 夜雨聆风
夜雨聆风你有没有遇到过这种事:问ChatGPT一个关键问题,它说得像模像样,你照做了,回头一查才发现有一段不对。你不是被它骗了,你是把信任交给了不稳定的回答。
OpenAI这次把ChatGPT的默认模型换新了,名字叫GPT-5.5Instant。官方说法很直接,未来两天会推给所有ChatGPT用户当默认模型,开发者那边也同步开放接口名“GPT-5.5-chat-latest”。
这类升级大家听多了,真正要盯的只有两件事:它会不会少说错话,它会不会少浪费你的时间。因为对普通人来说,模型再聪明,不能落在日常任务上,就是热闹。
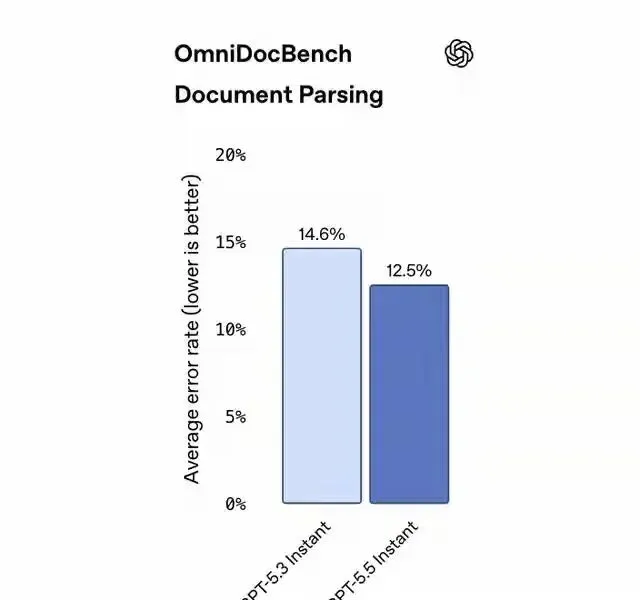
OpenAI给了两组数字,属于能拿来对账的那种。在医学、法律、金融这类高风险提示的内部评估里,GPT-5.5Instant产生的虚假陈述比GPT-5.3Instant少了52.5%。在用户标记为事实错误的高难度对话里,不准确陈述少了37.3%。
数字看着是模型内部评估,但对用户的意义很现实。你用AI写合同条款、看病历指标、算贷款方案,错一个点就可能带来损失。减少幻觉不是面子工程,它是把“敢不敢用”往前推了一步。
这次还有一个变化,挺贴近普通人。OpenAI说新模型回答会更清楚,语气更自然温暖,表达会收敛,减少冗长和过度格式化,也减少没必要的追问,还会避免一些让文本显得乱的元素。
我自己对“语气温暖”不敏感,我更在意的是,能不能把同一件事讲短一点,把关键步骤讲全一点。你不需要一篇作文,你要的是能立刻执行的答案。
官方也提到,它在日常任务上表现会更好,包含照片和图像上传后的分析、STEM相关问题,以及决定什么时候用网络搜索来给出有用的结果。这里的关键词不是“会搜索”,而是“知道什么时候该搜索”。
不少人遇到过这种尴尬:你问一个新政策,模型用旧知识回答得很笃定,结果全错。能判断何时上网,意味着它对“我有没有把握”这件事更诚实一点,这比花里胡哨的表达重要。
模型升级只是上半场,下半场是记忆和个性化。OpenAI这次把记忆与个性化功能做了全面改进,背后是一条明确路线:让ChatGPT从一次性问答,走向长期陪伴的个人助手。
它现在能够更有效地调用已保存的记忆、历史对话、你上传的文件,甚至是你连接的Gmail账户,来给出更贴近你情境的回答。你不用每次从零解释背景,它能接住上下文。
但个性化一旦走深,就绕不开一个问题:它拿了哪些信息,用了哪些信息,你能不能看见。很多人怕的不是它“记得”,而是它“悄悄用”。
这次推出的记忆来源功能,方向算对。它会把每次回答里调用了哪些上下文信息讲清楚,你可以按这个线索去更新、删除,或者断开数据连接。控制权不是写在条款里,是做成按钮放在你眼前。
记忆来源功能会向所有消费者订阅套餐的网页端用户开放,移动端也会跟进。个性化增强功能先给Plus和Pro用户的网页端,移动端同样会推。你会发现,普惠的是透明度,进阶的是体验强度。
如果你是普通用户,这些改动带来的改变不止是省事。你会开始把ChatGPT当成一个长期空间:它能记住你常用的写作口吻、你在做的项目、你对某类问题的偏好,你交给它的材料也能被持续复用。
但我想提醒一句,记忆带来的便利,往往伴随“默认同意”的惯性。你一旦连上Gmail,或者让它长期保留习惯信息,你就需要养成一个动作:定期检查记忆来源,断开不需要的连接。
这里有个分歧点也挺值得聊。支持派认为,透明的记忆来源已经把风险压到可控范围,用户自己做选择就行。谨慎派则觉得,任何跨应用连接都要慢一点,先看清权限再谈体验,不要被便利推着走。
对于开发者和企业用户,这次升级影响更直接。接口“gpt-5.5-chat-latest”启用后,很多集成了ChatGPT API的产品会自动拿到新模型输出,代码不用改,体验就会变。对企业来说,迭代成本会低不少。
这一点对行业也有外溢效应。你的客服机器人、内部知识库问答、财务助手、法务初审,只要接的是这个接口,整体回答质量会跟着走。模型进步会被快速扩散到各种应用里,用户会在不同场景感受到一致变化。
也正因为扩散速度快,OpenAI会更重视“稳定”和“可靠”。你要做商业服务,最怕的是输出忽上忽下。Instant这种定位,就是把日常使用的可预测性往上拉,减少你在结果上反复返工。
从竞争角度看,各家都在追两条线。一条是能力线,数学、推理、视觉、工具调用要扎实。另一条是关系线,谁能让用户长期留下来,谁就能形成高频数据与使用习惯,壁垒会慢慢出现。
OpenAI这次把两条线绑在一起:用准确性数据说服你相信它,用记忆与个性化让你留在生态里。它不需要你天天追新功能,它更希望你把工作流和资料都放进来。
这里面也藏着商业逻辑。你越常用,越愿意连接邮箱、上传文件、让它保存偏好,你离开成本就越高。对平台来说,这是粘性;对用户来说,这是方便;对隐私敏感的人来说,这是需要管理的资产。
如果你现在用ChatGPT做学习和办公,我建议你用一套简单规则去试它:找一个你常做的任务,让它在相同输入下给出可执行步骤,看看是否少废话;再找一个容易出错的领域问题,看看它是否会主动去搜索或提示不确定。
如果你在用它写简历、写邮件、做作业,别只看语言顺不顺。你要看它有没有把事实和逻辑说清楚,有没有把引用来源讲明白,有没有在不确定时停下来。这些细节才决定你用它是省时,还是埋雷。
我也想留一句话给所有把AI当伙伴的人:可信不是一句承诺,是每一次回答都经得起回查。模型少说错话,你的信任才有落点;记忆来源能看见,个人信息才算你说了算。
你站哪边?你愿意为了省时间把Gmail连上去,还是宁愿多打几行字也不授权?把你的选择写在评论区,我会挑典型场景做一次实测对照。觉得这种解读有用,点个关注,顺手收藏,转给那个总被AI坑到返工的人。
