步行或打车几分钟的距离。Lambert 一下飞机,去酒店的路上就顺道去了 Alibaba 的北京园区。然后在 36 个小时内,他们走访了 Z.ai、Moonshot AI、清华大学、Meituan、Xiaomi 和 01.ai。打 Didi 出行很方便,如果在中国叫一辆大车,经常配到带按摩椅的纯电 MPV。他们向研究者们问起人才争夺战,研究者们说跟美国的情况非常相似。研究者跳槽是常态,大家选择去哪里,很大程度上取决于当前的氛围和感觉。
在中国,LLM 社区更像是一个生态系统,而不是彼此竞争的部落。在许多私下交流中,大家对同行只有尊重。所有中国实验室都忌惮 ByteDance 和他们备受欢迎的 Doubao 模型,ByteDance 是中国唯一的前沿闭源实验室。同时,所有实验室都对 DeepSeek 怀有深深的敬意,认为他们是研究品位和执行力最好的实验室。DeepSeek 指明方向,其他人跟进。但在美国,私下跟实验室成员聊天时,火药味很快就上来了。
中国研究者谦逊态度中最令人印象深刻的一点是,他们经常对商业层面的问题耸耸肩,说"那不是我操心的事"——而在美国,似乎所有人都对各种生态级别的产业趋势如数家珍,从数据供应商到算力再到融资。
中国 AI 产业的异同
如今构建 AI 模型之所以如此有趣,在于它不再仅仅是把一群优秀研究者聚在一栋楼里做出一项工程杰作。以前确实是这样,但要维持 AI 业务的可持续性,LLM 正在变成构建、部署、融资和获取用户等环节的综合体。领先的 AI 公司存在于复杂的生态系统中,需要资金、算力、数据等多方面的输入来持续推动前沿。
对于以 Anthropic 和 OpenAI 为代表的西方生态系统,这些要素的整合已经被充分概念化和梳理清楚了。因此,找到中国实验室在思路上的重大差异,就能发现不同公司可能正在对未来做出截然不同的押注。当然,这些未来走向在很大程度上受到资金和算力约束的支配。
以下是 Lambert 与这些实验室交流后,在"AI 产业"层面总结的最大收获:
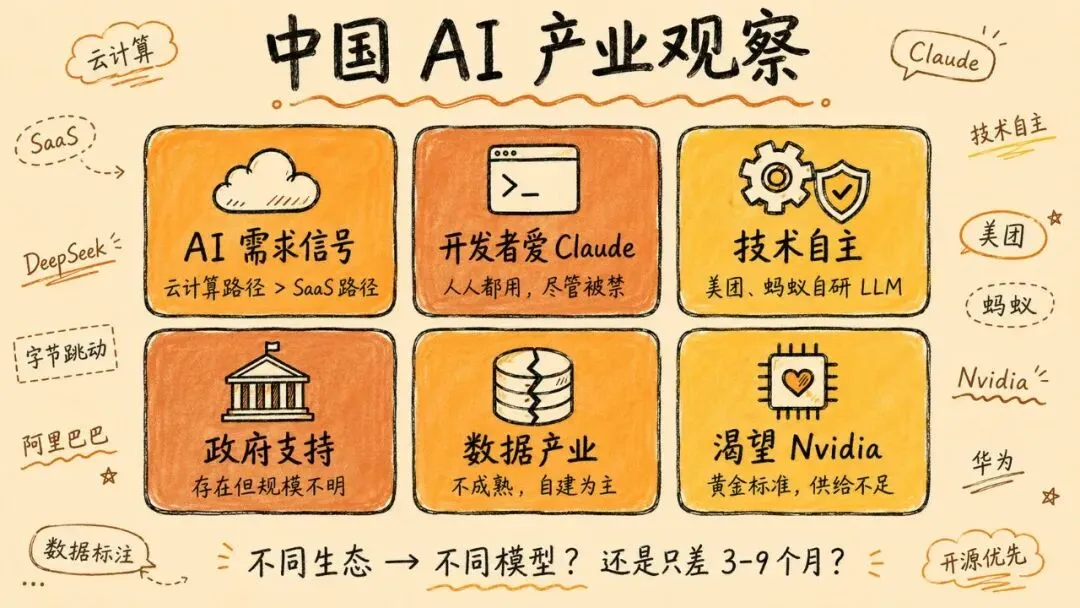
1. 国内 AI 需求的早期信号。 有一个广为流传的假设:中国 AI 市场会比较小,因为中国企业不习惯为软件付费——因此永远无法催生一个支撑实验室的大规模推理市场。但这个说法只适用于对应 SaaS 生态的软件支出,SaaS 在中国历史上确实很小;而另一方面,中国显然有一个庞大的云计算市场。一个尚未回答的关键问题——也是中国实验室内部自己在争论的——是企业的 AI 支出会跟随 SaaS 市场(很小)还是云计算市场(基础性的)。总的来看,AI 似乎更趋向于云的路径,没有人在积极担忧围绕新工具的市场是否能发展起来。 2. 大多数开发者对 Claude 着迷。 中国的大多数 AI 开发者都痴迷于 Claude 以及它对软件开发方式的颠覆,尽管 Claude 在中国名义上是被禁止使用的。中国历史上不太愿意为软件付费这一点,并没有让 Lambert 觉得未来的推理需求不会出现爆发式增长。中国技术人员是如此务实、谦逊和有干劲——这种特质似乎比任何"不花钱买软件"的旧习惯都更有力。一些中国研究者提到会用自己的工具来开发,比如 Kimi 或 GLM 的命令行工具,但所有人都提到会用 Claude。令人意外的是,很少有人提到 Codex,而 Codex 在湾区的热度明显在飙升。 3. 中国企业有很强的技术自主意识。 中国的文化正在与蓬勃的经济引擎结合,产生出难以预测的结果。给 Lambert 留下最深刻印象的是:这些 AI 模型反映的是各家科技企业在当下的务实选择,并非什么宏大规划。这个行业的格局是:ByteDance 和 Alibaba 作为巨头,被普遍认为会凭借雄厚资源赢得大部分市场,受到行业尊重。DeepSeek 是公认的技术领导者,但远非市场领导者。他们指引方向,但并非为了在商业上取胜。这就催生了像 Meituan 或 Ant Group 这样的公司——西方人可能会惊讶于他们也在自己构建模型。但实际上,他们认为 LLM 显然将成为未来科技产品的核心,所以必须打好基础。当他们在通用强模型上做微调时,就巩固了自身的技术栈——他们让开源社区提供反馈,同时保留内部微调版本用于自家产品。行业中"开源优先"的心态很大程度上源于务实考量:它帮助模型获得有力反馈,回馈开源社区,也支撑了他们的使命。 4. 数据产业远不如美国成熟。 在了解到 Anthropic 或 OpenAI 为单个训练环境花费超过 1000 万美元、每年累计在推动 RL 前沿上的投入达到数亿美元之后,Lambert 一行很想知道中国实验室是在从美国公司购买同样的环境,还是有一个对等的国内生态在支撑。答案并不是说完全没有数据产业,而是他们的体验是:数据产业的质量相对较差,自己内部构建训练环境或数据往往效果更好。研究者们亲自花大量时间搭建 RL 训练环境,而一些大公司如 ByteDance 和 Alibaba 有内部数据标注团队来支持这项工作。这一切都呼应了上一点提到的自研优先心态。 5. 对更多 Nvidia 芯片的渴望。 Nvidia 算力是训练的黄金标准,所有实验室的进展都受限于 Nvidia 芯片的不足。如果供给充足,他们显然会买。其他加速器,包括但不限于 Huawei,在推理方面获得了正面评价。大量实验室都能使用 Huawei 芯片。
这些要点描绘了一个非常不同的 AI 生态系统。如果简单地将西方实验室的运作模式套用到中国同行身上,往往会产生认知偏差。关键问题是:这些不同的生态系统是否会产出本质上不同类型的模型,还是说中国模型永远只能被解读为美国前沿模型三到九个月前的版本。
结语:全球均衡
Lambert 说,出发前他就知道自己对中国了解甚少,回来后更觉得一切才刚刚开始。中国不是一个可以用规则或公式来概括的地方,它有着截然不同的动态和化学反应。这里的文化如此古老、如此深厚,至今仍与本土技术的构建方式紧密交织。
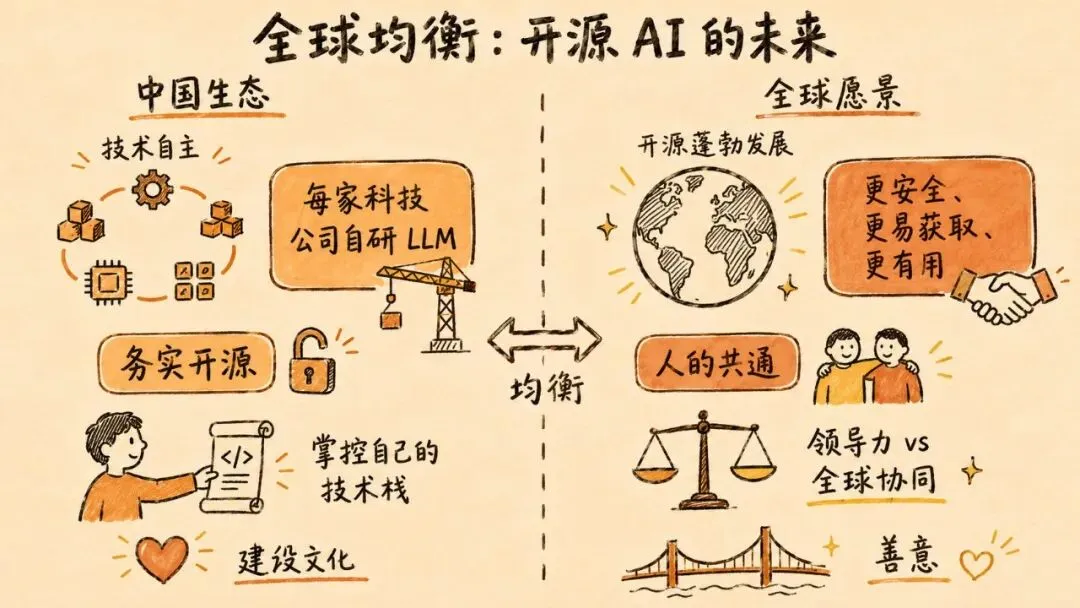
美国当前权力结构中的许多人,把自己对中国的既有认知当作决策的关键依据。在与中国几乎所有领先 AI 实验室进行了正式或非正式的面对面交流之后,Lambert 发现中国有许多特质和直觉,是西方决策框架很难建模的。即便在他直接追问"为什么要把最好的模型开源"之后,技术自主意识与真诚的生态支持之间的交汇,对他来说仍然很难完全说清楚。
这里的实验室务实而非开源原教旨主义者——并不是他们构建的每一个模型都会公开发布——但在支持开发者、支持生态、并将其作为了解自身模型的方式这件事上,有着深层的用心。
几乎每一家中国大型科技公司都在构建自己的通用 LLM——正如 Meituan(外卖平台)和 Xiaomi(综合消费电子公司)都在发布开源模型。如果换成美国的对标公司,他们只会直接采购服务。这些公司构建 LLM,不是为了蹭热点,而是出于一种深层的内驱力——掌控自己的技术栈,掌握当下最重要的技术。当 Lambert 从笔记本电脑上抬起头,总能看到天际线上成群的塔吊,这一切显然与中国更广泛的建设文化和能量融为一体。
中国研究者的人情味、魅力和发自内心的热情,让人深深感受到彼此的共通之处。在个人层面上,美国社会习以为常的那种剑拔弩张的地缘政治话语,完全没有渗透到他们身上。这个世界需要更多这种朴素的善意。作为 AI 社区的一员,Lambert 说他现在更担心的是,以国籍为标签在成员和群体之间出现的裂痕。
他坦言,如果说自己不希望美国实验室在 AI 技术栈的每个层面都稳居领先,那就是在说谎——尤其是在他投入最多精力的开源模型领域——他是美国人,这是一个诚实的偏好。同时,他希望开源生态本身能在全球范围内蓬勃发展,因为这能为世界创造更安全、更易获取、更有用的 AI。现在的问题是,美国实验室是否会采取行动来巩固这一领导地位。
在他写完这篇文章时,又有新的传闻在流传——行政命令可能会对开源模型产生影响,这可能进一步复杂化美国领导力与全球生态之间的协同——这并没有让他更有信心。
最后 Lambert 感谢了他在 Moonshot、Zhipu、Meituan、Xiaomi、Qwen、Ant Ling、01.ai 以及其他机构遇到的所有出色的人们。每个人都非常热情好客,慷慨地分享了他们的时间。他表示会继续分享对中国的思考——无论是文化层面还是 AI 层面。显而易见,这些认知将直接关系到 AI 前沿发展中正在展开的故事。
Notes from inside China's AI labs by Nathan Lambert
