 夜雨聆风
夜雨聆风编者:这是系列文章的第二章。在第一章中,我们了解了 Claude Code 的整体架构。本章将深入最核心的模块 —— QueryEngine,理解它是如何编排与 AI 的完整对话生命周期的。
引子:为什么需要 QueryEngine?
读取了 15 个文件
执行了 8 次 Bash 命令
调用了 3 次 MCP 工具
修改了 5 个文件
压缩消息历史—— 将旧对话总结为摘要,保留关键信息 追踪文件状态—— 记录哪些文件被修改了,用于 Git 归因 管理 Token 预算—— 确保这次调用不会超出你的成本上限 处理权限审批—— 如果 Claude 要调用新工具,需要你的批准 持久化转录—— 将对话保存到本地,以便下次恢复 模型切换—— 如果用户通过斜杠命令切换了模型,需要应用新设置
管理整个对话的生命周期(从用户输入到最终响应)
维护跨轮次的状态(消息历史、文件缓存、使用统计)
触发压缩、预算检查、归因记录等横切关注点
为不同的调用方(REPL、SDK、Headless 模式)提供统一的接口
第一部分:QueryEngine 的角色定位
1.1 QueryEngine 是什么?

消息历史在轮次之间持久化
文件状态缓存在轮次之间保留
TOKEN 使用统计累计
1.2 配置系统

参数分组清晰—— 环境、权限、状态、文件、模型等配置按类别组织 可选参数灵活—— 大部分参数都是可选的,有合理的默认值 函数式状态更新——setAppState接收一个更新函数,而不是直接修改状态,这符合不可变状态的最佳实践
1.3 QueryEngine 的状态管理

消息历史—— 核心状态,每轮对话都会累积
Token 使用—— 跨轮次累计,用于成本追踪
权限拒绝—— 用于向 SDK 报告用户拒绝了多少次工具调用
文件状态—— 缓存文件读取结果,避免重复 IO
技能发现—— 追踪本轮对话发现了哪些新技能
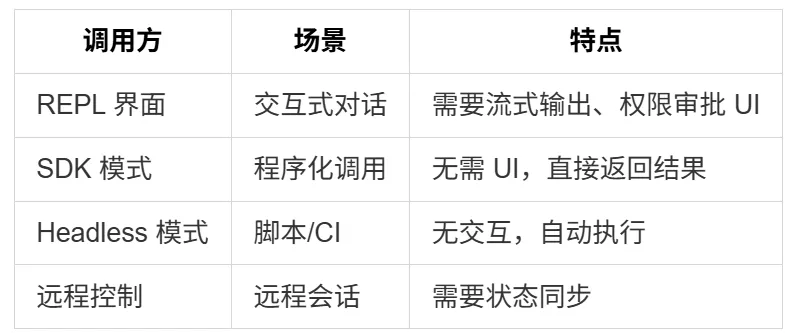
1.4 QueryEngine 的调用方
QueryEngine 不是独立运行的,它被多个调用方使用:

第二部分:消息流转的完整生命周期
2.1 submitMessage 的整体流程
流式输出—— 调用方可以在对话进行中就渲染部分结果
中断支持—— 调用方可以随时停止生成
进度反馈—— 每个关键步骤都可以 yield 进度消息
让我们用一张流程图来展示整体流程:
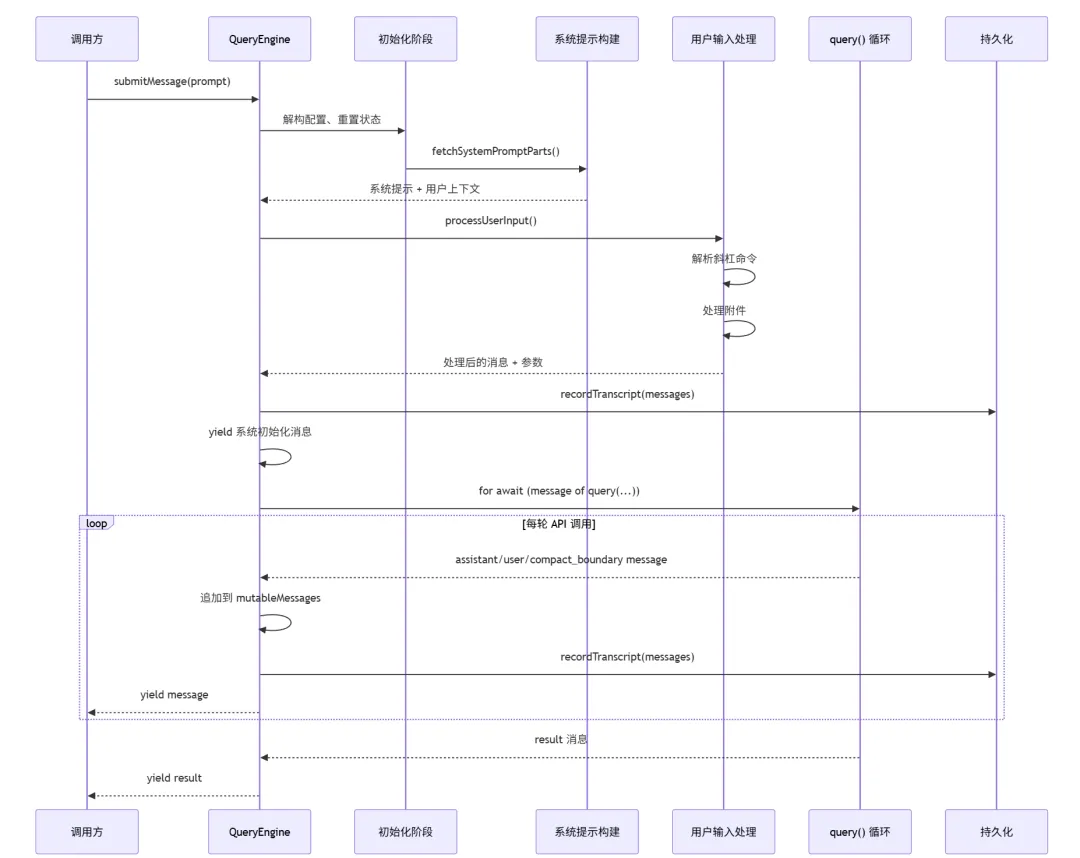
这张图展示了从用户输入到最终结果的完整路径。接下来我们会深入每个关键步骤。
2.2 第一阶段:初始化与配置解构
submitMessage的第一步是解构配置并重置状态:

关键操作解释:
`discoveredSkillNames.clear()`—— 清空技能发现记录。每轮对话都要重新开始追踪发现的技能,避免跨轮次累积。
`permissionDenials = []`—— 重置权限拒绝记录。这个数组用于向 SDK 报告用户拒绝了多少次工具调用。
`setCwd(cwd)`—— 设置当前工作目录。这是 Shell 工具执行时需要的上下文。
`persistSession`—— 检查是否需要持久化会话。如果用户禁用了会话持久化(CLAUDE_CODE_DISABLE_SESSION_PERSISTENCE),则不保存转录。
`startTime`—— 记录开始时间,用于最终计算总耗时。
2.3 第二阶段:包装 canUseTool
接下来,QueryEngine 包装了canUseTool函数:

为什么要包装?
原始的canUseTool只负责权限检查。QueryEngine 需要额外追踪权限拒绝记录,以便最终结果中报告给 SDK 调用方。
这是一种装饰器模式—— 在不修改原始函数的情况下,添加额外的行为。
2.4 第三阶段:构建系统提示
系统提示是 Claude 行为的"灵魂"。QueryEngine 通过fetchSystemPromptParts()构建系统提示:

系统提示的组成:
最终的系统提示由三部分拼接而成:

这种分层设计让系统提示可以灵活组合:
默认系统提示—— Claude Code 的核心行为定义
自定义系统提示—— 用户通过/custom-prompt命令覆盖
内存机制提示—— 告诉 Claude 如何使用记忆文件
追加系统提示—— 用户通过配置附加的提示词
2.5 第四阶段:处理用户输入

2.6 第五阶段:持久化转录

2.7 第六阶段:进入 query() 循环

发送 API 请求 流式接收响应 如果需要工具调用,执行工具并将结果作为用户消息发回 重复直到 API 返回纯文本响应
追加消息到mutableMessages
持久化转录
yield 消息给调用方
追踪轮次、Token 使用、权限拒绝等
2.8 消息类型处理
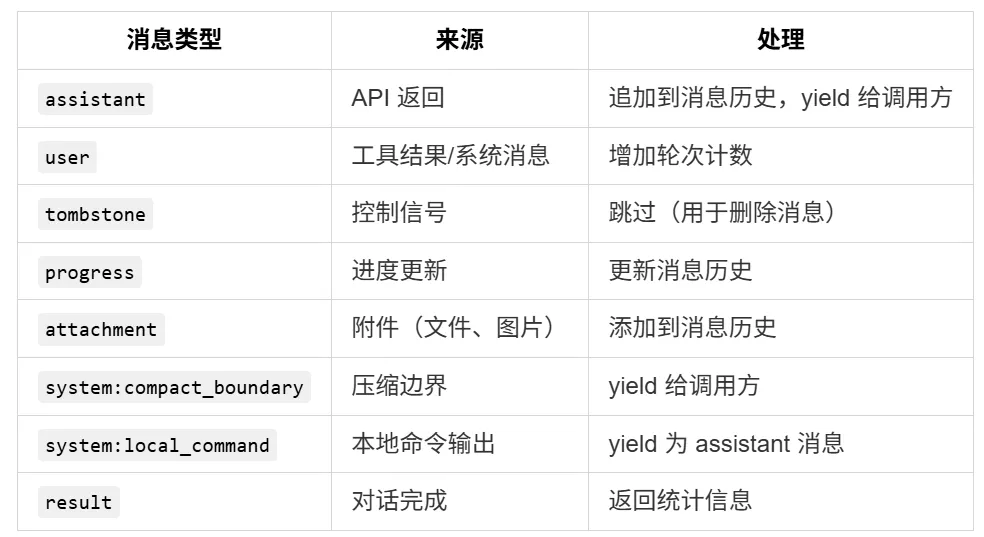
2.9 最终结果消息

第三部分:上下文压缩机制 —— 如何在有限窗口中保持记忆
你让 Claude 分析一个大型项目
它读取了 50 个文件,执行了 20 次命令,消息历史已经超过 150K tokens,但模型的上下文窗口只有 200K tokens。
3.1 压缩的挑战
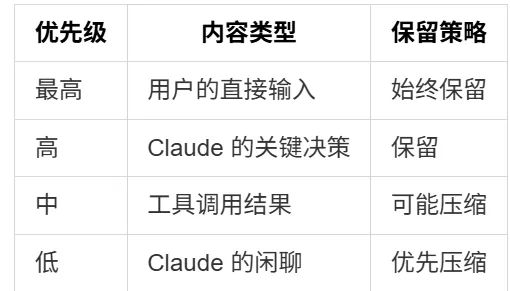
3.2 压缩策略的层次

3.3 自动压缩(Auto Compact)


自动压缩在以下情况触发: 当前消息 Token 数 > 有效上下文窗口 - 缓冲区 Token

因为一轮对话可能产生大量 Token Claude 的输出可能达到 8K-32K Token
工具调用结果(如文件读取)可能达到 20K+ Token
如果缓冲区太小,可能在检查时还有空间,但实际执行时就超限了。
3.4 压缩的核心流程

保存文件状态快照
记录压缩前的 Token 统计
通知外部系统(如遥测)
关键决策和结论 代码修改和文件操作 待完成的任务 对话历史:[... 消息列表 ...]
[System: 对话被压缩。摘要:...]← 压缩边界消息 [最近的消息保留]← 保留的原始消息
更新内部状态
标记压缩边界
清理临时消息
记录压缩统计
3.5 压缩缓冲区的演进
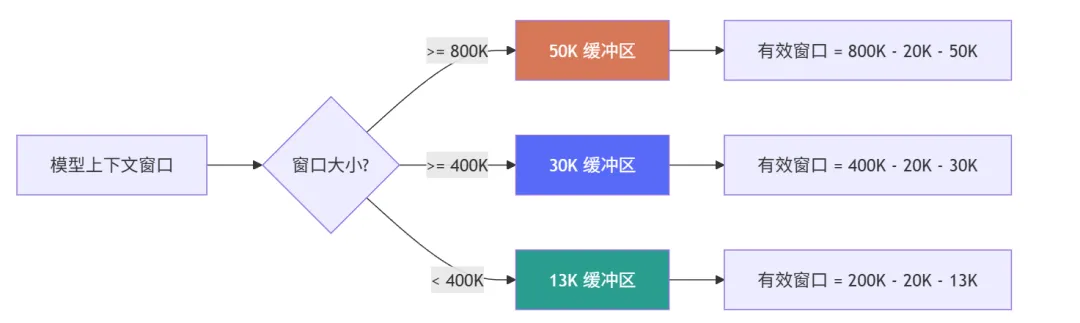
小模型(如 Haiku):输出 ~4K Token
中型模型(如 Sonnet):输出 ~8K Token
大模型(如 Opus):输出 ~32K Token
3.6 Snip 压缩:快速裁剪
3.7 微压缩(Micro Compact)

3.8 响应式压缩(Reactive Compact)

3.9 压缩失败处理
API 返回错误
超时
提示仍然太长(prompt_too_long)
2026-03-10 数据分析:1,279 个会话有 50+ 次连续失败(最多 3,272 次),每天浪费约 250K API 调用。
第一次失败:重试压缩 第二次失败:尝试不同的压缩策略(如从 Auto Compact 降级到 Snip Compact) 第三次失败: 停止压缩,继续对话(可能最终会因为上下文超限而报错)
3.10 压缩边界消息
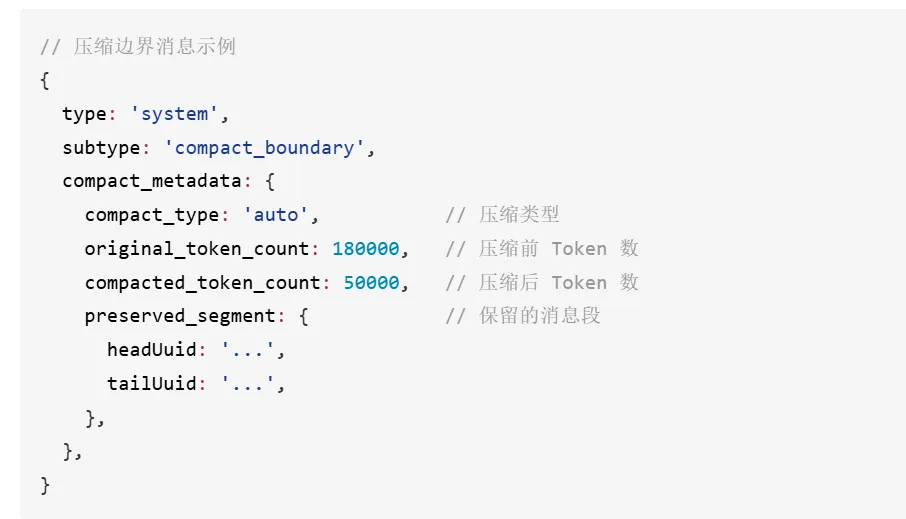
对话被压缩了
压缩的类型是什么
Token 数变化
哪些消息被保留了
第四部分:工具调用的编排 —— 从单个调用到循环执行
4.1 工具调用的生命周期
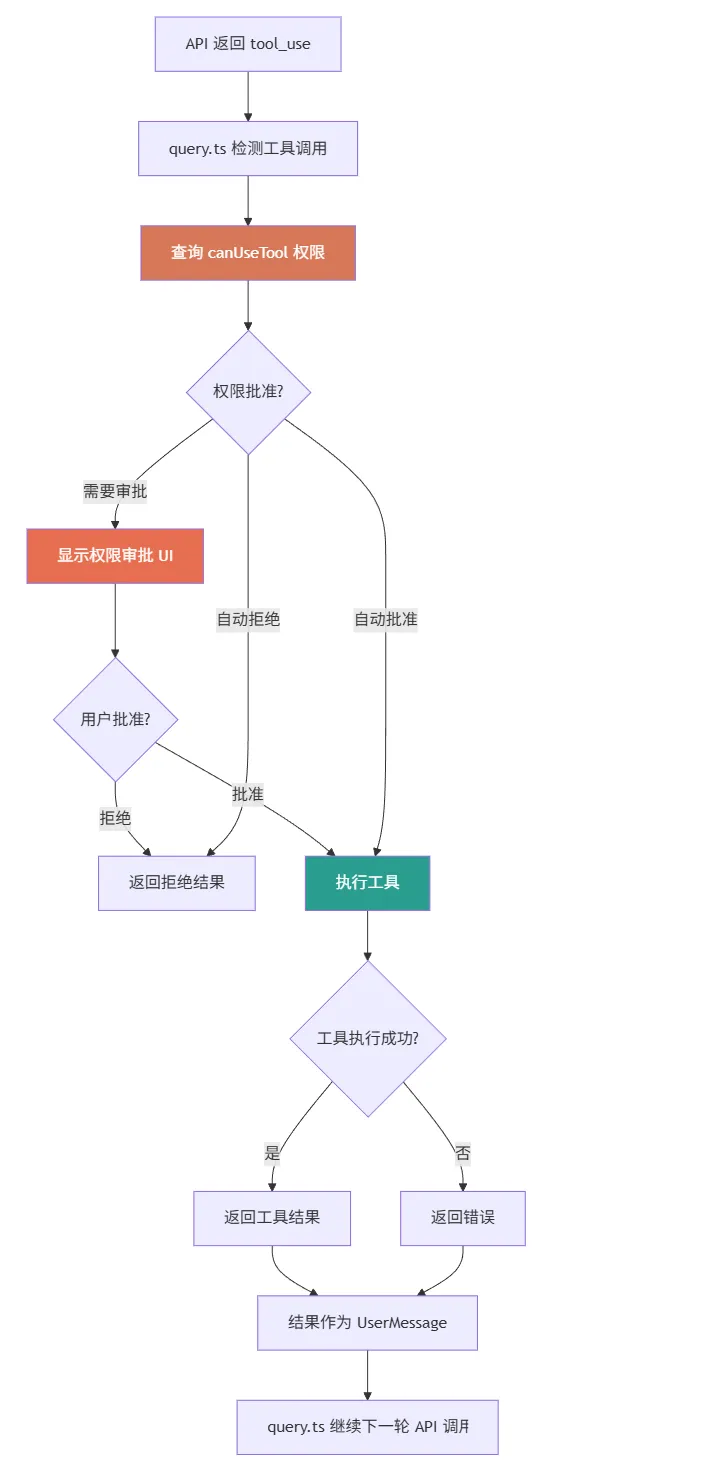
query.ts—— 检测工具调用,触发权限检查
canUseTool—— 检查权限
工具实现—— 执行实际操作
QueryEngine—— 追踪权限拒绝,记录统计
4.2 权限检查的层次
文件读取工具:通常自动批准
文件写入工具:需要批准
Shell 命令:需要批准
MCP 工具:取决于配置
4.3 QueryEngine 中的权限追踪

SDK 报告—— SDK 调用方需要知道有多少次工具调用被拒绝了 统计分析—— 了解哪些工具最常被拒绝,帮助改进用户体验

4.4 工具执行的细节


第五部分:Token 预算与成本控制
5.1 预算配置



5.2 Token 使用追踪



5.3 成本计算

5.4 预算检查

第六部分:文件历史与归因系统 —— 追踪每一次代码修改
6.1 文件状态缓存

·哪些文件被读取过
·读取时的内容
·读取的时间点
6.2 文件历史快照

消息的 UUID
消息发送时的文件状态
哪些文件在本次会话中被修改
6.3 Git 归因

哪些代码行是 Claude 修改的
修改的时间
相关的会话消息
6.4 会话恢复

总结与预告
本章回顾
AsyncGenerator 流式输出—— 让调用方可以在进行中就消费结果 装饰器模式—— 在不修改原始函数的情况下添加额外行为 多层压缩策略—— 根据不同场景选择不同压缩方式 断路器模式—— 防止无限重试导致的资源浪费 预测性预算检查—— 在操作前预测成本,而不是事后才发现超限
下一章预告
在理解了查询引擎之后,下一章我们将深入消息系统 —— 理解 Claude Code 如何定义和组织消息类型、如何在不同类型的消息之间转换、以及消息如何在 API 格式和内部格式之间适配。
如果你对"消息"这个看似简单实则复杂的系统感兴趣,下一章会给你带来全新的视角。
