 夜雨聆风
夜雨聆风过去我们讨论 AI Agent,经常会默认一个逻辑:如果想让系统更聪明,就应该让最强的模型来当“大脑”。它负责理解任务、拆解步骤、分配工作、调用工具、检查结果;便宜一些的模型则像执行人员,负责完成具体任务。这种模式看起来合理,也符合人类团队里常见的分工方式:能力最强的人负责判断,其他人负责执行。但 Anthropic 最近提出的 Advisor Strategy,给出了一个相反的思路:不一定要让最强模型从头到尾掌控任务,而是让更快、更便宜的模型负责推进完整流程;只有当任务进入复杂、模糊、容易出错的节点时,再临时调用更强的模型作为“顾问”提供判断。这个变化表面上是模型调度方式的调整,真正值得关注的是,AI 的使用逻辑正在从“选一个最强模型”,变成“设计一个更合理的协作结构”。
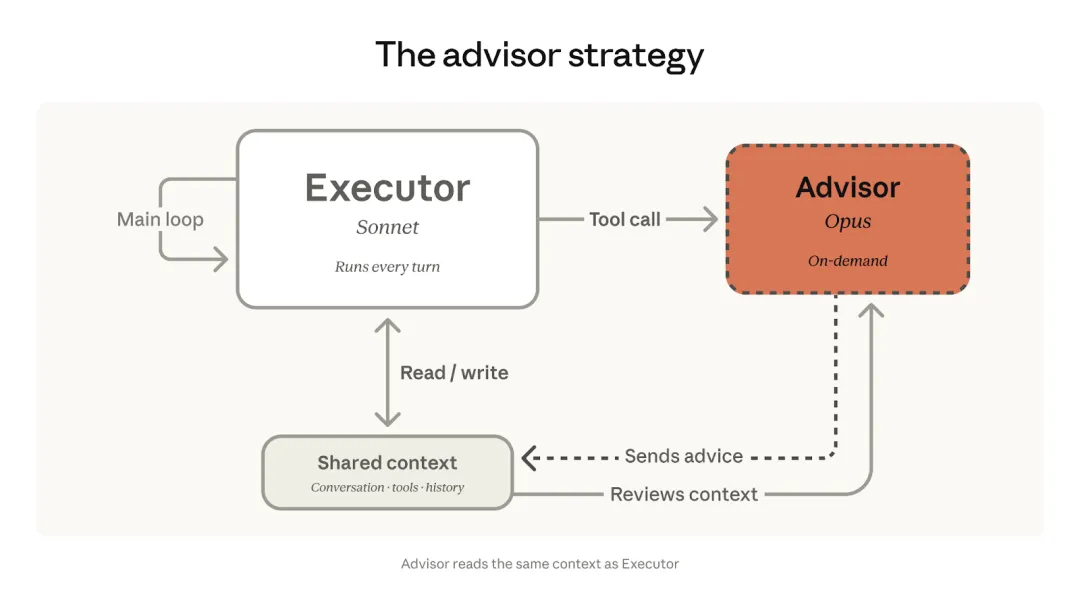
“顾问模式”的核心,不是让强模型做更多事,而是让它少做,但做在关键处。按照 Anthropic 的设计,Sonnet 或 Haiku 可以作为主要的执行模型,从头到尾负责完成任务,包括读取上下文、调用工具、生成中间结果和继续迭代。Opus 则被设置为 advisor。它不会直接接管任务,也不会直接向用户输出最终答案,而是在执行模型需要帮助时,基于当前上下文给出建议,比如提醒可能存在的问题、提出下一步计划、判断是否需要调整方向,甚至建议停止继续操作。这个模式很像真实工作里的 senior advisor:初级成员负责推进项目,高级专家不需要一直盯着每一步,但在方案判断、风险评估、复杂问题定位时介入,往往能显著提高整体质量。它强调的不是“谁最强,谁就全程负责”,而是“谁最适合在哪个节点出现”。
过去很多多模型 agent 采用的是“强模型做总指挥”的模式。最强模型先规划任务,再把不同子任务分配给其他模型或工具。这种模式并不差,但很容易变得又重又贵,因为强模型要参与大量过程性判断,哪怕很多步骤其实只是普通执行。Advisor Strategy 把更多主动权交给执行模型,让它自己推进任务,并在不确定时主动求助。很多任务本身并不难,真正决定成败的是少数关键判断点。让高级模型全程参与,会把它的能力消耗在大量普通操作里;让它只在最容易出错、最影响结果的地方出现,反而能让高级模型的价值更集中。
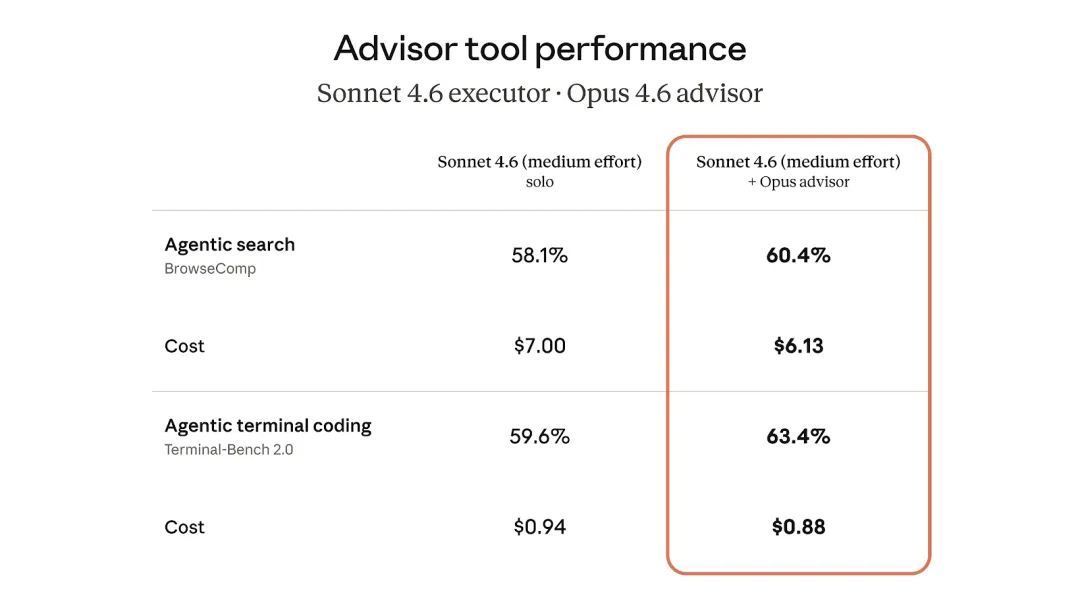
Anthropic 给出的测试结果也说明,这个策略不只是理论上好看。在 SWE-bench Multilingual 测试中,Sonnet 搭配 Opus advisor 相比 Sonnet 单独运行,表现提升了 2.7 个百分点,同时每个 agentic task 的成本降低了 11.9%。这组数据有点反直觉。我们通常会以为,质量提升意味着成本上升,但这里加入更强模型后,整体成本反而下降。原因在于 Opus 并不是全程生成大量内容,而是只在关键时刻提供相对短的建议;真正承担大量执行、工具调用和最终输出的,仍然是成本更低的模型。成本优化不一定来自“用更弱的模型”,也可能来自“不要让强模型参与低价值步骤”。

Haiku 搭配 Opus advisor 的结果,则更能说明这种模式在批量任务里的价值。在 BrowseComp 评测中,Haiku 加上 Opus advisor 后的得分比 Haiku 单独运行明显提升。虽然它仍然不如 Sonnet 单独运行,但成本低很多。很多高频任务其实都符合这种特征:大部分步骤重复、明确、可执行,只有少数地方需要高级判断。比如批量整理文档、提取用户反馈、分类研究资料、检查表格异常、生成初稿、处理客户咨询。全部交给最强模型,成本太高;全部交给便宜模型,关键判断又容易出错。更现实的方式,是让低成本模型处理大多数内容,遇到模糊、矛盾、高风险或需要推理判断的部分,再升级给强模型。这已经不像一个单独的 AI 工具,而更像企业里的分级处理机制:普通问题一线解决,复杂问题升级给 senior,关键问题交给专家。
对普通用户来说,Advisor Strategy 的意义并不只是 Claude 多了一个开发者工具。它真正提醒我们的是:使用 AI 时,不要总是把一个完整任务直接丢给模型,然后期待它一次性给出完美结果。很多人现在的使用方式仍然是:“帮我写一篇文章”“帮我做一个方案”“帮我分析这个设计”。但更高效的做法,可能是把任务拆成不同阶段,让 AI 在不同阶段承担不同角色。写文章时,可以先让 AI 快速生成主线和初稿,再让它以顾问身份检查逻辑是否松散、论点是否重复、案例是否支撑观点,最后再回到执行角色进行重写。做 UX 项目时,可以先让 AI 整理访谈资料和用户痛点,再让它作为资深 researcher 检查洞察是否过度推断,作为 product strategist 判断设计方向是否有商业价值,最后作为 portfolio reviewer 检查 case study 是否讲清楚了影响力。这里的重点不是某个工具名称,而是把 AI 从单一生成器,变成一个能在不同阶段承担不同职责的协作者。
AI coding 会更快体现这种变化。代码任务里既有大量执行型工作,也有少量高价值判断。查找文件、修改变量、补充测试、按规范重构,这些事情适合执行模型完成;架构选择、复杂 bug 定位、性能瓶颈、安全风险和依赖关系判断,则更适合让强模型介入。全部交给最强模型,成本会很高;全部交给低成本模型,又容易在关键判断上出错。Advisor Strategy 提供的是一种更平衡的方式:执行模型负责推进,顾问模型负责关键决策。未来的 coding agent,很可能不会只是一个超级模型从头到尾写代码,而是一个能自主执行、能识别不确定性、能在必要时请求高级判断的系统。
Advisor Strategy 真正值得关注的地方,不是“Claude 又加了一个新功能”,而是它把“智能调度”这件事产品化了。过去开发者如果想实现类似机制,需要自己写复杂的 orchestration logic:什么时候调用强模型,传递哪些上下文,如何避免重复调用,如何控制成本,如何把建议反馈给执行模型。现在 Anthropic 把这一部分包装成 advisor tool,让执行模型可以在需要时主动调用顾问模型。AI 竞争正在从单纯比拼模型能力,逐渐走向系统设计能力的竞争。一个 AI 工作流好不好,不只取决于模型有多强,还取决于它是否知道什么时候该自己执行,什么时候该暂停,什么时候该升级判断。
AI 的下一阶段,可能不是“一个最强模型替你完成所有事”,而是“多个智能角色组成一个小型协作系统”。在这个系统里,执行者负责推动任务,顾问负责关键判断,审查者负责质量控制,工具负责搜索、计算、文件处理和自动化,人类则负责设定目标、判断价值和做最终取舍。对开发者来说,这是更低成本、更高质量的 agent 架构;对企业来说,这是更接近真实组织流程的自动化方式;对普通用户来说,这是从“会用 AI”走向“会设计 AI 工作流”的开始。真正的问题不再只是“我应该用哪个模型”,而是“这个任务中哪些步骤需要执行,哪些步骤需要判断,哪些地方值得升级智能”。
过去一年,AI 的关键词是“更强模型”。Advisor Strategy 暗示的关键词则是“更聪明的协作”。强模型不必全程出手,便宜模型也不一定只能做简单任务。成熟的 AI 系统,会把不同层级的智能安排在合适的位置:大部分时间低成本推进,关键时刻高质量判断。对普通用户来说,这也是最值得学习的地方。不要盲目追逐新工具,也不要把所有任务都丢给同一个模型。更重要的是开始思考:AI 应该在我的工作流程中扮演什么角色?它什么时候应该执行,什么时候应该审查,什么时候应该像顾问一样,只在关键节点提醒我别走错方向?当我们开始这样使用 AI,AI 就不再只是一个回答问题的工具,而会逐渐变成参与工作系统的一部分。

