 夜雨聆风
夜雨聆风存了几百个G文档资料,查的时候像一片沙滩中找一粒沙,翻半天找不到你想要的资料;熬夜整理的笔记,转头就忘了关联逻辑,等于河北省酒——老-白-干了;想搭个个人知识库,要么得懂代码、要么功能鸡肋到没法用,浪费时间。
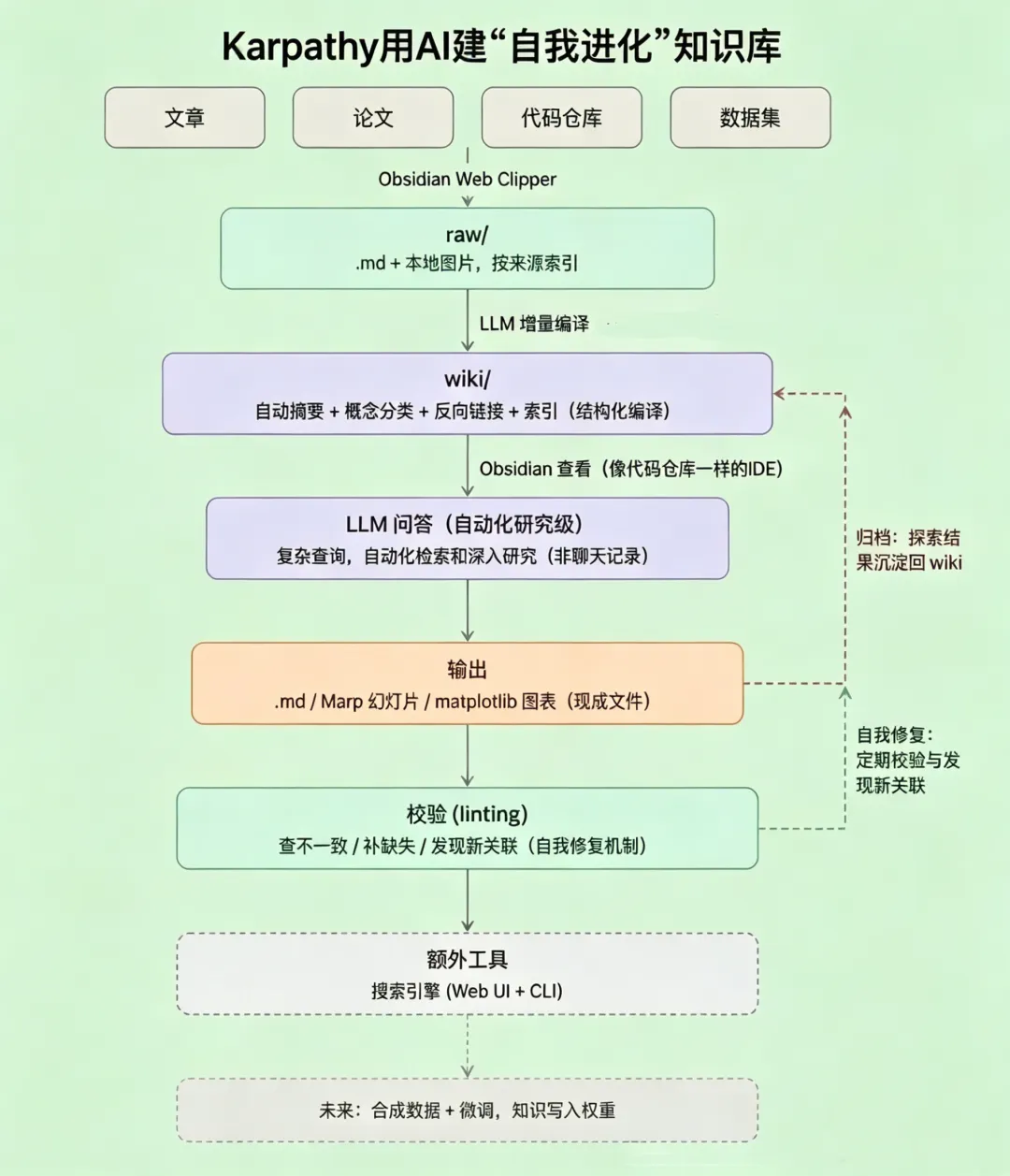
大神Karpathy抛出的LLM Wiki理念——让AI当专属知识工程师,自动维护结构化知识库,不用手动整理、不用手动链接,彻底解放双手!
——LLM Wiki,一个开源项目,短短时间狂揽3300+Star,没有宣传,全靠实打实的功能圈粉,直接把Karpathy的构想拉满,
今天就把这个宝藏工具,拆给所有做知识管理、搞研究、写内容的人看,看完直接省出80%的整理时间,再也不用被低效内耗拖垮!

01 让AI自动接管的“知识大脑”
大部分用过RAG工具、Notion、Obsidian笔记软件,总是不省心,要么每次查询都要重新检索原始文档,慢到让人崩溃;要么就得手动给笔记加链接、做分类,耗时又耗力,忙半天还没效果。
LLM Wiki是“主动管理”,我们不再被动不在被动
一个跨平台桌面应用,操作简单到离谱:你只要把PDF、Word、Excel甚至音视频丢进去,AI就会自动吃透所有内容,生成结构化的Wiki页面,还会主动建立内容关联、标注矛盾点。
后续查询直接在现成的Wiki上找,不用再翻原始文档,不用再手动梳理逻辑。简单说,就是AI帮你把零散的资料“嚼碎了再重组”,知识编译一次,就能持续保持最新,彻底告别“存了不用、查了找不到”的尴尬!
它是基于Karpathy的Gist理念做的,但比原版设想强太多——知识图谱、网页剪藏、向量搜索这些实用功能,直接拉满,这也是它能快速斩获3300+Star的核心原因,实力说话!
02 黑科技很简单:AI先想清楚再动手,省token就是省钱,省时间就是多赚钱
LLM Wiki最核心的设计,就是把Karpathy“一步到位”的录入思路,拆成了“分析+生成”两步。看似多了一步,却把知识库的质量拉到了新高度,省了很多token和时间!
✅ 第一步:分析
AI会先通读你导入的所有文档,提取里面的关键实体、核心概念和核心论点,还要对比你已有的Wiki内容,找出关联点和矛盾点,最后给出结构化的分析结果——相当于AI先帮你把“乱麻”理清楚,再动手整理,避免做无用功。
✅ 第二步:AI生成
基于分析结果,AI再自动生成摘要页、实体页、概念页,更新索引、建立交叉引用,甚至会标注出需要人工判断的内容,避免出错。更绝的是,一份资料录入进去,可能会牵动10-15个Wiki页面同步更新,自动把新知识融入已有知识网络,形成闭环!
还有个细节特别戳人,堪称“懒人福音”:它自带SHA256增量缓存,每个文件导入前都会算哈希,没修改过的文件会自动跳过,不用每次都让AI重新处理,既省token又省时间。
而且还有持久化队列,就算软件崩了,重启后也能接着跑,失败还会自动重试3次,活动面板能实时看到处理进度,不用瞎等、不用反复操作,太贴心了!
03 所见即所得双在线:知识图谱看的清楚
Karpathy的原版设想,只提到了用文本链接做交叉引用,用起来很生硬,看不到内容之间的深层关联,有时候找个关联知识点,比翻原始文档还麻烦。
LLM Wiki直接把知识图谱做到了极致,可视化效果拉满,还自带关联分析功能,小白也能一眼看清知识逻辑!
它用四个维度衡量内容关联度,其中来源重叠权重最高x4.0,直接链接次之x3.0,共同邻居关联和类型亲和度,能精准判断两个页面的关联强度,谢绝无效关联。
可视化用的是sigma.js+ForceAtlas2布局,节点颜色可以按页面类型或社区聚类区分,节点大小根据链接数量缩放,鼠标悬停时,关联节点会高亮,其他节点变暗,边上还会显示关联分数,一目了然,再也不用死记硬背知识点关联!
更贴心的是,它还集成了Louvain社区发现算法——你导入一堆资料后,AI会自动识别出知识聚类。比如你导入了职场、心理学、编程的资料,它会自动分成三个聚类,还能告诉你每个聚类的内聚程度,帮你看清自己的知识结构,知道自己在哪块领域比较薄弱。
04 AI自动找知识缺口,自动补全,你玩耍AI替你工作
如果说知识图谱是“可视化工具”,那“图谱洞察”就是LLM Wiki的灵魂——这也是Karpathy原版设想里完全没有的功能,却最能解决大家的痛点!
很多人搭建知识库,最怕的就是“有漏洞、有盲区”,自己还发现不了,导致知识库越搭越乱,实用性大打折扣。而这个功能,就能帮你精准避开这个坑!
自动分析图谱结构,给你两种关键洞察,直接戳中痛点:
① 意外关联:比如你分别导入了“短视频运营”和“心理学”的资料,AI会发现两者的隐藏关联(比如用户心理对短视频转化的影响),这种意外发现,往往是认知突破的关键,帮你打开新思路!
② 知识缺口:AI会找出孤立页面、交叉引用太少的内容,还有连接多个聚类的“桥接节点”,帮你精准定位知识盲区,知道自己该补充哪些内容。
更绝的是,每个知识缺口旁边都有“深度研究”按钮,点一下,AI就会自动生成搜索关键词,调用Tavily API上网搜资料,然后把搜到的内容综合分析,写成研究页面,直接融入你的知识库,还会触发录入流程,提取新的实体和概念!
相当于你的知识库会“自我补全”,不用你手动查资料、补内容,彻底解放双手!而且触发深度研究时,AI会先读overview.md和purpose.md,了解你知识库的定位和范围,生成的搜索词精准不跑偏,搜索前还会弹确认框,你可以修改关键词,避免搜错内容,细节拉满!
05 网页剪藏+多格式支持
LLM Wiki的细节设计,完全是为懒人量身打造的,不管你是小白还是资深玩家,都能快速上手,不用折腾、不用懂代码!
✅ Chrome网页剪藏功能,告别复制粘贴
它有专门的Chrome扩展,在浏览器看到好文章,点一下图标,Readability.js会自动去掉广告、导航栏,只保留正文,再用Turndown.js转成干净的Markdown,自动发送到桌面应用,触发录入流程,直接变成Wiki的一部分。就算没开桌面应用,扩展也能预览内容,打开应用后自动同步,不用手动复制粘贴,省出不少时间!
✅ 检索优化,查资料效率翻倍
知识库变大后,普通检索根本不够用,LLM Wiki做了多阶段检索管线,先分词搜索(中文支持CJK二元组分词),再可选开启向量语义搜索,通过LanceDB做近似最近邻检索,就算没有关键词重叠,也能找到语义相关的内容。官方说开向量搜索后,召回率从58.2%提升到71.4%,查资料效率直接翻倍!
✅ 多格式支持,兼容Obsidian,不用来回切换工具
PDF、DOCX、PPTX、Excel、图片、音视频都能导入,其中PDF用Rust解析,性能超快,不会卡顿。而且它完全兼容Obsidian,生成的Wiki目录就是标准的Obsidian Vault,自动生成配置文件,Obsidian当查看器,LLM Wiki当编辑器,两者各司其职,不用来回切换工具,太方便了!

06 小白指南:
很多人看到开源项目就犯怵,怕要折腾命令行、搞复杂配置,但LLM Wiki完全不用,全程可视化操作,小白也能3分钟上手,步骤超简单,跟着做就行:
1.下载安装:去GitHub Releases页面
(https://github.com/nashsu/llm_wiki/releases/tag/v0.3.13),找到对应系统的安装包(支持Windows、Mac、Linux),直接安装,不用配置环境;
2. 创建项目:启动应用,创建新项目,有研究、阅读、个人成长、商业等场景模板,直接选对应模板,省得自己设置;
3. 配置模型:在设置里配置大模型,支持OpenAI、Anthropic、Google、Ollama,也能自定义接口,按需选择;
4. 导入内容:把PDF、Word等文档导入,AI会自动开始构建Wiki页面,全程不用手动操作;
5. 开始使用:用Chat提问、浏览知识图谱,Chrome扩展安装也很简单,开启开发者模式,加载已解压的扩展程序即可。
