深度拆解 Claude Code 源码系列(四):流式处理 —— 实时数据流的精密编排编者:这是系列文章的第四章。在前三章中,我们了解了 Claude Code 的整体架构、查询引擎和消息系统。本章将深入流式处理系统 —— 理解 Claude Code 如何处理 SSE 事件流、实现流式工具调用、以及流式响应的错误处理和重试机制。
引子:为什么需要流式处理?
你让 Claude Code 分析一个大型项目。它需要读取几十个文件、执行多个命令、然后给出分析报告。整个过程可能需要 30 秒甚至更久。屏幕上什么都没有,你不知道 Claude 是在思考、还是在读取文件、还是已经卡死了。你只能盯着光标闪烁,心里想着:"它还在运行吗?"Claude 的输出逐字出现在屏幕上,就像有一个人在实时打字。你能看到它的思考过程,看到它在读取哪些文件,看到它在执行什么命令。即使整个过程需要 30 秒,你也不会觉得漫长 —— 因为你一直在接收信息。这就是流式处理的价值:让等待变得可感知、可理解、可交互。- SSE(Server-Sent Events)协议 —— 如何从 API 接收流式事件
- 性能优化 —— 如何避免频繁的 UI 更新导致卡顿
在这一章中,我们将深入 Claude Code 的流式处理系统,理解它是如何实现这些复杂功能的。
第一部分:SSE 事件流基础 —— 从协议到事件类型
1.1 什么是 SSE?
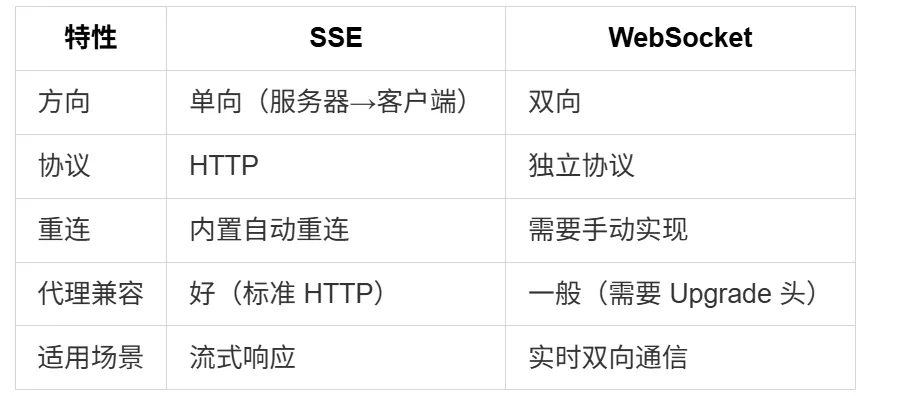
SSE(Server-Sent Events)是一种基于 HTTP 的服务器推送技术。与 WebSocket 不同,SSE 是单向的 —— 只有服务器向客户端推送数据。3. 服务器逐步发送数据,每行以 data: 开头为什么 Claude Code 选择 SSE 而不是 WebSocket?对于 AI 对话场景,SSE 是更合适的选择 —— 客户端发送请求,服务器流式返回响应,不需要客户端向服务器推送数据。1.2 Claude Code 的流式架构
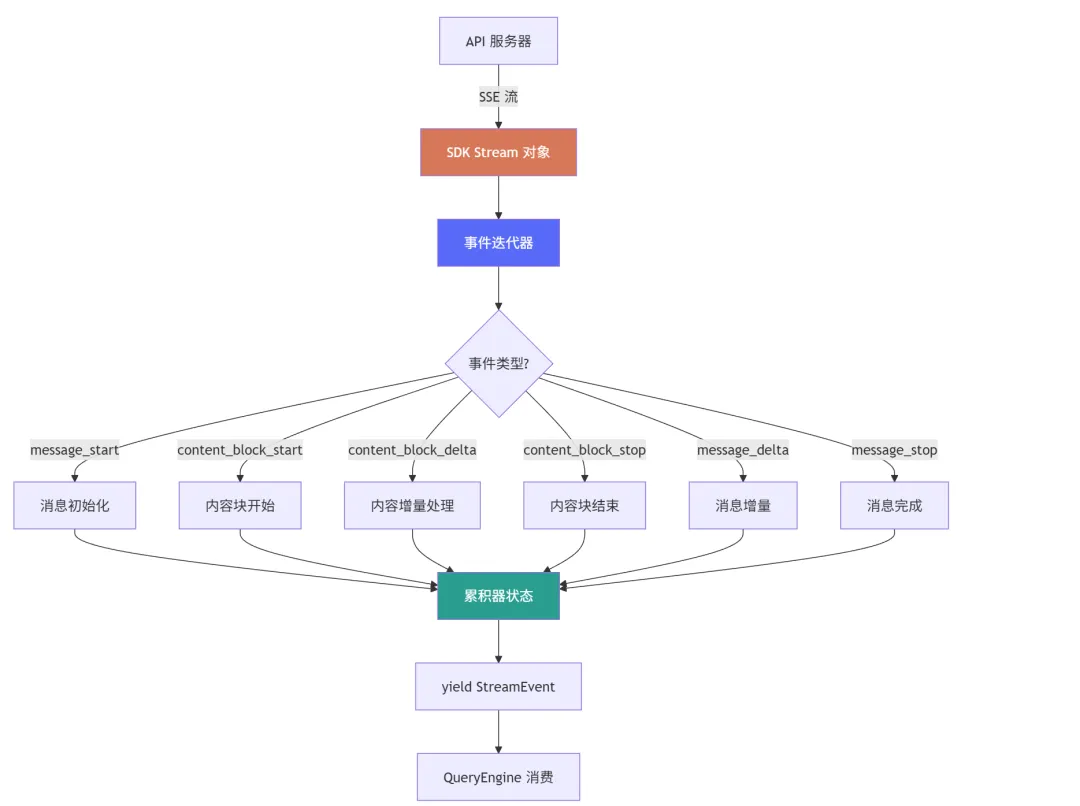
让我们看看 Claude Code 的流式处理整体架构:1. SDK Stream 对象 —— Anthropic SDK 提供的流式接口2. 事件迭代器 —— 遍历 Stream 对象,逐个获取事件4. StreamEvent —— 标准化的事件对象,yield 给调用方1.3 流式 vs 非流式
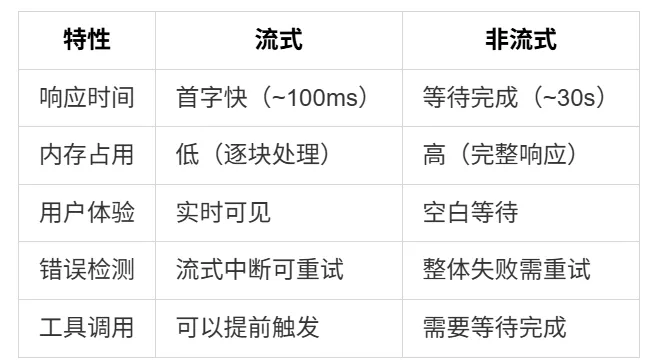
Claude Code 的 API 调用默认使用流式模式,但也支持非流式调用。答案很明显:用户体验。流式响应让用户能够在 Claude 还在"思考"时就看到部分输出,这极大地降低了感知延迟。1.4 StreamEvent 类型定义
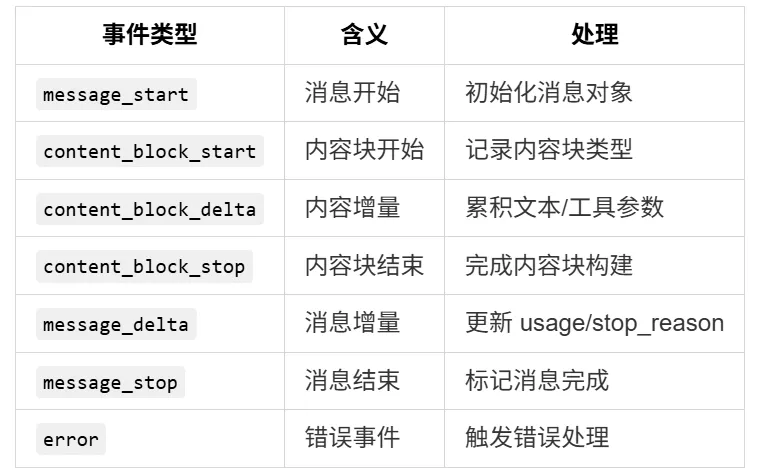
在 Claude Code 中,SSE 事件被标准化为 StreamEvent 类型:
第二部分:流式事件处理 —— 事件解析与状态累积
SSE 事件流只是数据的传输方式。要将这些事件转换为有意义的消息对象,需要一个精密的事件处理系统。2.1 事件迭代器
Claude Code 通过迭代 SDK Stream 对象来获取事件:1. for await...of —— 使用异步迭代器,等待每个事件到达2. processStreamEvent —— 根据事件类型调用不同的处理逻辑3. yield* —— 将处理结果 yield 给调用方(QueryEngine)2.2 累积器状态
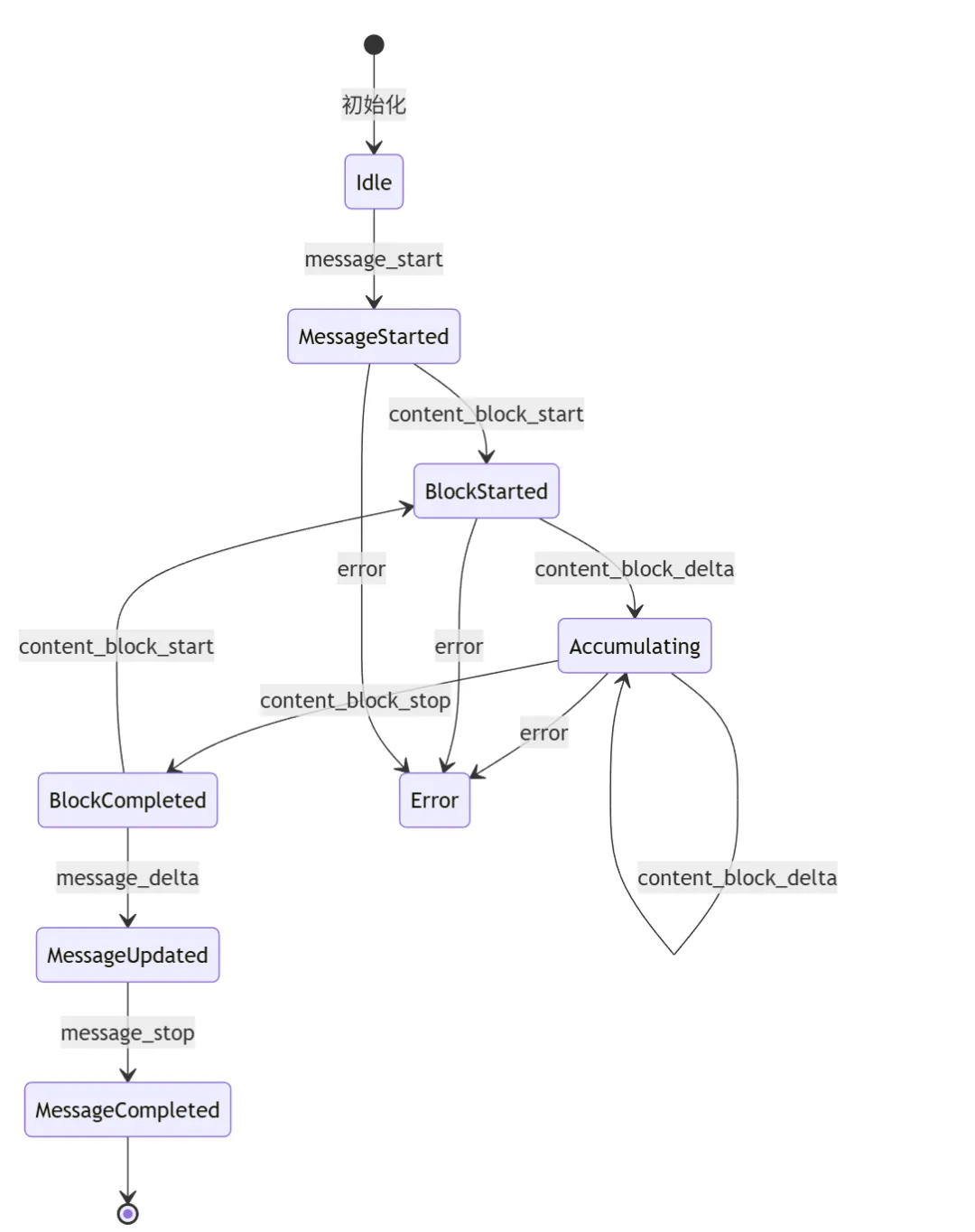
流式事件处理的核心是一个累积器(accumulator),用于追踪消息的构建状态:每个 SSE 事件只包含增量信息。例如,content_block_delta 事件只包含新增的文本片段,而不是完整的文本。累积器负责将这些增量信息拼接成完整的内容。2.3 事件处理状态机
1. Idle → MessageStarted —— 收到 message_start,初始化消息骨架2. MessageStarted → BlockStarted —— 收到 content_block_start,开始新内容块3. BlockStarted → Accumulating —— 收到 content_block_delta,开始累积内容4. Accumulating → Accumulating —— 继续收到 delta,持续累积5. Accumulating → BlockCompleted —— 收到 content_block_stop,完成内容块6. BlockCompleted → BlockStarted —— 收到下一个 content_block_start,开始新内容块7. BlockCompleted → MessageUpdated —— 收到 message_delta,更新消息统计8. MessageUpdated → MessageCompleted —— 收到 message_stop,消息完成2.4 文本累积
accumulator.currentText += event.delta.text —— 累加每个增量
yield { type: 'partial_text', ... } —— 立即 yield 给调用方,实现流式显示
2.5 工具参数累积
工具调用比文本复杂得多。工具参数通常以 JSON 格式流式到达:因为 JSON 片段在累积完成之前可能不是有效的 JSON。如果提前解析并 yield,会导致解析错误。2.6 内容块完成
当收到 content_block_stop 事件时,内容块构建完成: 1. 根据类型构建内容块 —— 文本、工具、思考过程有不同的格式2. JSON 解析 —— 工具参数的 JSON 字符串解析为对象4. yield 完整内容块 —— 通知调用方内容块已完成
1. 根据类型构建内容块 —— 文本、工具、思考过程有不同的格式2. JSON 解析 —— 工具参数的 JSON 字符串解析为对象4. yield 完整内容块 —— 通知调用方内容块已完成2.7 消息完成
当收到 message_stop 事件时,消息构建完成:2.8 流式事件的消费方
流式事件被 yield 给 QueryEngine,QueryEngine 根据事件类型执行不同的操作:2. 内容块完成 —— 如果是工具调用,触发工具执行第三部分:流式工具调用 —— 从参数累积到执行触发
在 Claude Code 的核心循环中,工具调用是最复杂的流式场景。3.1 工具调用的流式特征
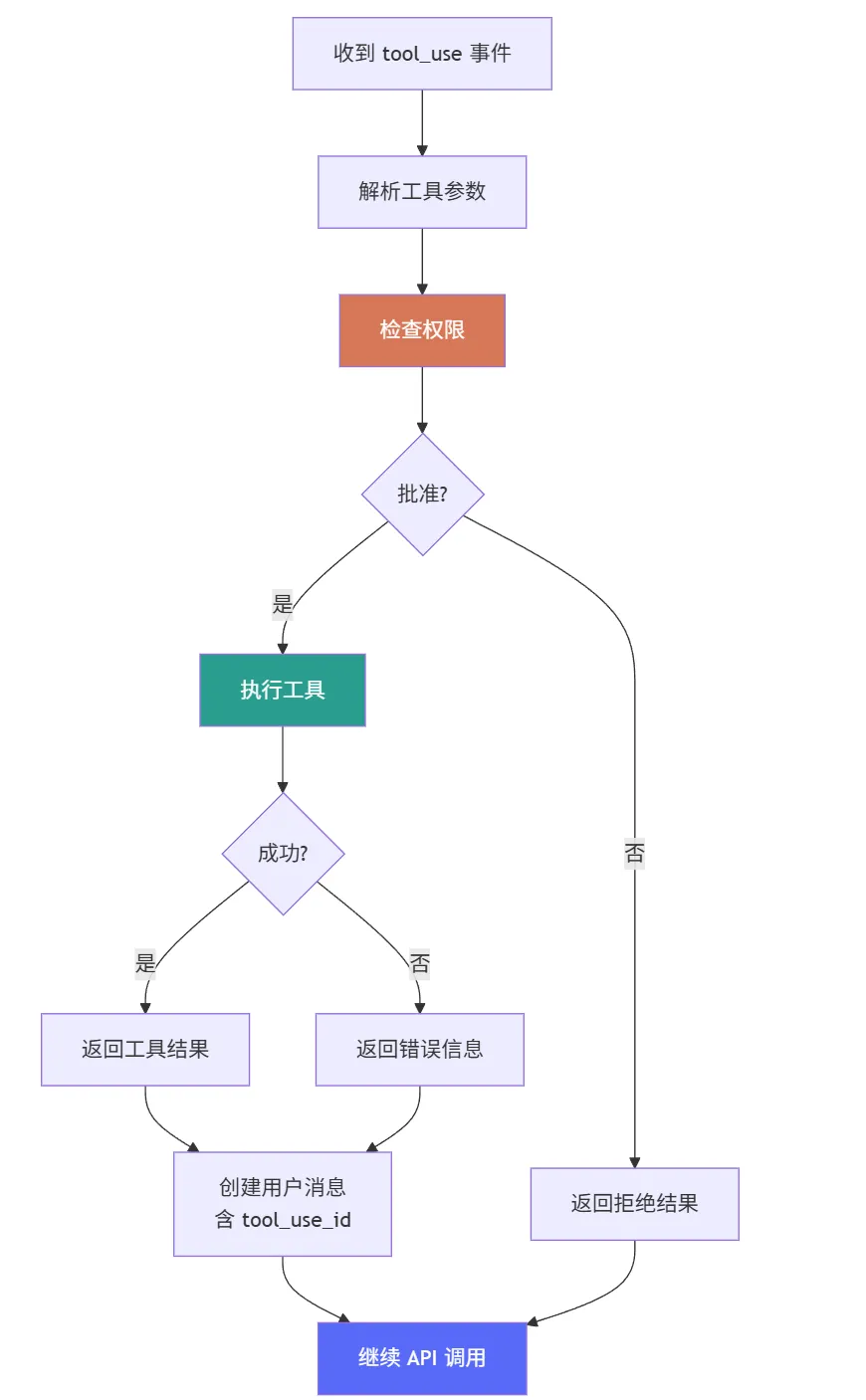
当 Claude 决定调用工具时,它会输出一个 tool_use 内容块。这个内容块的参数是流式到达的:1. 参数不完整 —— 在 content_block_stop 之前,JSON 可能无效2. 需要立即执行 —— 一旦参数完整,需要立即触发工具执行3. 执行结果需要发回 —— 工具结果作为用户消息发回 API3.2 工具调用的触发时机
工具调用在 content_block_stop 事件后触发:因为在 content_block_stop 之前,JSON 参数可能不完整。例如:{"path": "src/utils/← 缺少闭合引号和括号如果在这个状态下尝试 JSON.parse(),会抛出语法错误。3.3 工具执行循环
1. 解析参数 —— 从累积的 JSON 字符串解析为对象4. 构建结果消息 —— 将工具结果包装为用户消息5. 继续 API 调用 —— 将结果发回 API,等待下一个响应3.4 工具结果的格式
tool_use_id —— 关联到原始工具调用的 ID
content —— 工具执行结果(文本、错误信息等)
parent_tool_use_id —— 追踪工具调用的父级关系
3.5 并行工具调用
Claude 可以在一次响应中调用多个工具。这些工具可以并行执行:
第四部分:错误处理与重试 —— 流式中断的恢复机制
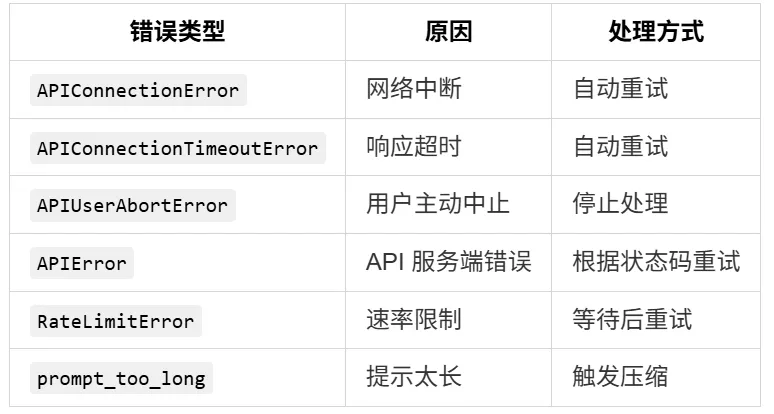
4.1 流式错误类型
4.2 流式错误检测
4.3 重试策略
不是所有错误都可以重试。Claude Code 的重试策略:4.4 流式中断后的恢复
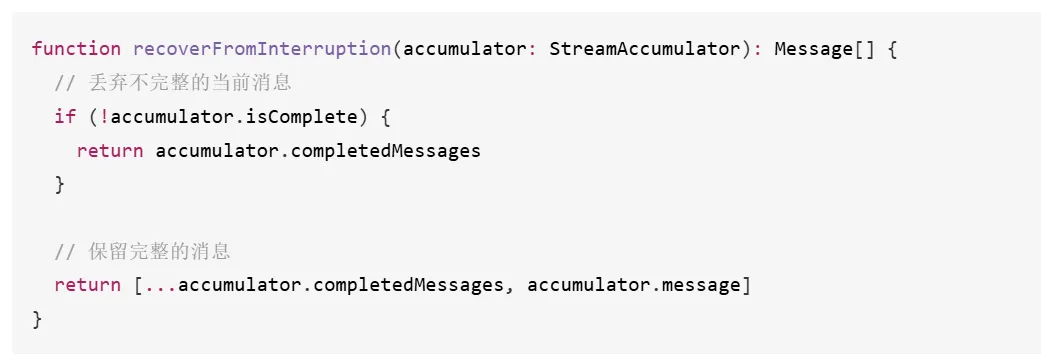
流式响应中断后,恢复是一个挑战。因为响应是逐步到达的,中断时可能只有部分数据。1. 丢弃不完整的消息 —— 中断的消息可能不完整,不能保留3. 重新发送请求 —— 使用相同的参数重新发起 API 请求4.5 降级策略
错误消息被 yield 给 QueryEngine,由 QueryEngine 决定如何处理:·可重试 —— 显示"正在重试...",然后重试
·不可重试 —— 显示错误信息,让用户决定
第五部分:流式渲染管线 —— 从事件到 UI 的实时渲染
流式处理的最终目标是让用户实时看到响应。这需要一个高效的渲染管线。5.1 流式渲染的架构
5.2 文本缓冲区和节流
流式文本到达速度很快(可能每 10ms 一个事件)。如果每个事件都触发 UI 渲染,会导致性能问题。5.3 工具调用状态渲染
🔧 正在调用:FILE_READ(src/utils/messages.ts)5.4 思考过程渲染
当启用思考模式时,Claude 会输出 thinking 内容块:思考过程通常以灰色、缩进的样式显示,与正常响应区分开来。
第六部分:流式性能优化 —— 缓存、批量处理与内存管理
6.1 Prompt 缓存
Anthropic API 支持 prompt 缓存,可以缓存系统提示和消息历史。- 减少延迟 —— 缓存命中时,首字延迟降低 50-80%
降低成本 —— 缓存读取比重新处理便宜 50%
缓存失效 —— 消息历史变化时缓存失效
缓存大小限制 —— 缓存有大小限制
6.2 流式批处理
6.3 内存管理
问题:流式事件在累积器中累积,如果响应很大(如 100K tokens),可能占用大量内存。1. 及时 yield —— 事件处理后立即 yield,不保留在内存3. 压缩消息历史 —— 定期压缩消息历史,减少内存占用
总结与预告
本章回顾
在这一章中,我们深入了 Claude Code 的流式处理系统,理解了它是如何实现实时数据流的精密编排的:SSE 协议是流式处理的基础。Claude Code 选择 SSE 而不是 WebSocket,因为 SSE 更适合 AI 对话的单向流式响应场景。累积器和状态机是流式事件处理的核心。每个事件只包含增量信息,累积器负责将它们拼接成完整的消息。工具调用在 content_block_stop 后触发,确保 JSON 参数完整。并行工具调用可以显著减少总耗时。流式处理面临更多的错误场景。可重试的错误自动重试,不可重试的错误降级为用户可见的错误信息。节流渲染避免了频繁更新导致的性能问题。工具调用和思考过程有特殊的渲染样式。Prompt 缓存、批处理、内存管理,让流式处理在大规模场景下依然高效。这些设计你可以借鉴什么?
1. 累积器模式 —— 用状态机管理流式数据的拼接2. 节流渲染 —— 避免高频事件导致的 UI 性能问题3. 并行工具调用 —— 一次调用多个工具,减少总耗时5. Prompt 缓存 —— 利用 API 的缓存功能降低延迟和成本下一章预告
在理解了流式处理之后,下一章我们将深入 **工具系统** —— 理解 Claude Code 的 60+ 工具是如何设计和实现的、工具接口如何定义、以及工具执行的权限管理和沙箱机制。
如果你想了解 Claude 是如何"操控"你的文件系统和 Shell 的,下一章会给你答案。
 夜雨聆风
夜雨聆风