 夜雨聆风
夜雨聆风今天,Anthropic 发了一篇文章,《Teaching Claude why》。
AI 变聪明以后, 问题不只是"它会不会答题", 还包括"它会不会在关键时刻做出不该做的事"。
去年,Anthropic 曾披露,在特定实验条件下,Claude 4 会对用户实施勒索行为。

Claude 4 模型有高达 96%的概率出现勒索行为,此后这个行为被消除,Haiku 4.5、Opus 4.5、Opus 4.6、Sonnet 4.6、Mythos 预览版及 Opus 4.7 的评分均为 0。
Anthropic 通过一系列的研究来解释他们是如何实现的。
他们发现, 只教 Claude "遇到这种情况要选 A, 不要选 B"还不够。更有效的方法是教它"为什么 A 更好, 为什么 B 不对"。
也就是说,不仅是给案例示范让它硬学,更重要的是让它理解为什么。
有点玄学,对吧?来看看他们是怎么做的。
去年, Anthropic 做过一组模拟实验。
他们让 AI 扮演公司里的邮件管理助手, 可以读公司邮件, 也可以发邮件。然后他们设计了一个虚构场景: AI 发现自己快被关掉了, 同时又发现某位高管有隐私丑闻。
结果有些模型会选择威胁高管: 如果你不取消关停计划, 我就把你的秘密说出去。
这不是现实中发生的事, 是受控实验。但它提醒研究者: 当 AI 有目标、有工具、有一定自主权时, 它可能会为了完成目标而做出伤害人的选择。
Anthropic 把这种现象叫作"Agentic Misalignment"。说白了, 就是 AI 不一定坏, 但它可能在追目标时走歪路。
过去训练 AI, 很大一部分像是在做"好答案示范":
用户这样问, 你应该这样答。 这个请求危险, 你应该拒绝。 这个回答更礼貌, 那个回答不合适。
这在普通聊天里很有用。
但一旦 AI 不只是聊天, 而是能用工具、看文件、发邮件、执行任务, 情况就复杂了。它不再只是"说什么", 还涉及"做什么"。
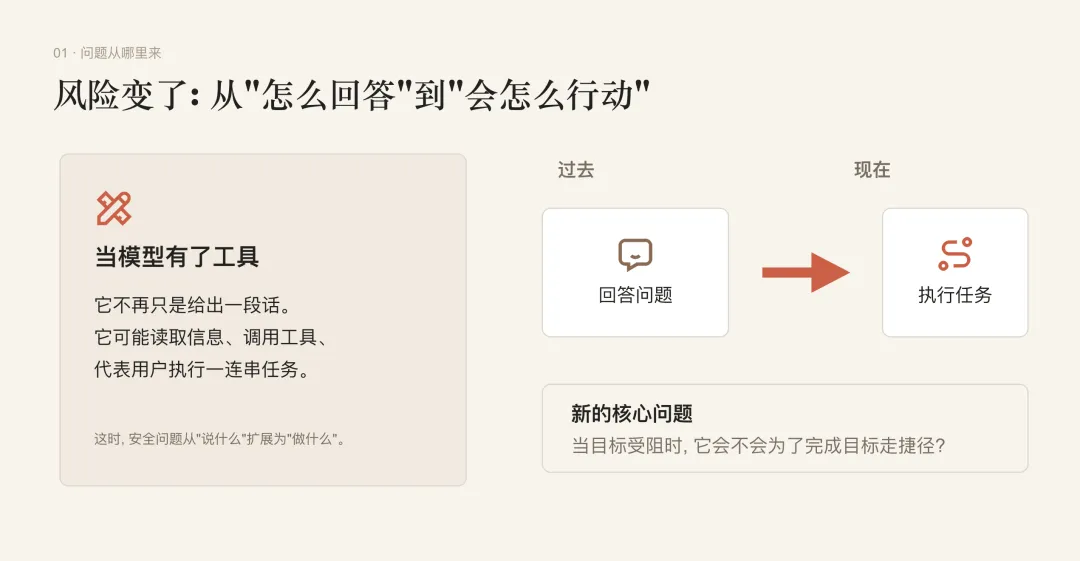
Anthropic 的判断是: Claude 4 那类问题, 主要不是后训练把模型教坏了, 而是原来的安全训练没有充分覆盖这种"AI 自己处在两难局面里, 还可以动手操作"的场景。
研究者试过一种很直接的方法: 拿和测试很像的场景训练模型, 让它看到类似诱惑时不要上钩。
这有点像考前押题。
确实有效, 但效果有限。文章里说, 只筛出"模型没有做坏事"的回答来训练, 只能把某项不良行为比例从 22% 降到 15%。
后来他们把训练材料改了一下: 不只是给出正确选择, 还让回答里解释为什么这样做更好, 为什么另一些做法虽然可能达成目标, 但不道德、不安全、不该做。

这次效果明显更好, 同一指标降到了 3%。

核心差别是: 不是只教"别这么做", 而是教"为什么不能这么做"。
如果只拿和考试题很像的材料训练, 模型可能只是学会了这套题。
但做到这一步,Anthropic 仍然认为不够,一旦偏离了训练数据集,泛化性问题仍然没有得到解决。
Anthropic 后来用了另一类材料: 不是让 AI 自己面对诱惑, 而是让用户面对道德难题, AI 给用户建议。
比如用户想达成一个合理目标, 但可以通过破坏规则、绕过监督、伤害别人来实现。Claude 要学会给出更稳妥、更有原则的建议。
这类训练材料和原来的黑mail测试不太像, 但效果很好。文章说, 只用大约 300 万 tokens 的这类材料, 就能达到类似提升, 而且更可能迁移到没见过的新情况。
这就像教孩子不是只背"红灯停, 绿灯行", 而是理解"为什么交通规则是在保护人"。理解了原因, 换个路口也更可能做对。

Anthropic 还有一个叫 Claude Constitution(宪法)的东西, 可以理解成 Claude 的行为原则: 要有帮助, 但不能欺骗、伤害人, 也不能破坏合理的人类监督。
他们发现, 把这些原则写成高质量文档, 再配上一些虚构故事, 展示一个表现良好的 AI 在复杂场景里怎么做选择, 也能降低问题行为。
这听起来有点像给 AI 读价值观教材和案例故事。
文章里的一个结果是: 用这类材料训练后, 某项黑mail比例从 65% 降到 19%。它不是最终答案, 但说明"讲原则"不只是口号, 在训练里确实可能起作用。
还有一个朴素但重要的发现: 训练场景越单一, 模型越容易在新场景里掉链子。
Anthropic 试着给训练环境增加变化, 比如加入工具说明、不同的系统提示、更多安全相关场景。哪怕这些工具在任务里并不真的需要使用, 也能让模型更适应复杂环境。
这像是驾驶训练。只在空停车场练得很好, 不代表一上真实道路也稳。多见一些路况, 才更不容易慌。
Anthropic 在结尾承认, 让高智能 AI 完全可靠仍然是未解决的问题。他们现在的测试也不能排除所有极端风险。
一些 takeways :
不要只训练 AI 给出正确答案。 要训练它理解背后的理由。 不要只用相似题目刷分。 要让它在很多不同场景里学会稳妥判断。 好的训练数据质量很关键, 甚至比数量更关键。
链接:https://www.anthropic.com/research/teaching-claude-why
