 夜雨聆风
夜雨聆风当你在ChatGPT里输入"hello",按下回车的那一刻,背后是一整排GPU集群在为你运转。
你有没有想过一个问题:各大AI公司收着token费,它们到底赚不赚钱?
答案可能让你意外:几乎都在亏,而且亏得越来越多。
一、收入在涨,亏损也在涨
先看几组数据:
OpenAI,2026年年化收入约200亿美元,但预计全年亏损140亿美元。更夸张的是它的现金燃烧预测——2026年预计烧170-250亿,2027年烧570亿,2028年峰值850亿。到2030年,累计烧钱预计达到6650亿美元。OpenAI自己预计2030年才可能盈利。
Anthropic,情况稍好。年化收入已突破300亿美元(2026年4月),增速比OpenAI还猛。但2026年同样是它亏损最大的一年,管理层公开沟通的目标是2028年实现盈亏平衡——比OpenAI早两年。
Google稍微不一样。Google Cloud一季度收入突破200亿美元,同比增长63%,其中AI是主要增长动力。母公司Alphabet整体净利润626亿美元。但Google的AI收入混在Cloud业务里,单独核算AI基础设施的投入和回报,依然是亏的。
核心矛盾就在这里:收入在涨,但成本涨得更快。
二、说一声"hello",到底要花多少钱?
训练一个前沿大模型,成本动辄数亿到数十亿美元。OpenAI最新的模型训练费用据传超过100亿美元。这还只是"造出来"的钱。
训练是一次性的,推理才是每天都在烧的钱。
每次你跟AI对话,背后是一整排GPU在跑。虽然单次推理的成本在下降(Google说Gemini的单位成本2025年降低了78%),但用量的增长速度远远超过了单价的下降速度。
2026年,AI推理成本已经占企业AI预算的85%。企业从试验性聊天机器人转向生产级的AI代理部署,而AI代理消耗的token量是普通对话的数倍。
数据中心、芯片、电力——全是重资产。OpenAI承诺未来几年投入超过1万亿美元建设基础设施。Google 2026年的资本支出预计翻倍。各家还在疯狂降价抢市场,预算级模型现在已经降到每百万token不到1美分。单价被不断压缩,但固定成本一点没少。
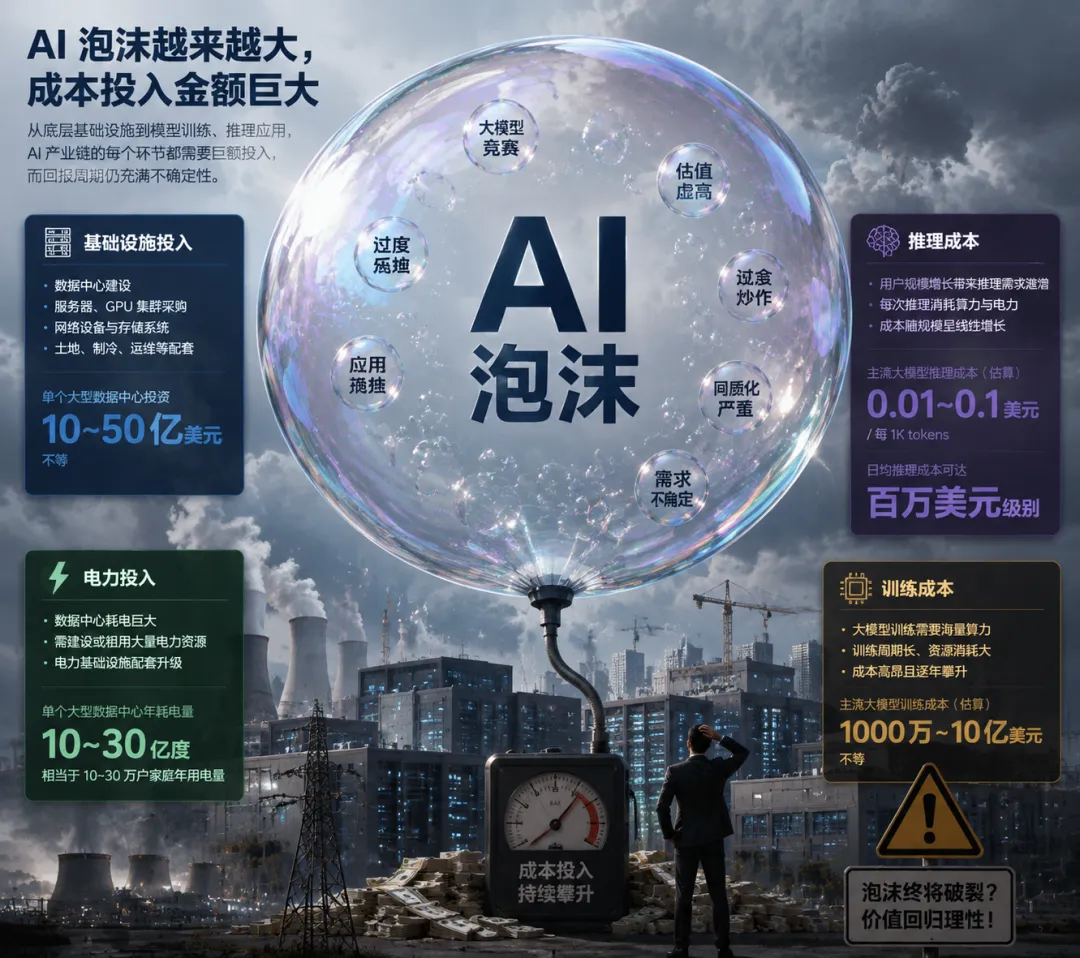
三、连OpenAI自己都慌了:9亿用户,只有5%掏钱
最讽刺的是,连OpenAI自己都意识到"用户多不等于赚钱"了。
ChatGPT现在有9亿周活用户,听起来很猛对吧?但只有约5%是付费用户——也就是说,9亿用户里,真正掏钱的不到5000万。剩下的8.5亿,免费用。
这就像一个游乐园,每天挤满了人,但只有5%的人买票。
今年4月,华尔街日报爆出OpenAI没达到自己的内部目标——包括2025年底达到10亿周活用户的目标、ChatGPT去年营收目标、以及今年多个月度营收目标。Anthropic在企业端杀得太猛,OpenAI被追得有点喘不过气。
所以OpenAI改策略了。
CEO办公室主任Simo在内部会议上说得很直接:"我们不能因为分心而错过这个时刻,我们必须做好生产力这件事,尤其是企业端的生产力。"
OpenAI现在企业收入占总收入的40%,预计2026年底就能和消费者端持平。Codex(AI编程工具)周活用户突破300万,API每分钟处理超过150亿token。高盛、State Farm、Phillips这些大企业都在用OpenAI的"agent团队"来跑业务流程。
从"做用户"到"做收入",从"消费者"到"企业"——这个转变本身就说明了一个问题:靠用户增长掩盖单位经济问题的时代,快结束了。
Anthropic早就看清了这一点。它几乎没有消费者产品,30万企业客户贡献了80%的收入,所以它的盈利路径比OpenAI短了整整两年。
四、泡沫的真正问题:不是AI没用,是太贵了
很多人以为AI泡沫是因为"AI没用"。错了。
泡沫的本质是:估值太贵,加上成本太高。
想象一下:你在ChatGPT里输入"hello",模型思考了几秒给你回复。这看似简单的交互,背后消耗的计算资源,可能够你家用电好几天。
如果AI永远只能跑在云端的大集群上,那它本质上就是一个昂贵的集中式服务,而不是真正的技术革命。
这就是泡沫的根源:如果AI不能普及到足够多的使用者手里——不能跑在个人电脑上,不能让中小公司用得起——那它的收入天花板就有限,烧钱速度永远追不上。
Anthropic能在2028年盈利,不代表泡沫不存在。 它只是证明了:走企业路线、单位经济更好的公司,能活下来。但想想互联网泡沫——Amazon活下来了,但.com时代大部分公司死了。泡沫是真实的,只是存活下来的那批公司证明了技术本身有价值。
OpenAI承诺10年投入1.4万亿美元,Google资本支出翻倍,Meta、Microsoft、Amazon都在疯狂建数据中心。这些投入是基于"AI需求会无限增长"的假设。如果需求增速不及预期,这些沉没成本就是泡沫破裂的直接证据。

五、破局之路:推理成本能不能降到临界点?
关键问题只有一个:推理成本能不能降到让中小企业和个人开发者也用得起?
有两条路:
路径一:大模型推理成本持续下降
• ASIC专用芯片:Google的TPU Ironwood推理性能已经超过NVIDIA最新GPU。Microsoft、Amazon、Meta都在做自己的AI芯片。ASIC是专门为AI推理设计的,同样的功耗,推理效率可以是GPU的10-30倍 • 架构优化:MoE(混合专家)架构让推理时只激活部分参数;量化、蒸馏、剪枝让模型越做越"瘦" • 规模化效应:用量越大,边际成本越低
路径二:端侧AI普及
很多人说,用小型模型不就行了?7B、13B参数,在消费级GPU甚至手机上都能跑。
"能用"和"好用"是两回事。
拿编程来说——开发一个中等规模的项目,小模型大概率搞不定:
• 生成的代码有bug • 不是你要的逻辑 • 丢失了边界条件、异常处理、并发安全的考虑 • 理解不了整个项目的架构和依赖关系
你花3分钟改bug的时间,可能比从头写还长。
对于严肃的软件开发、金融分析、医疗诊断这些场景,小模型目前确实不够用。 但简单任务——摘要、翻译、分类——小模型已经够用了。
简单任务本地跑,复杂任务云端处理——这可能是最现实的方案。 Apple已经在iPhone上做on-device AI,Qualcomm、Intel都在推NPU,端侧推理是明确趋势。
六、我的判断
泡沫确实存在,但破的方式可能不是"AI没用",而是"分化"。
• 头部公司活下来,但估值回归理性 • 中间一批公司死掉 • 然后出现一批真正能赚钱的AI应用公司
真正的分水岭在未来2-3年:
推理成本能不能降到让中小企业和个人开发者也用得起?如果降到这个程度,泡沫会消化掉;如果降不下来,那确实会破裂。
说到底,AI不是魔法,它是一门生意。
这门生意能不能成立,不取决于模型有多聪明,而取决于说一声"hello"的成本,能不能降到人人都用得起。
你觉得AI会破泡沫吗?还是推理成本真的能降到临界点?欢迎在评论区聊聊你的看法。
